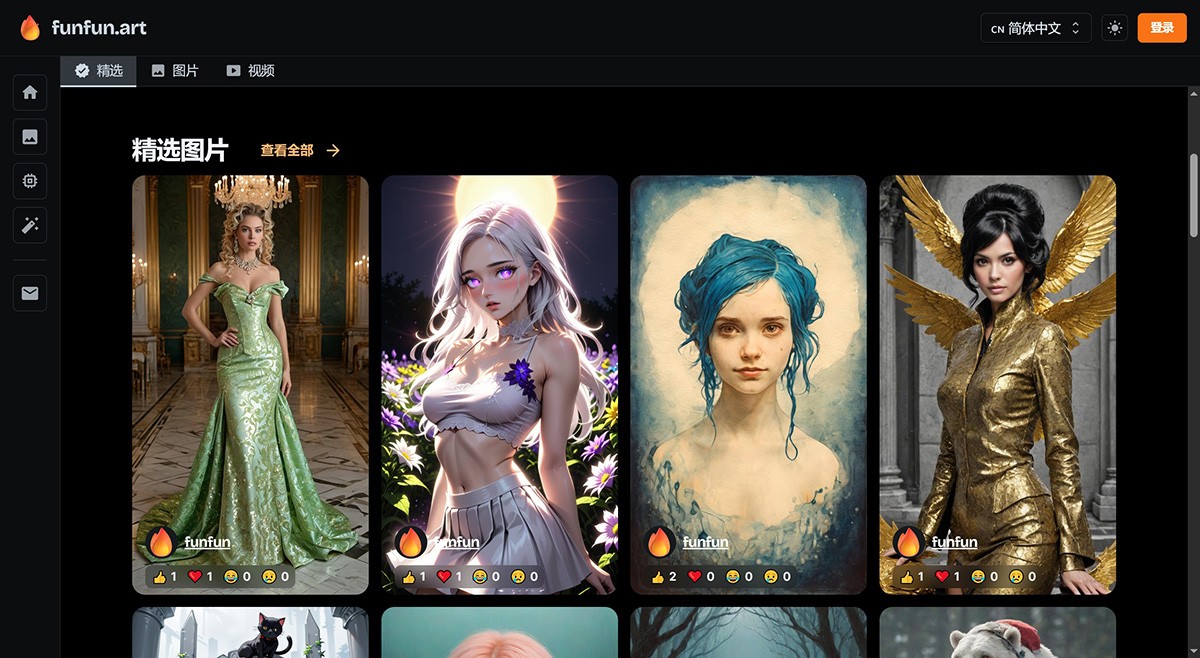
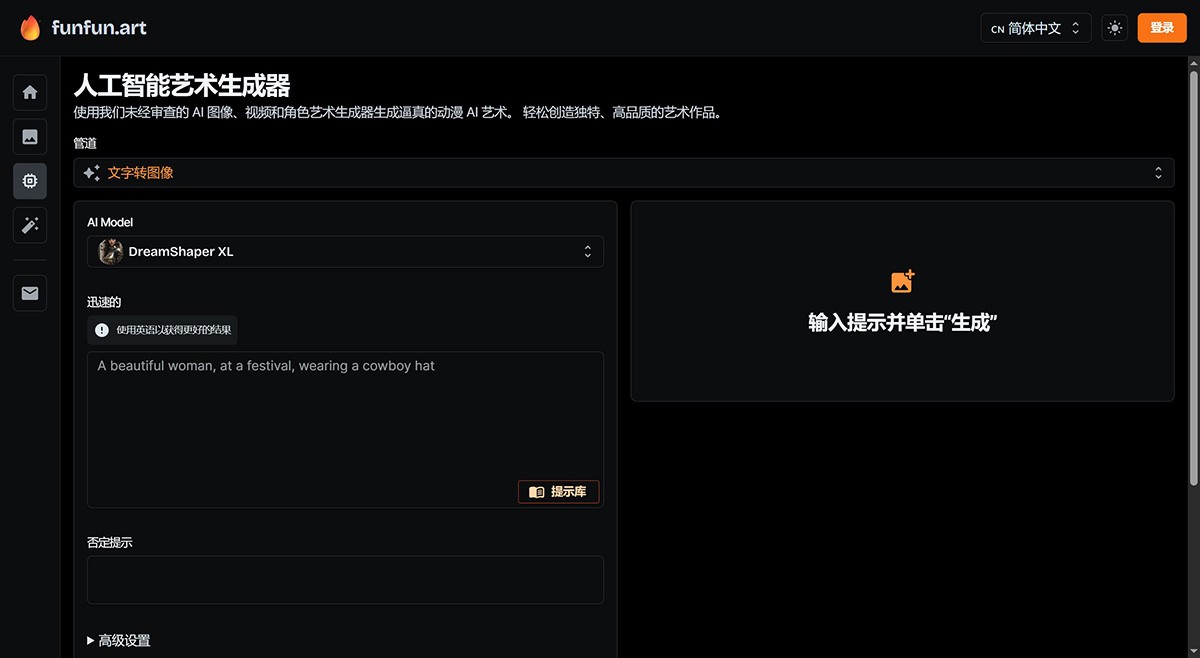
FunFun Art 一个利用人工智能技术将用户的创意概念转化为视觉上吸引人的图片和视频。用户只需在平台上输入描述性关键词,就能获得多种艺术风格的生成l图像和视频作品。 Ai视频生成 2025年06月05日 79 点赞 0 评论 487 浏览
HandRefiner 解决AI图像生成中手部畸形的问题 目前的图像生成模型,再生成图像方面已经非常出色,但在生成人类手部的图像时却常常出现问题,比如手指数量不对或者手形怪异。 Ai开源项目 2025年06月05日 27 点赞 0 评论 487 浏览
Sivi AI 一个可帮助您在几分钟内创建令人惊叹的视觉设计平台。您可以使用 Sivi AI 将您的文本转换为用于各种目的的图形,例如横幅、社交帖子、广告等。 Ai图片处理 2025年06月05日 36 点赞 0 评论 488 浏览
BAGEL BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数,采用混合变换器专家架构(MoT),通过两个独立编码器捕捉图像的像素级和语义级特征。它能够进行图像与文本融合理解、视频内容理解、文本到图像生成、图像编辑与修改、视频帧预测、三维场景理解与操作、世界导航以及跨模态检索等任务。BAGEL在多模态理解基准测试中表现优异,生成质量接近SD3,并适用于内容创作、三维场景生成、可视化学习和创意广告生成等 AI项目与工具 2025年06月11日 92 点赞 0 评论 491 浏览
