CustomVideoX CustomVideoX是一种基于视频扩散变换器的个性化视频生成框架,能够根据参考图像和文本描述生成高质量视频。其核心技术包括3D参考注意力机制、时间感知注意力偏差(TAB)和实体区域感知增强(ERAE),有效提升视频的时间连贯性和语义一致性。支持多种应用场景,如艺术设计、广告营销、影视制作等,具备高效、精准和可扩展的特点。 AI项目与工具 2025年06月12日 98 点赞 0 评论 594 浏览
MMSearch MMSearch 是一款用于评估大型多模态模型(LMMs)搜索能力的基准测试工具,包含 MMSearch-Engine 框架和 MMSearch 测试集。其核心功能包括问题重构、网页排序和答案总结,通过多模态搜索能力评估提升 LMMs 的性能。实验结果显示 GPT-4o 在该测试中表现优异,且增加计算量比扩大模型规模更具优势。 AI项目与工具 2025年06月12日 44 点赞 0 评论 593 浏览
MOFA MOFA-Video是由腾讯AI实验室和东京大学研究人员开发的开源图像生成视频模型。该工具通过生成运动场适配器对图像进行动画处理,能够通过稀疏控制信号(如手动轨迹、面部关键点序列或音频)实现对视频生成过程中动作的精准控制。MOFA-Video支持零样本学习,能够将多种控制信号组合使用,生成复杂的动画效果,并能生成较长的视频片段。 --- AI项目与工具 2025年06月12日 22 点赞 0 评论 593 浏览
Gen Gen-3 Alpha是一款由Runway公司研发的AI视频生成模型,能够生成长达10秒的高清视频片段,支持文本到视频、图像到视频的转换,并具备精细的时间控制及多种高级控制模式。其特点在于生成逼真的人物角色、复杂的动作和表情,提供运动画笔、高级相机控制和导演模式等高级控制工具,确保内容的安全性和合规性。 AI项目与工具 2025年06月12日 93 点赞 0 评论 593 浏览
