Vision Parse Vision Parse 是一款开源工具,旨在通过视觉语言模型将 PDF 文件转换为 Markdown 格式。它具备智能识别和提取 PDF 内容的能力,包括文本和表格,并能保持原有格式与结构。此外,Vision Parse 支持多种视觉语言模型,确保解析的高精度与高速度。其应用场景广泛,涵盖学术研究、法律文件处理、技术支持文档以及电子书制作等领域。 AI项目与工具 2025年06月12日 72 点赞 0 评论 613 浏览
看典古籍 一个致力于古籍数字化和保护文化遗产的平台。看典古籍通过先进的OCR算法,将不同版式、年代和字体的古籍转化为数字化内容,提供图文对比阅读和全文搜索功能。 剧本文案 2025年06月05日 83 点赞 0 评论 618 浏览
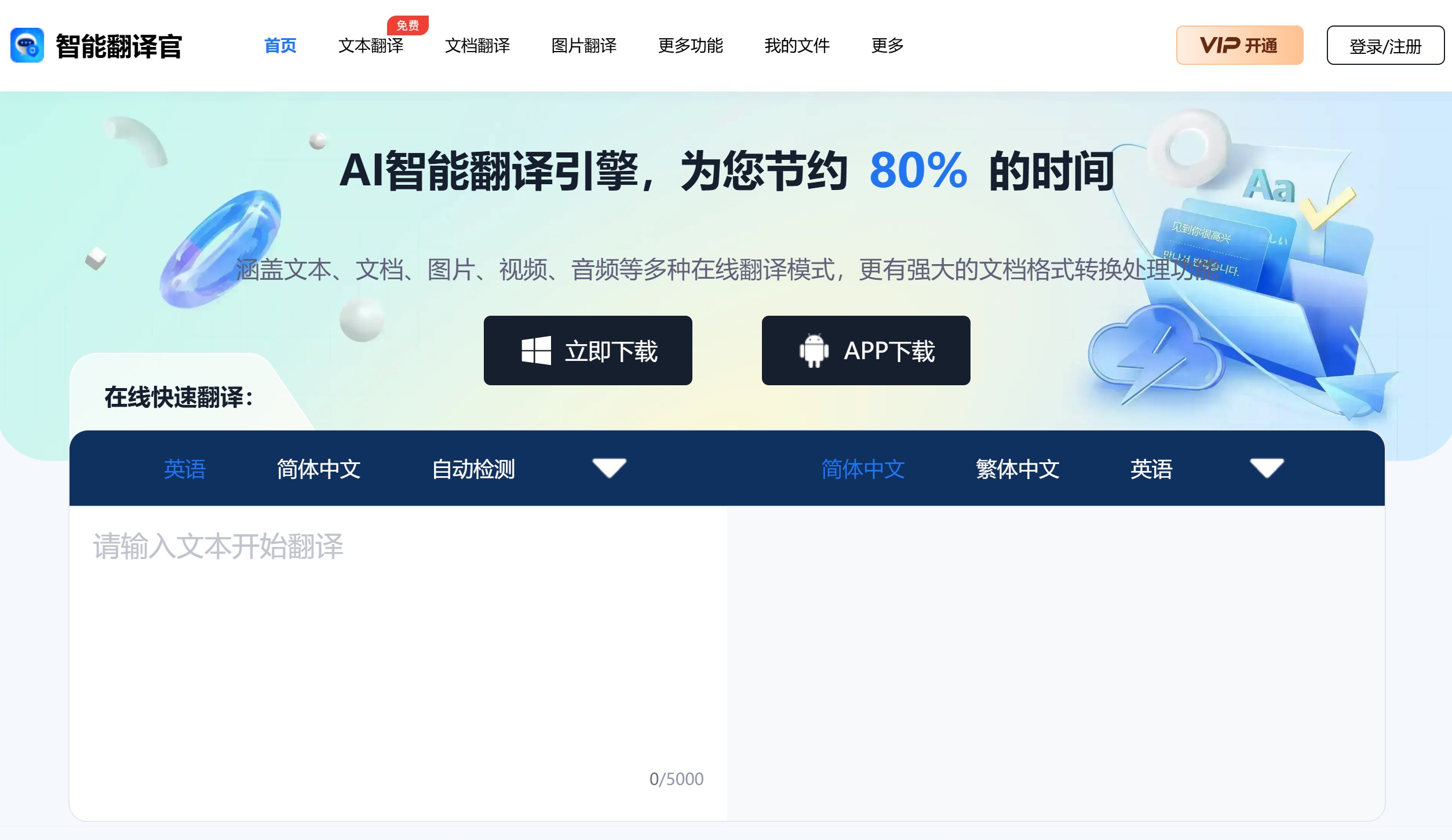
智能翻译官 AI智能翻译引擎,涵盖文本、文档、图片、视频、音频等多种在线翻译模式,更有强大的文档格式转换处理功能,为您节约80%的时间。 Ai办公效率 2025年06月05日 55 点赞 0 评论 624 浏览
PDFtoPDF PDFtoPDF是一款基于AI和OCR技术的PDF转换工具,支持高精度文字识别(准确率达99.5%),并能保留原始文档排版。具备多语言支持、文件压缩、跨平台使用及翻译功能,适用于学术、办公、教育和个人文档管理等多种场景,显著提升文档处理效率与便捷性。 AI项目与工具 2025年06月12日 51 点赞 0 评论 649 浏览
moonshot moonshot-v1-vision-preview 是一款由月之暗面开发的多模态图像理解模型,具备精准的图像识别、OCR 文字识别和数据解析能力。支持 API 集成,适用于内容审核、文档处理、医学分析、智能交互等多个领域。模型可识别复杂图像细节、分析图表数据,并从美学角度进行图像评价,适合需要高效图像处理和智能交互的应用场景。 AI项目与工具 2025年06月12日 52 点赞 0 评论 654 浏览
PDFcandy 一款多功能工具,提供了处理 PDF 文件的广泛功能。PDFcandy允许用户将文件从 PDF 转换为各种支持的格式,还提供用于合并、拆分和编辑 PDF 以及从 PDF 文件中提取图像和文本的工具。 格式转换 2025年06月05日 22 点赞 0 评论 670 浏览
AutoConsis AutoConsis是一款基于深度学习和大型语言模型的UI内容一致性智能检测工具,能够自动识别和提取界面中的关键数据,并对数据一致性进行高效校验。它支持多业务场景适配,具备高泛化性和高置信度,广泛应用于电商、金融、旅游等多个领域,助力提升用户体验和系统可靠性。 AI项目与工具 2025年06月12日 10 点赞 0 评论 676 浏览