MoneyPrinterPlus MoneyPrinterPlus是一款基于AI技术的短视频生成工具,能够实现一键批量生成并自动混剪短视频。该工具支持将视频自动发布至多个社交平台,简化了视频内容创作流程。MoneyPrinterPlus的核心功能包括AI一键批量生成短视频、自动批量混剪、自动发布到社交平台、支持本地和云语音服务以及AI生图功能。 AI项目与工具 2025年06月12日 61 点赞 0 评论 756 浏览
FancyTech 一家专注于人工智能内容生成的公司,提供创新的AI平台,能够将产品图片转换成吸引人的、具有传播性的视频,从而将静态的视觉内容转变为动态且富有吸引力的形式。 电商运营 2025年06月05日 25 点赞 0 评论 759 浏览
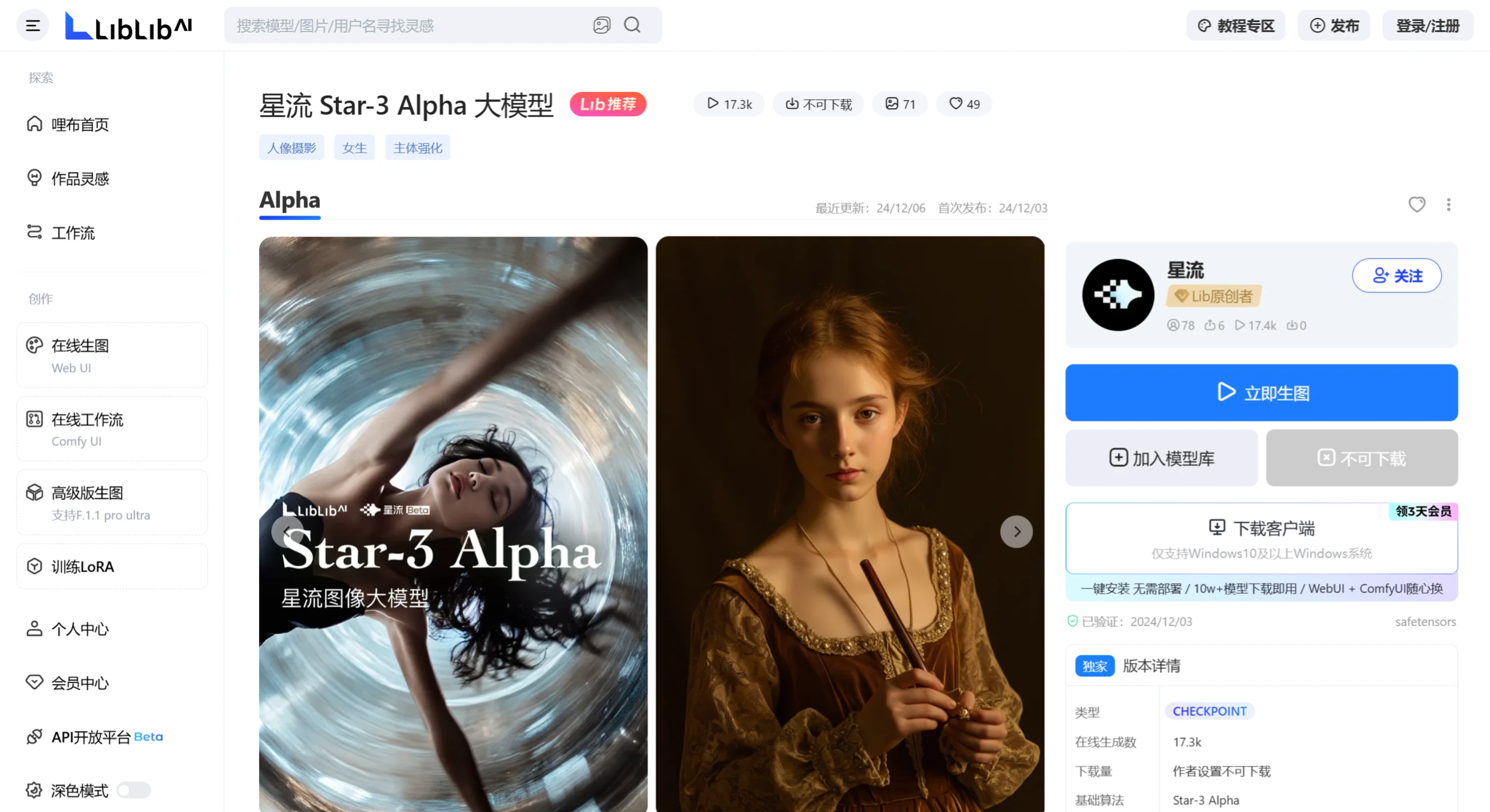
星流图像大模型 星流图像大模型是由LiblibAI发布的一款自研图像大模型,名为Star-3 Alpha。由LiblibAl团队于2024年启动研发,将于2025年Q1发布正式 Ai绘画生成 2025年06月05日 62 点赞 0 评论 760 浏览
右脑科技 | RightBrain 北京右脑科技有限公司(RightBrain AI)是一家专注研发AI图像和视频生成的初创公司, 致力于将AIGC技术应用于图像及视频领域。 AI服务商 2025年06月05日 35 点赞 0 评论 760 浏览
MnnLlmApp MnnLlmApp 是阿里巴巴基于 MNN-LLM 框架开发的开源 Android 应用,支持多种大语言模型在本地运行。具备多模态交互能力,可处理文本、图像、音频等多种输入输出任务。应用经过 CPU 推理优化,运行效率高,支持离线使用,保障数据安全。内置 Qwen、Gemma、Llama 等主流模型,适用于内容创作、智能助手、语言学习及创意设计等多种场景。 AI项目与工具 2025年06月12日 60 点赞 0 评论 760 浏览
Go Charlie 一款AI营销助手,帮助企业家和企业快速轻松地创建和发布内容,Go Charlie可帮助您在几秒钟内创建图像、博客、广告、影响者帖子等。 创业营销 2025年06月05日 80 点赞 0 评论 760 浏览
