2PR 2PR是一款基于AI技术的LinkedIn内容创作工具,能够快速生成高质量、个性化的帖子。用户可通过音频访谈或总结外部内容,将想法转化为适合平台的优质内容。工具支持多种角色使用,提升内容创作效率与个人品牌影响力,具备灵感库、多模型支持及多种订阅选项,适用于博主、求职者、B2B销售专家等群体。 AI项目与工具 2025年06月12日 68 点赞 0 评论 799 浏览
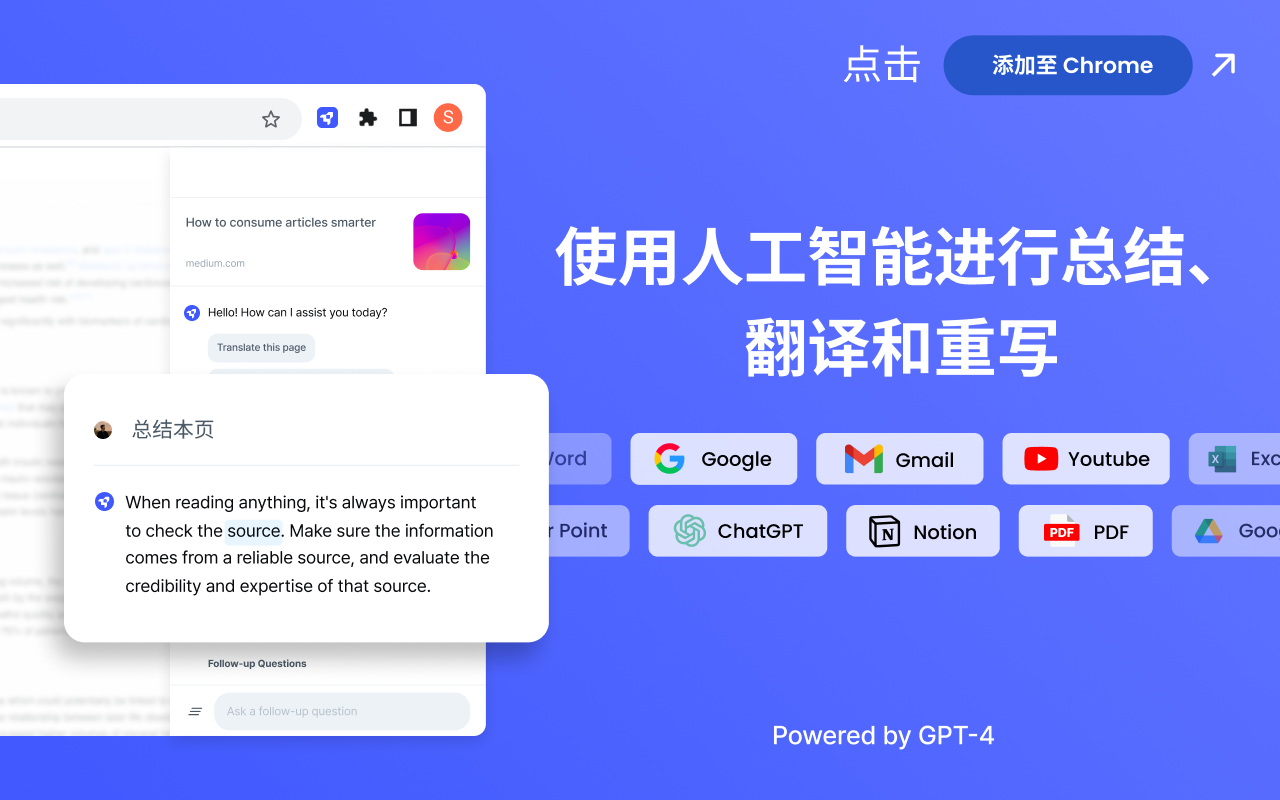
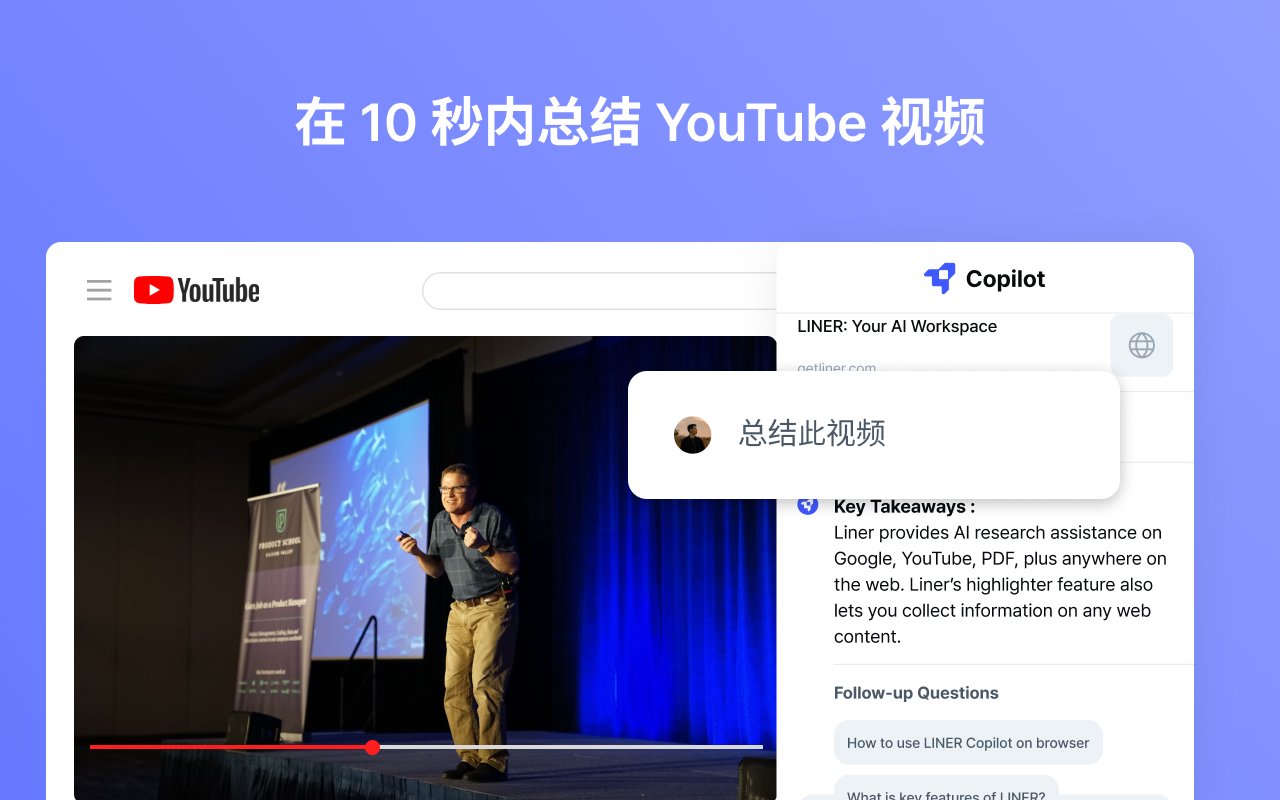
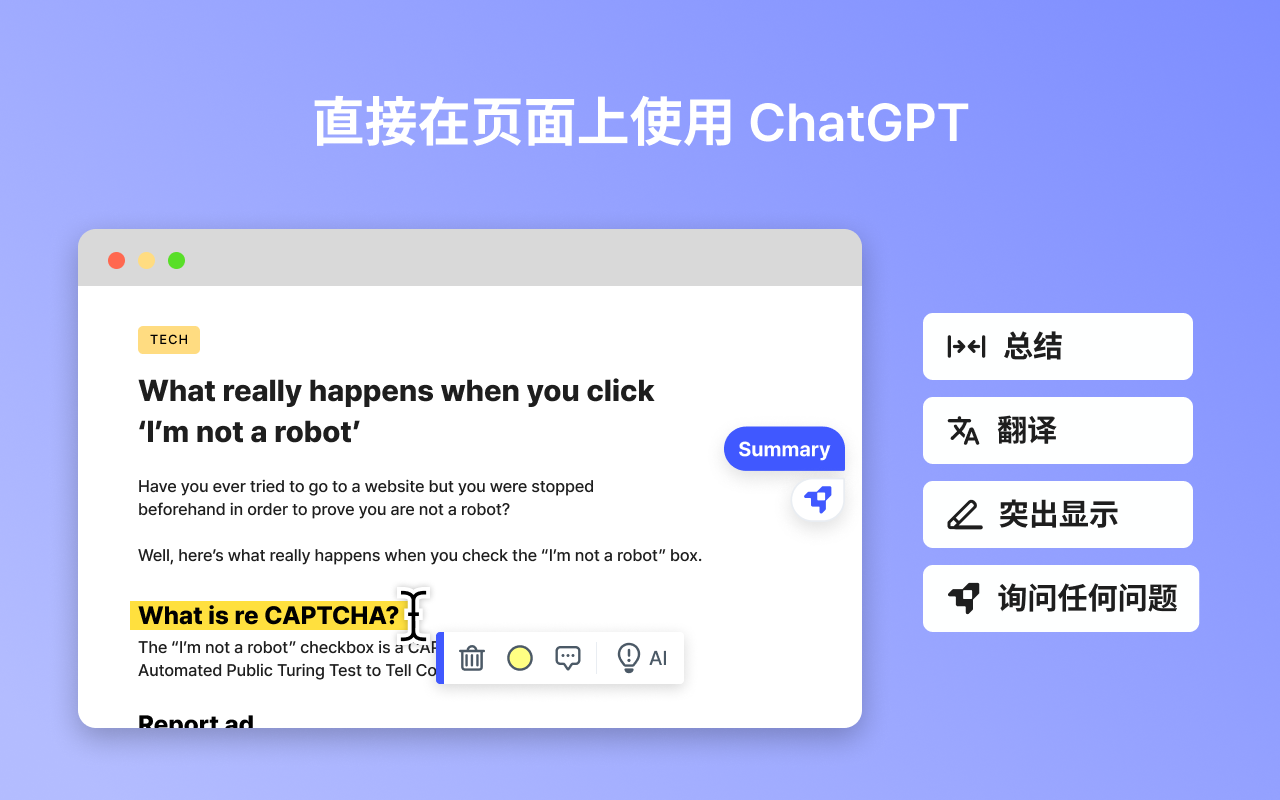
LINER AI Liner AI可以更智能、更快速地询问和学习任何事情。通过实时信息和参考资料即时获得答案。轻松消化任何网络文章和 YouTube 视频中的有用信息。 Ai办公效率 2025年06月05日 94 点赞 0 评论 799 浏览
