GenAI_Agents 一个专注于生成式AI Agents技术的开源项目,GenAI_Agents提供从基础到高级的教程与实现代码,帮助开发者学习并构建智能、交互式的AI系统。 Ai学习资源 2025年06月05日 81 点赞 0 评论 720 浏览
ToneLift 一个AI驱动的图文创作平台,可以帮助用户轻松创作精美的图文卡片,ToneLift支持用户上传图片并输入文案,从而生成个性化的内容。 Ai图片处理 2025年06月05日 90 点赞 0 评论 719 浏览
Loudly 一种允许用户使用人工智能技术创作原创音乐的AI音乐生成器、Ai编曲软件。用户可以选择特定的流派和所需的音乐长度,Loudly AI将在几秒钟内生成独特的曲目。 Ai语音工具 2025年06月05日 16 点赞 0 评论 719 浏览
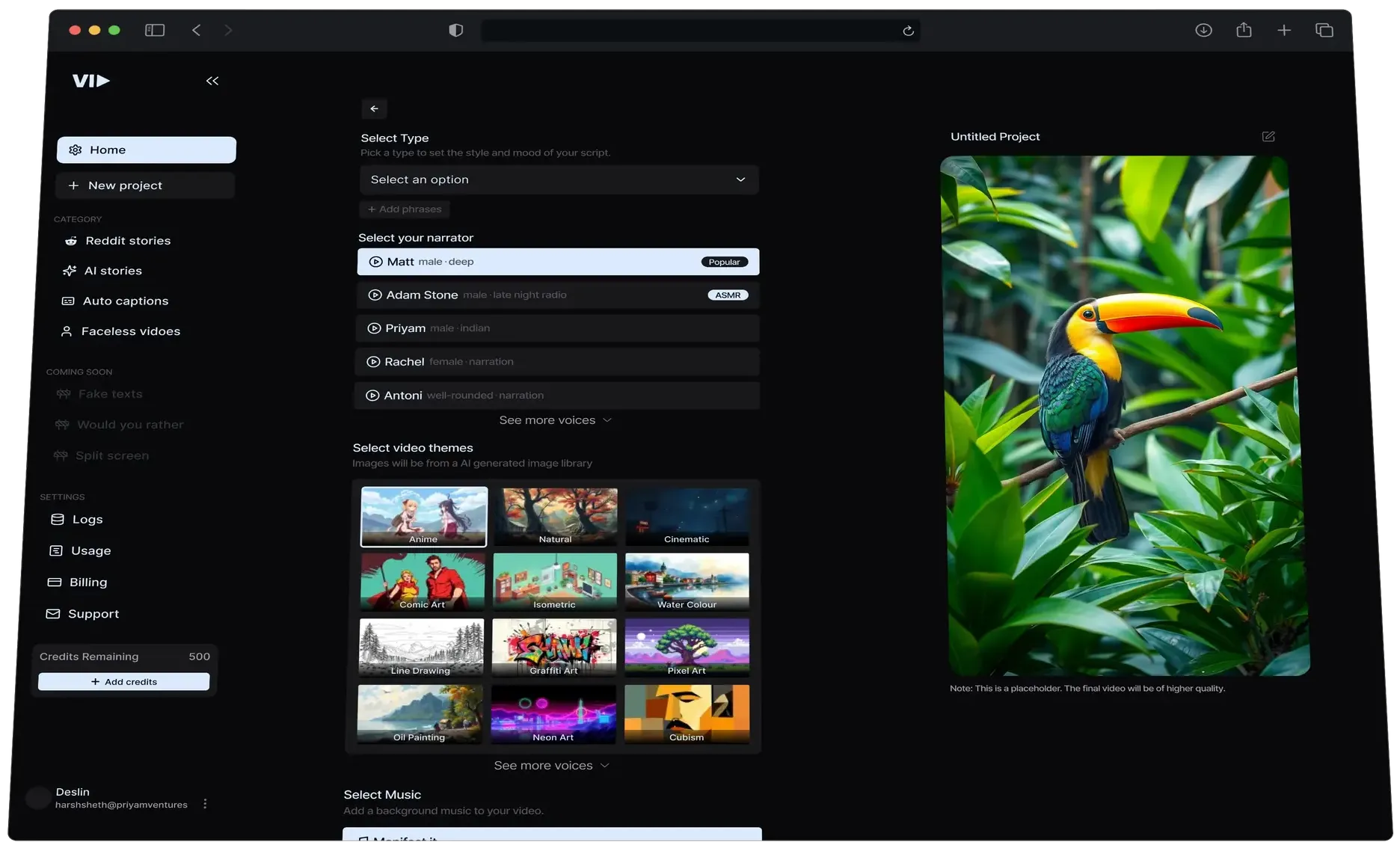
Vid.AI 一个爆款短视频生成AI工具并优化这些视频以提高在社交媒体上的传播率,提供提示生成视频、AI 脚本生成、AI 声音、短视频创作和内置的素材库。 Ai视频生成 2025年06月05日 71 点赞 0 评论 718 浏览
Video Dubbing 一款具有语音克隆和口型同步功能的AI视频翻译器,可以将视频中的语音转换成多种不同的语言,同时保持与原始视频的音频同步。 Ai语音工具 2025年06月05日 28 点赞 0 评论 718 浏览