商汤如影SenseAvatar 商汤如影作为商汤科技旗下的产品,展现了其在人工智能领域的深厚实力和创新能力。通过提供多功能的大模型服务,商汤如影有助于推动各行业的智能化升级,实现降本增效,促进创新。 创作工具 2026年06月23日 0 点赞 0 评论 631 浏览
Mistral Medium 3 Mistral Medium 3是Mistral AI推出的一款多模态语言模型,兼具高性能与低成本优势,适用于企业级应用。支持混合云部署、定制化微调及多模态任务处理,可广泛应用于编程辅助、智能客服、数据分析及知识管理等领域,具备良好的扩展性和系统集成能力。 AI项目与工具 2025年06月11日 76 点赞 0 评论 630 浏览
xLAM xLAM 是 Salesforce 开源的一款大型语言模型,专为功能调用任务设计。该模型具备多语言支持、预训练模型、迁移学习、自然语言处理等主要功能,并基于 Transformer 架构实现。它在多个基准测试中表现出色,适用于自动化任务、模板共享、插件开发和教育等多个应用场景。 AI项目与工具 2025年06月12日 55 点赞 0 评论 629 浏览
StyleDrop StyleDrop 是一个强大的文本到图像生成工具,它通过少量参数的微调和迭代训练,能够以极高的灵活性和准确性捕捉并再现各种风格。 Ai绘画生成 2026年06月23日 0 点赞 0 评论 628 浏览
DDColor图像上色 一个为黑白图像上色的魔搭模型,通过双解码器实现逼真的图像着色,输入一张黑白图像,实现端到端的全图上色,返回上色处理后的彩色图像。 Ai开源项目 2025年06月05日 38 点赞 0 评论 628 浏览
瑞智病理大模型 瑞智病理大模型(RuiPath)是由上海交通大学医学院附属瑞金医院与华为联合开发的国产多模态病理诊断系统,覆盖中国90%的常见癌种及部分罕见病。通过整合图像、文本等多源数据,实现高效、精准的辅助诊断,支持交互式审核流程,提升诊断效率与准确性。模型基于深度学习与华为DCS AI平台,适用于临床诊断、基层医疗、医学教育等多个场景,推动病理诊断智能化发展。 AI项目与工具 2025年06月12日 95 点赞 0 评论 628 浏览
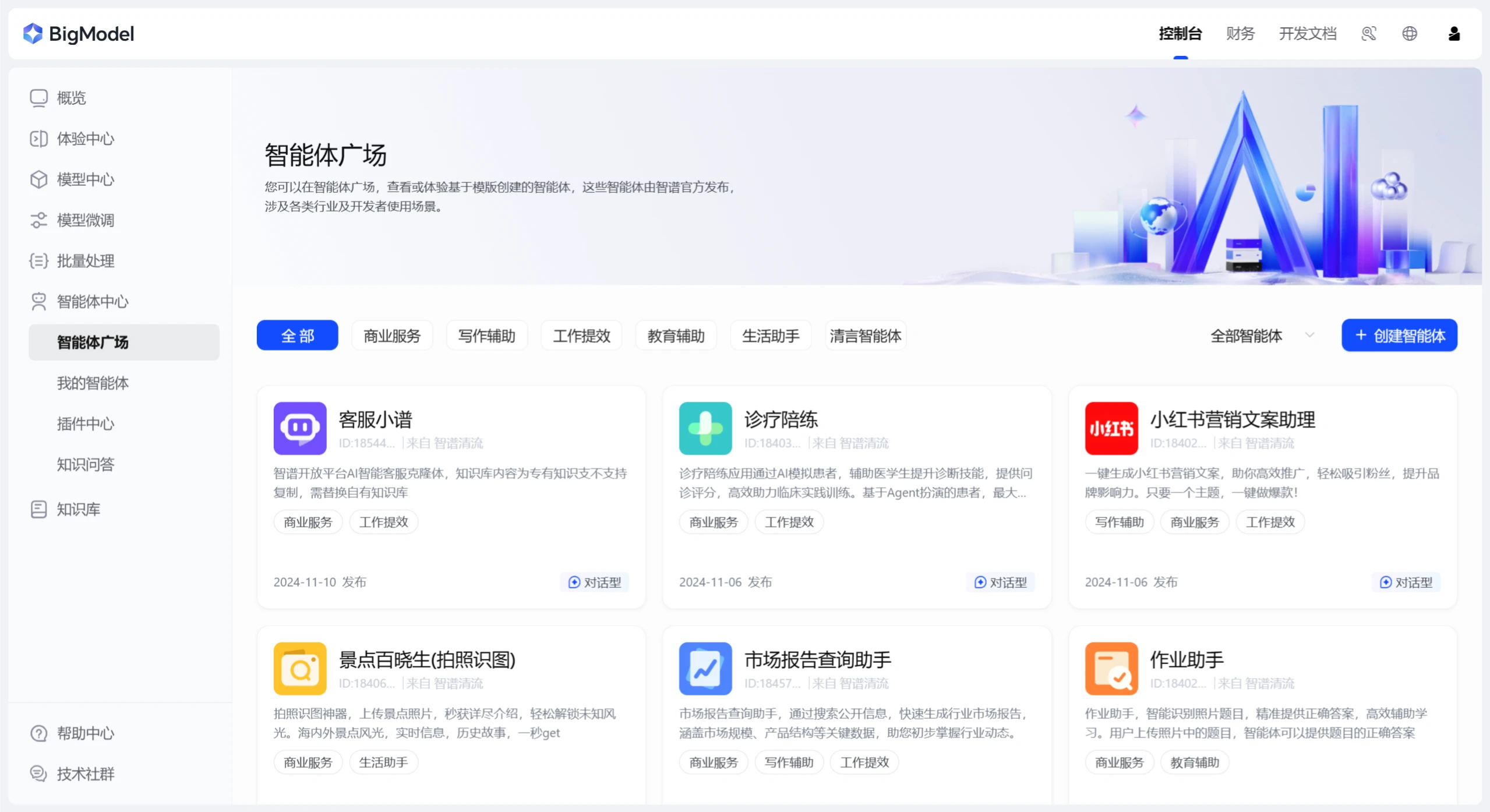
智谱清流 智谱清流是智谱AI推出的企业级AI智能体开发平台,旨在帮助企业快速构建和部署AI应用,实现业务流程的智能化升级。该平台基于智谱全模型矩阵,提供智能体构建、工作流 Ai平台模型 2025年06月05日 77 点赞 0 评论 628 浏览
MV MV-Adapter是一款基于文本到图像扩散模型的多视图一致图像生成工具,通过创新的注意力机制和条件编码器,实现了高分辨率多视角图像生成。其核心功能包括多视图图像生成、适配定制模型、3D模型重建以及高质量3D贴图生成,适用于2D/3D内容创作、虚拟现实、自动驾驶等多个领域。 AI项目与工具 2025年06月12日 23 点赞 0 评论 627 浏览
Eluna.ai 一个由 AI 驱动的文生图平台。借助 eluna.ai,您可以利用大量功能将简单的文本转换为引人入胜的视觉设计。无论您的目标是生成详细的图像、尝试无限缩放、从图像中删除背景,还是放大现有图像,eluna.ai 都能满足您的需求。 Ai绘画生成 2025年06月05日 94 点赞 0 评论 627 浏览