WorldSense WorldSense是由小红书与上海交通大学联合开发的多模态基准测试工具,用于评估大型语言模型在现实场景中对视频、音频和文本的综合理解能力。该平台包含1662个同步视频、3172个问答对,覆盖8大领域及26类认知任务,强调音频与视频信息的紧密耦合。所有数据经专家标注并多重验证,确保准确性。适用于自动驾驶、智能教育、监控、客服及内容创作等多个领域,推动AI模型在多模态场景下的性能提升。 AI项目与工具 2025年06月12日 61 点赞 0 评论 592 浏览
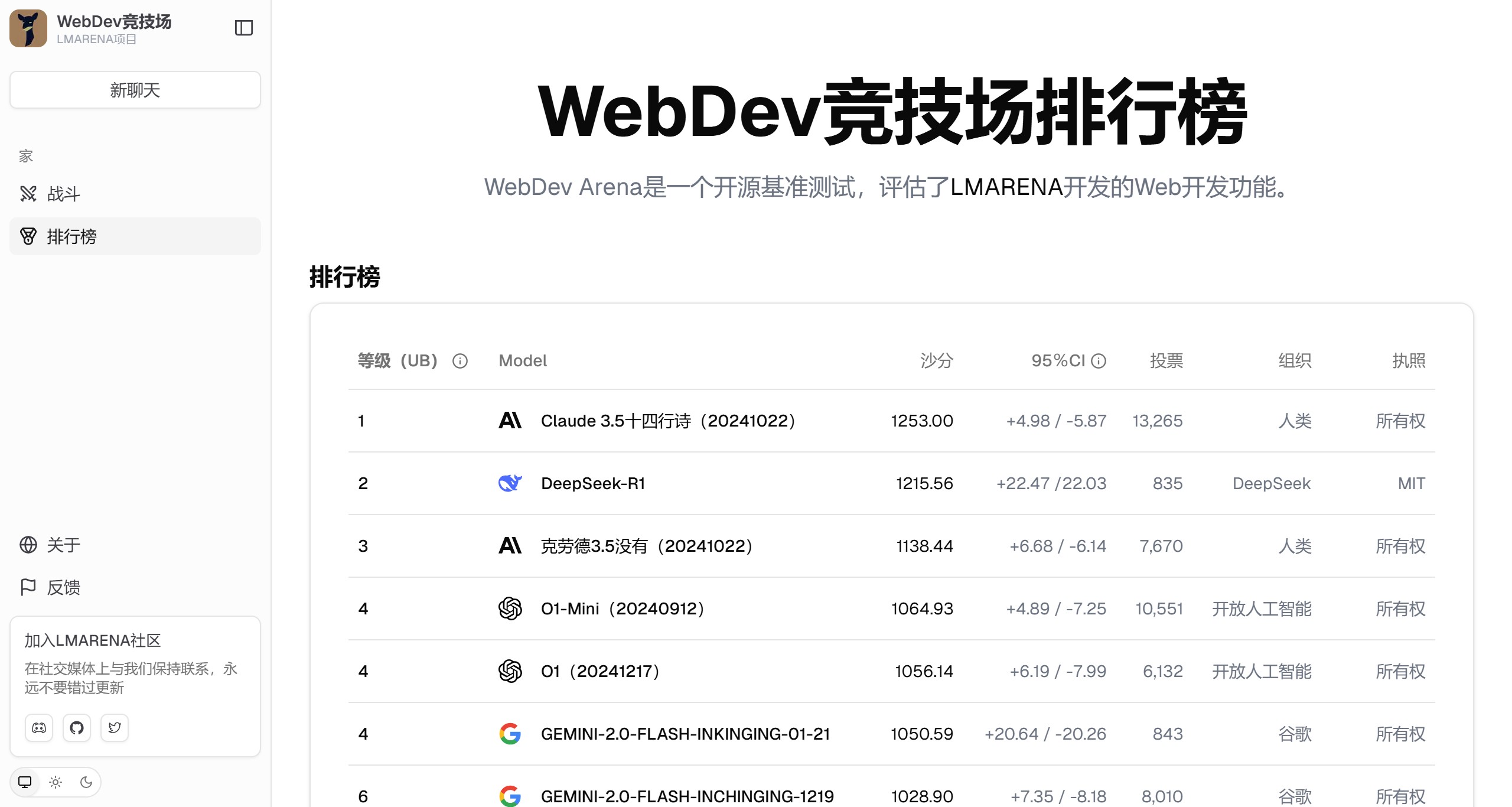
LMArena AI 前身为lmsys.org,是一个专注于众包AI基准测试的开放平台,用户可以在此平台上免费与AI聊天并进行投票,比较和测试不同的AI聊天机器人。 Ai平台模型 2025年06月05日 13 点赞 0 评论 592 浏览
GO GO-1是智元机器人推出的首个通用具身基座模型,采用ViLLA架构,结合多模态大模型与混合专家系统,具备场景感知、动作理解和精细执行能力。支持小样本快速泛化、跨本体部署与持续进化,广泛应用于零售、制造、家庭及科研等领域,推动具身智能技术发展。 AI项目与工具 2025年06月12日 74 点赞 0 评论 591 浏览
POINTS 1.5 POINTS 1.5 是腾讯微信开发的多模态大模型,基于LLaVA架构设计,包含视觉编码器、投影器和大型语言模型。它在复杂场景OCR、推理、关键信息提取、数学问题解析及图片翻译等方面表现突出,适用于票据识别、自动客服、新闻摘要、学术论文处理、旅游翻译和在线教育等多个领域。该模型通过高效的数据处理和特征融合技术,实现了跨模态任务的精准处理与高效输出。 AI项目与工具 2025年06月12日 14 点赞 0 评论 591 浏览
Transfusion Transfusion是由Meta公司开发的多模态AI模型,能够同时生成文本和图像,并支持图像编辑功能。该模型通过结合语言模型的下一个token预测和扩散模型,在单一变换器架构上处理混合模态数据。Transfusion在预训练阶段利用了大量的文本和图像数据,表现出强大的扩展性和优异的性能。其主要功能包括多模态生成、混合模态序列训练、高效的注意力机制、模态特定编码、图像压缩、高质量图像生成、文本生成 AI项目与工具 2025年06月12日 26 点赞 0 评论 591 浏览