StockGPT 一款AI驱动的搜索工具,包含所有标准普尔 500 指数和纳斯达克公司的收益发布、财务报告和其他基本信息的知识。它允许用户询问摘要、分析不同时间范围内的公司绩效、获得有关产品更新的具体答案等等。 财经投资 2025年06月05日 70 点赞 0 评论 799 浏览
MaskGCT MaskGCT是一款基于掩码生成模型与语音表征解耦编码技术的语音合成大模型,由趣丸科技与香港中文大学(深圳)联合开发。其主要功能包括声音克隆、跨语种语音合成、语音控制及高质量语音数据集支持。该模型在多个TTS基准数据集上表现优异,可快速精准地克隆音色并灵活调整语音属性,适用于多种语言,已开源并面向全球用户开放。 AI项目与工具 2025年06月12日 35 点赞 0 评论 800 浏览
Stitch Stitch是谷歌实验室推出的基于生成式AI的工具,能够将简单的英语描述或图像快速转化为用户界面(UI)设计及前端代码。它基于Gemini 2.5 Pro模型的多模态能力,支持文本、图像输入,并能识别图像生成UI组件。Stitch可生成简洁可用的前端代码,支持HTML、CSS和JavaScript,同时与Figma无缝集成,便于团队协作和优化设计。其功能包括文本生成设计、图像生成设计、代码生成与优 AI项目与工具 2025年06月11日 91 点赞 0 评论 800 浏览
Pollinations.AI Pollinations.AI是一个开源AI内容生成平台,提供图像生成、文本生成、音频转换及视觉分析等功能。用户无需注册即可使用,支持多种模型和参数配置,适合开发者和创作者快速集成与应用。平台还提供浏览器开发环境,简化了使用流程,提升了效率。 AI项目与工具 2025年06月11日 50 点赞 0 评论 801 浏览
Websim Websim是一款基于AI技术的网页开发工具,用户只需输入文本提示,即可快速生成网站或应用程序。它支持智能界面设计、自动代码生成及项目托管,适用于个人创意实现、企业开发、教育及市场营销等多个场景。无需编程基础,大幅降低开发门槛,提高项目构建效率。 AI项目与工具 2025年06月12日 69 点赞 0 评论 801 浏览