DCEdit DCEdit是一款基于双层控制机制的图像编辑工具,结合精确语义定位策略与视觉、文本自注意力优化,提升图像编辑的准确性和可控性。无需额外训练即可应用于现有扩散模型,支持复杂场景下的精细编辑任务,如对象替换、颜色调整等,适用于广告、影视、社交媒体等多个领域。 AI项目与工具 2025年06月12日 15 点赞 0 评论 493 浏览
EverArt EverArt是一款AI图像生成平台,支持用户通过上传图片训练自定义模型,生成风格一致的图像,适用于角色设计、艺术创作及多种应用场景。其功能包括多模型生成、姿势转换、魔法提示、图像放大和团队协作,提升创作效率与灵活性。 AI项目与工具 2025年06月12日 74 点赞 0 评论 494 浏览
Yodayo AI | 文本生成动漫图片 Yodayo是一个AI文本生成动漫图片工具,是一款先进的人工智能系统,它可以根据你输入的文字或图片,自动生成出免费、高质量的动漫风格的画面。 Ai绘画生成 2025年06月05日 94 点赞 0 评论 495 浏览
DeepMesh DeepMesh是由清华大学和南洋理工大学研发的3D网格生成框架,结合强化学习与自回归变换器技术,实现高质量、高精度的3D模型生成。支持点云和图像条件输入,具备高效的预训练策略与人类偏好对齐机制,适用于虚拟环境、角色动画、医学模拟及工业设计等多个领域。 AI项目与工具 2025年06月12日 98 点赞 0 评论 496 浏览