人工智能





Branchbob.Ai
Branchbob 是一个由 AI 驱动的在线商城生成器,可让您在几分钟内创建一个功能齐全、搜索引擎优化的商城。


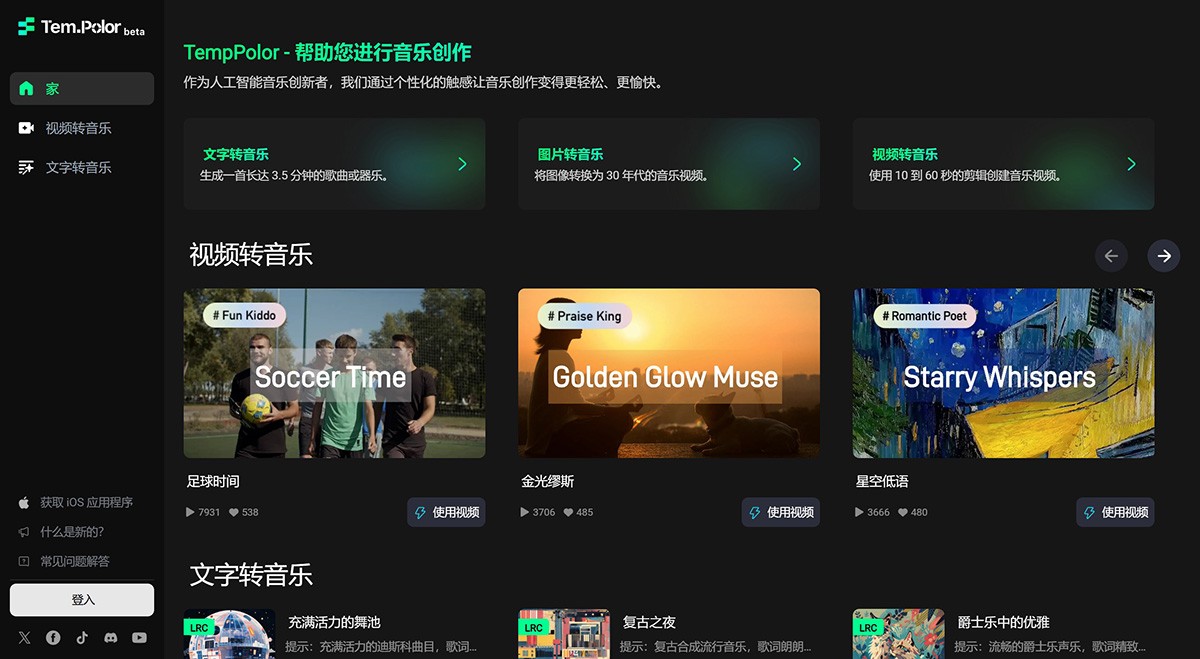
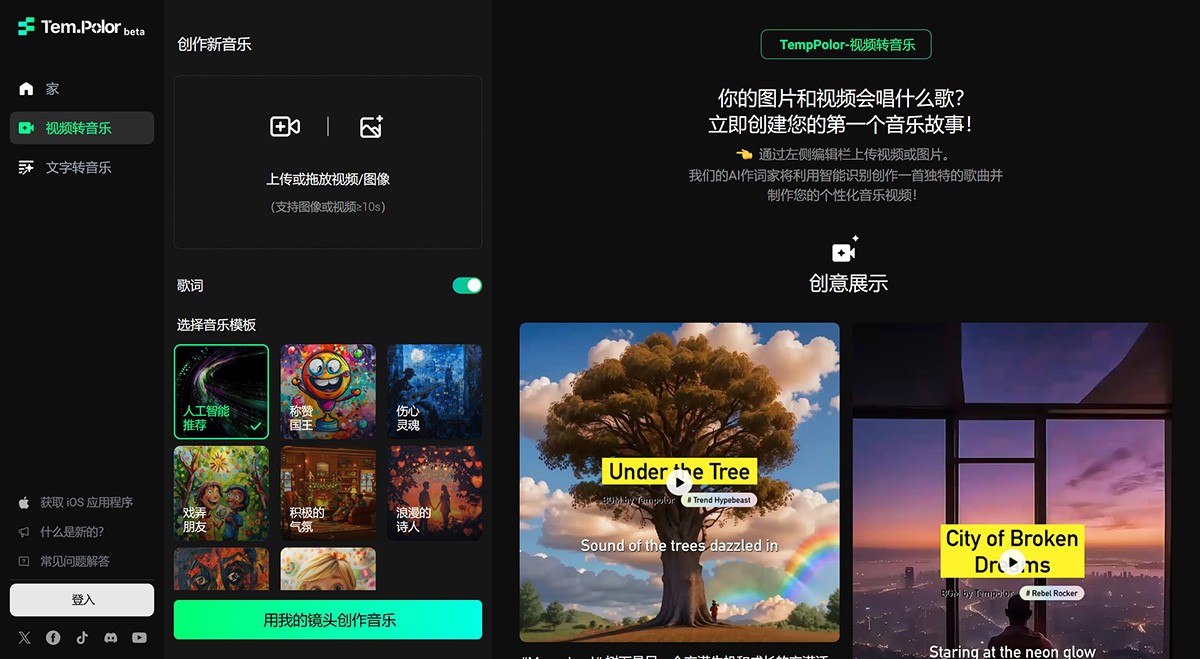

VenturusAI
VenturusAI 基于GPT为您的商业理念提供建议的工具。无论您是想开始创业、推出新产品还是改进现有产品,VenturusAI 都可以帮助您进行全面的业务分析、目标受众识别、定制业务策略、营销和品牌指导以及创新理念和机会。