SimpleAR SimpleAR是一款由复旦大学与字节跳动联合研发的纯自回归图像生成模型,采用简洁架构实现高质量图像生成。其通过“预训练-有监督微调-强化学习”三阶段训练方法,提升文本跟随能力与生成效果。支持文本到图像及多模态融合生成,兼容加速技术,推理速度快。适用于创意设计、虚拟场景构建、多模态翻译、AR/VR等多个领域。 AI项目与工具 2025年06月11日 76 点赞 0 评论 761 浏览
Mini DALL·E 3 Mini DALL·E 3是一款由多所高校联合开发的交互式文本到图像生成工具,支持多轮自然语言对话,实现高质量图像的生成与编辑。系统结合大型语言模型与文本到图像模型,提供内容一致性控制与问答功能,提升交互体验。广泛应用于创意设计、故事插图、概念设计、教育及娱乐等领域,具有高效、灵活和易用的特点。 AI项目与工具 2025年06月12日 18 点赞 0 评论 762 浏览
Jodi Jodi是由中国科学院计算技术研究所和中国科学院大学推出的扩散模型框架,基于联合建模图像域和多个标签域,实现视觉生成与理解的统一。它支持联合生成、可控生成和图像感知三种任务,利用线性扩散Transformer和角色切换机制,提升生成效率和跨领域一致性。Jodi使用Joint-1.6M数据集进行训练,包含20万张高质量图像和7个视觉域标签,适用于创意内容生成、多模态数据增强、图像编辑与修复等场景。 AI项目与工具 2025年06月11日 32 点赞 0 评论 763 浏览
Miracle F1 Miracle F1 是一款由美图 WHEE 推出的 AI 图像生成工具,具备高真实感的图像生成能力,能精准处理光影、材质和空间效果。其语义理解能力强,可准确还原复杂描述,如“纯色背景”“夜景灯光”等。支持多种风格,涵盖 3D 立体、二次元、复古等,适用于电商展示、活动海报、插画设计等多个场景。基于扩散模型和优化算法,提升了生成效率与质量。 AI项目与工具 2025年06月12日 51 点赞 0 评论 764 浏览