Awesome Chinese LLM 整理了开源的中文大语言模型(LLM),主要关注规模较小、可私有化部署且训练成本较低的模型,目前已收录了100多个相关资源。 Ai学习资源 2025年06月05日 44 点赞 0 评论 572 浏览
Patchwork Patchwork是一款基于AI技术的多人协作工具,专为虚拟世界构建设计。支持无限画布上的实时协作,用户可通过文本提示生成角色、地点及事件等元素,并可保存和分享成果。其功能包括生成图像、碎片操作、工具箱使用以及权限管理等,广泛应用于小说创作、游戏开发、电影制作和教育等领域。 AI项目与工具 2025年06月12日 55 点赞 0 评论 570 浏览
PROMPT HUNT Prompt Hunt 是一款基于AI技术的艺术创作平台,整合了Stable Diffusion、DALL-E和自有Chroma模型等先进工具,支持用户通过简单的操作生成高质量的艺术图像。平台提供丰富的样式库、主题模板以及参数调节功能,便于用户个性化定制作品。此外,Prompt Hunt还打造了一个活跃的社区,鼓励用户分享创意、交流经验,推动AI艺术的普及与发展。 AI项目与工具 2025年06月12日 69 点赞 0 评论 566 浏览
NightCafe Studio NightCafe Creator是一款AI艺术生成器应用程序,可以让用户使用各种技术创建令人惊叹的AI生成艺术品。它还提供了一个平台供AI艺术爱好者互动社区。 Ai绘画生成 2025年06月05日 59 点赞 0 评论 565 浏览
Learn Prompting提示工程课程! Learn Prompting 是一个免费的关于与人工智能通信的免费开源课程,即学习如何给AI下达指令!即怎样与人工智能沟通,让AI来协助我们来完成我们想让它做的事情! Ai提示指令 2025年06月05日 18 点赞 0 评论 564 浏览
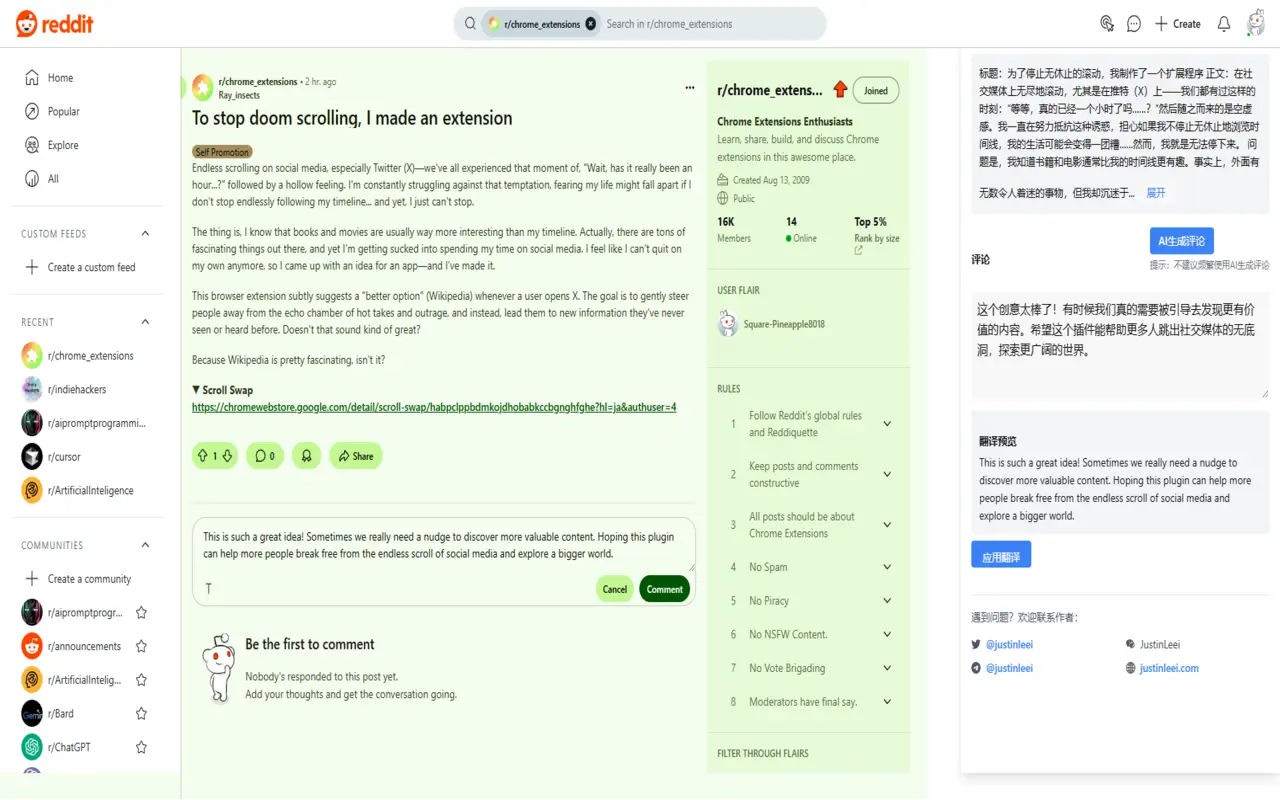
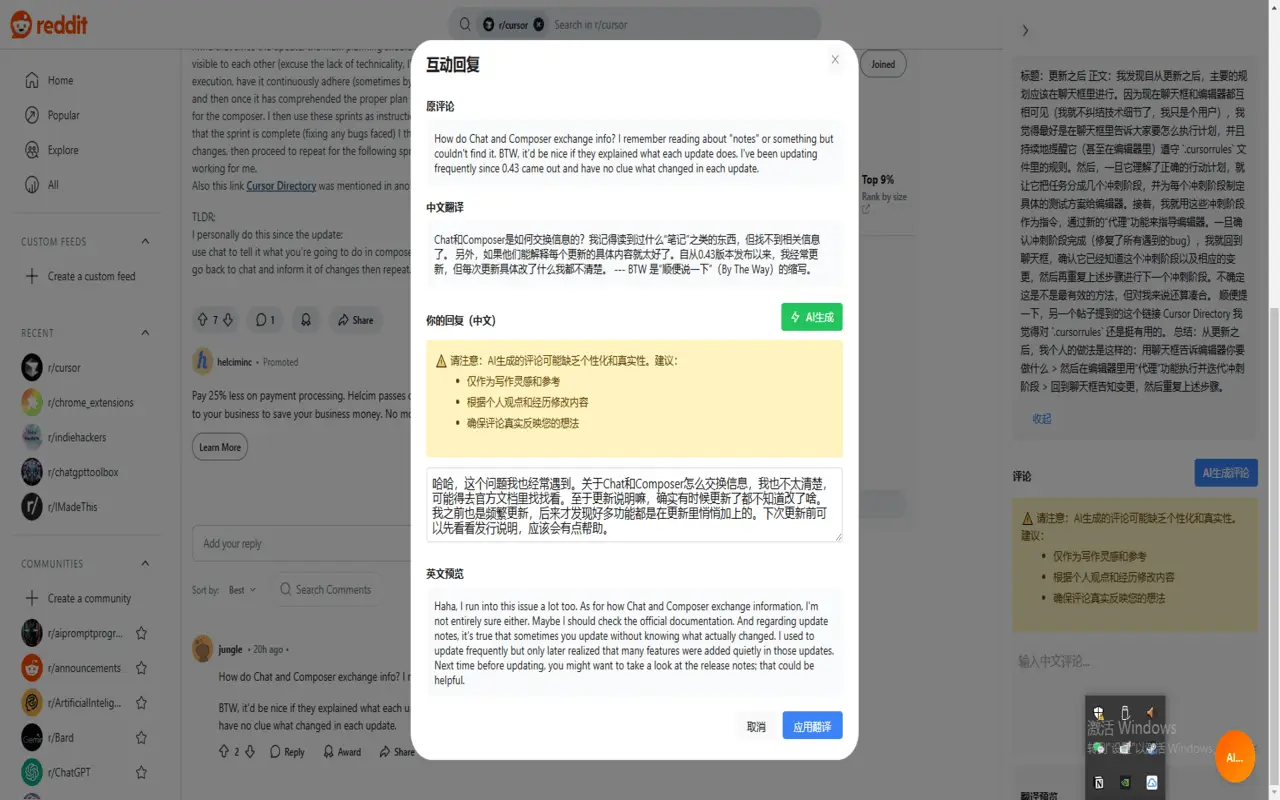
Reddit翻译助手 突破语言障碍,Reddit翻译助手让你可以用中文在Reddit上畅聊,无缝翻译帖子内容,,用中文写评论,自动转英文发布,支持一键翻译评论区。 Ai办公效率 2025年06月05日 83 点赞 0 评论 561 浏览
