面部表情



ComfyUI Portrait Master简体中文版
ComfyUI Portrait Master 肖像大师简体中文版。超详细参数设置!再也不用为不会写人像提示词发愁!重新优化为ison列表更方便自定义和扩展。

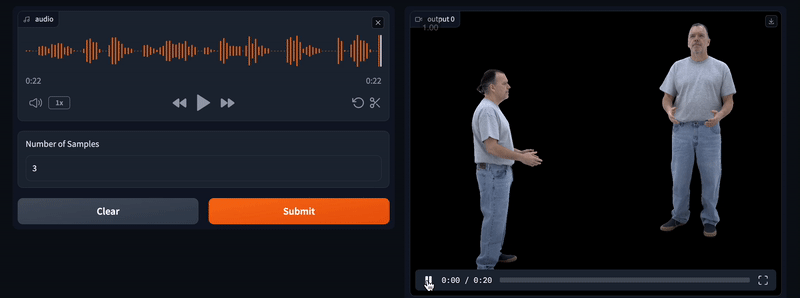
MimicPhoto
MimicPhoto 是一款基于 AI 的图像处理工具,支持面部表情优化、动态视频生成、背景替换及智能补光等功能。用户可轻松调整笑容、眼神等细节,将静态照片转化为生动的动态视频,提升人像质量和视觉表现力,适用于摄影、电商、社交媒体及创意制作等多种场景。





