模型


EasyControl
EasyControl是基于扩散变换器(DiT)架构的高效控制框架,采用轻量级LoRA模块实现多条件控制,支持图像生成、风格转换、动画制作等任务。其具备位置感知训练范式和因果注意力机制,优化计算效率,提升生成质量与灵活性,适用于多种图像处理场景。

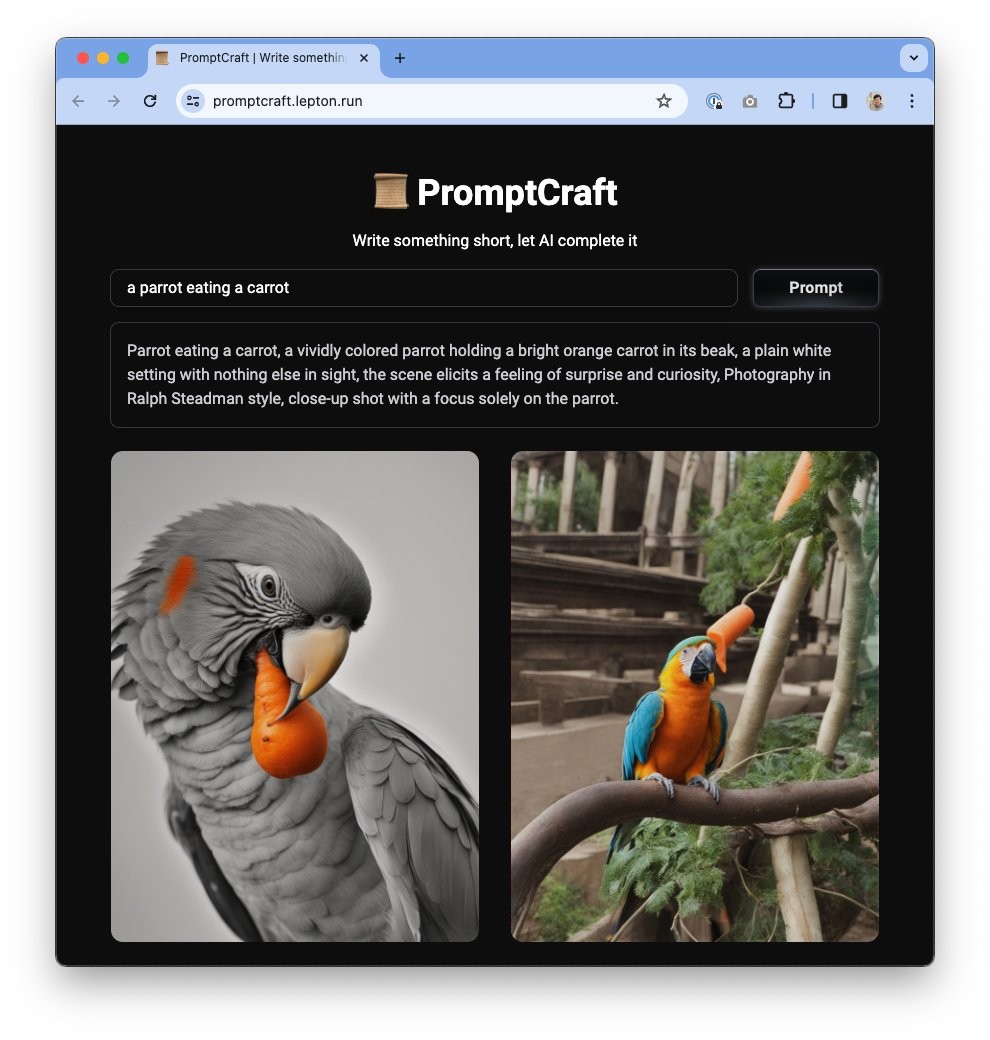
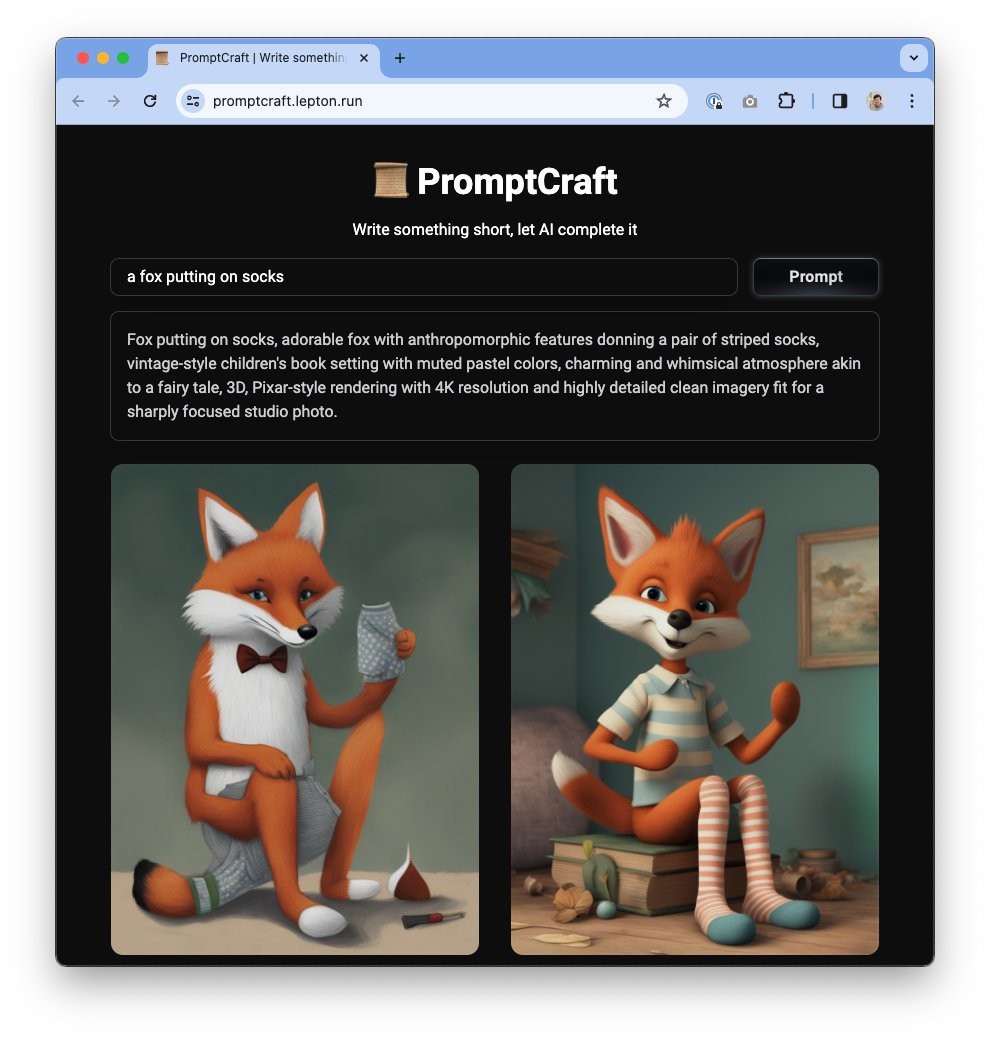

SketchVideo
SketchVideo是一款基于草图和文本提示的视频生成与编辑框架,由多所高校与企业联合研发。它利用DiT模型和草图控制网络,实现对视频内容的精细控制,支持动态调整与细节保留。该工具适用于多种场景,如影视制作、教育、游戏开发等,具备高效生成与高质量输出能力。

月之暗面Moonshot AI
一家专注于人工智能技术的公司,由杨植麟于2023年3月创立。公司致力于开发大型AI模型,其核心产品是Kimi智能助手。





VisoMaster
VisoMaster 是一款基于 AI 的面部编辑与换脸工具,支持图片、视频及直播场景,能生成自然逼真的换脸效果。采用 GPU 加速与自定义模型功能,适用于影视、广告、视频创作等领域。核心技术包括深度学习与 GANs,实现高精度面部特征提取与图像合成,支持实时预览与参数调整,提升用户体验与效率。