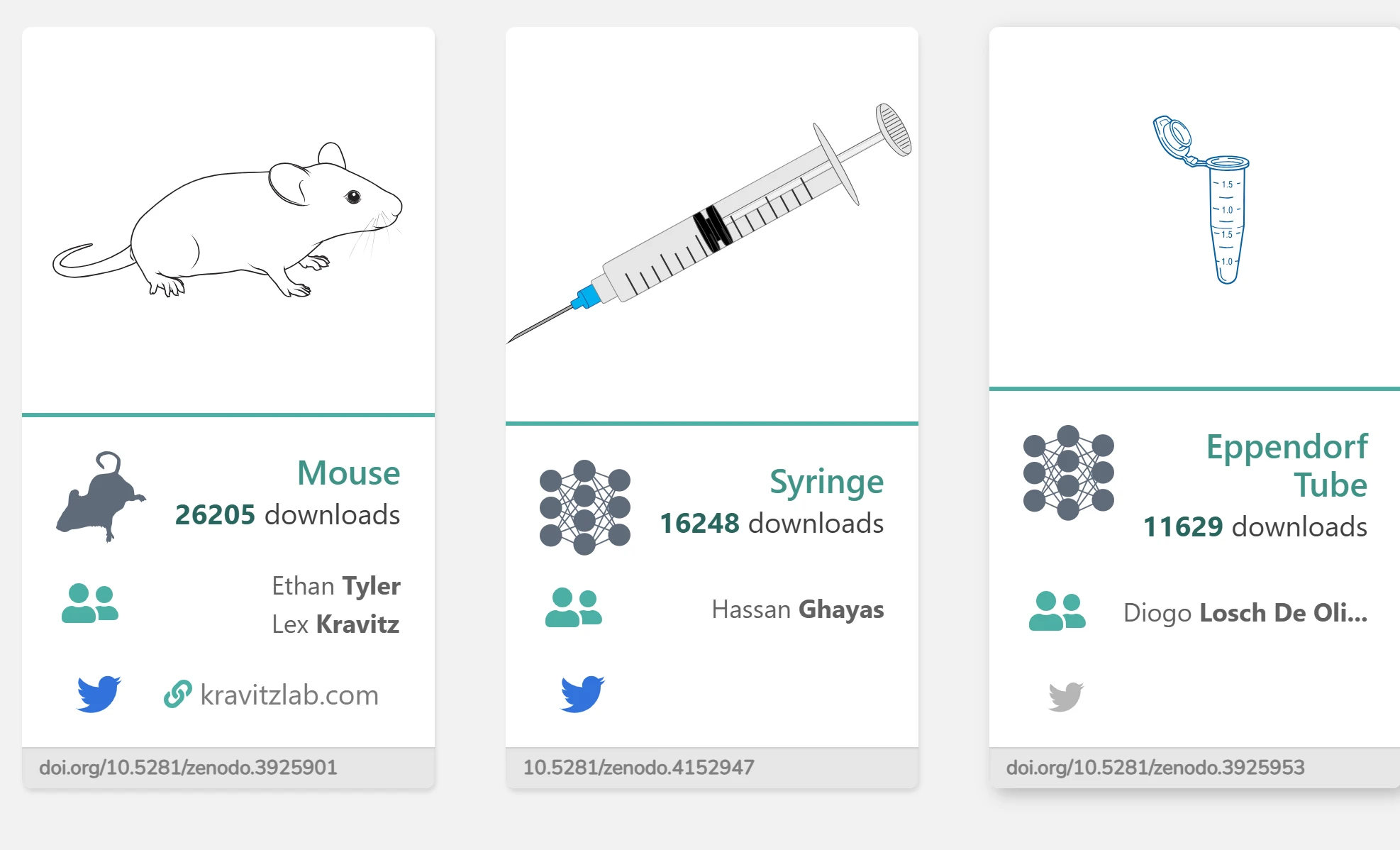
SciDraw.io 一个专为科研人员设计的高质量矢量图素材库,它提供了丰富的生命科学相关图像资源,包括动物模型、细胞、器官、科学设备等,特别适合需要制作科研论文、学术报告或海报的用户。 免商图片 2025年06月05日 72 点赞 0 评论 561 浏览
ima知识号 IMA知识号是腾讯推出的用于知识库创作与管理的平台,支持知识发布、数据分析及云存储等功能。用户可通过该平台创建、编辑和管理知识库,并利用数据洞察优化内容。适用于企业、教育、社区和个人知识分享等场景,提升信息管理效率和内容质量。 AI项目与工具 2025年06月12日 29 点赞 0 评论 558 浏览
Compo AI Compo AI,它是一个web组件驱动的平台,可让您通过一行文本创建、设计、管理和开发您的页眉、页脚、按钮、表单等组件。 Ai编程建站 2025年06月05日 59 点赞 0 评论 557 浏览