Meta Movie Gen Meta公司推出的能够通过简单的文本输入生成视频和声音的AI工具。MetaMovieGen可以创建长达16秒的逼真视频片段,并支持将图像转化为视频,添加音乐和音效。 Ai视频生成 2025年06月05日 86 点赞 0 评论 562 浏览
ImageBind ImageBind是由Meta公司开发的开源多模态AI模型,能够整合文本、音频、视觉、温度和运动数据等多种模态的信息,并将其统一到一个嵌入空间中。该模型通过图像模态实现其他模态数据的隐式对齐,支持跨模态检索和零样本学习。它在增强现实(AR)、虚拟现实(VR)、内容推荐系统、自动标注和元数据生成等领域有广泛应用。 AI项目与工具 2025年06月12日 16 点赞 0 评论 526 浏览
MetaVoice Studio MetaVoice Studio允许用户录制自己的声音或上传文件来创建自定义语音剪辑。它提供了一个免费的计划,有6个声音,30秒的剪辑长度,和一个非商业许可。付费计划包括8个声音、10分钟... 创作工具 2026年06月21日 0 点赞 0 评论 522 浏览
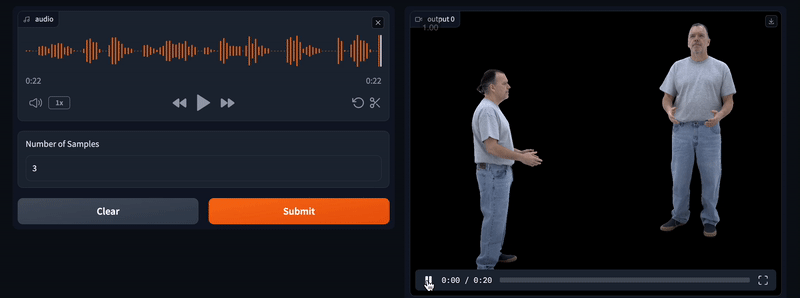
Audio2Photoreal 从音频生成全身逼真的虚拟人物形象。它可以从多人对话中语音中生成与对话相对应的逼真面部表情、完整身体和手势动作。 Ai开源项目 2025年06月05日 77 点赞 0 评论 516 浏览
Flex3D Flex3D是一款由Meta和牛津大学联合研发的两阶段3D生成框架,通过多视图扩散模型和视图筛选机制生成高质量3D模型,支持从文本、单张图片或稀疏视图生成逼真的3D内容。其核心在于基于Transformer架构的灵活重建模型(FlexRM),结合三平面表示与3D高斯绘制技术,实现高效且详细的三维重建,广泛应用于游戏开发、AR/VR、影视制作等领域。 AI项目与工具 2025年06月12日 45 点赞 0 评论 503 浏览
Pippo Pippo是由Meta Reality Labs研发的图像到视频生成模型,可基于单张照片生成多视角高清人像视频。采用多视角扩散变换器架构,结合ControlMLP模块与注意力偏差技术,实现更丰富的视角生成和更高的3D一致性。支持高分辨率输出及细节自动补全,适用于虚拟现实、影视制作、游戏开发等多个领域。技术方案涵盖多阶段训练流程,确保生成质量与稳定性。 AI项目与工具 2025年06月12日 38 点赞 0 评论 493 浏览