Pollinations.AI Pollinations.AI是一个开源AI内容生成平台,提供图像生成、文本生成、音频转换及视觉分析等功能。用户无需注册即可使用,支持多种模型和参数配置,适合开发者和创作者快速集成与应用。平台还提供浏览器开发环境,简化了使用流程,提升了效率。 AI项目与工具 2025年06月11日 50 点赞 0 评论 801 浏览
Freeflo.ai Freeflo.ai 是一个多功能的 AI 绘画辅助平台,它通过提供丰富的风格提示词和直观的样例图像,极大地丰富了 AI 绘画的创作可能性。 创作工具 2026年06月22日 0 点赞 0 评论 801 浏览
CogView4 CogView4是一款由智谱推出的开源文生图模型,具有60亿参数,支持中英文输入与高分辨率图像生成。在DPG-Bench基准测试中表现优异,达到当前开源模型的领先水平。模型具备强大的语义理解能力,尤其在中文文字生成方面表现突出,适用于广告设计、教育、儿童绘本及电商等领域。其技术架构融合扩散模型与Transformer,并采用显存优化技术提升推理效率。 AI项目与工具 2025年06月12日 83 点赞 0 评论 802 浏览
Interior AI Interior AI是一个人工智能图像生成器平台,允许用户上传自己(或其他人)家的图像,并根据17种预选风格之一生成新的外观和布局。它是日益增长的人工智能图像生成器生态系统的一部分... 生活创意 2026年06月22日 0 点赞 0 评论 802 浏览
AISEO Art AISEO Art是一款基于AI技术的艺术生成平台,支持用户通过文本提示生成个性化视觉艺术作品。平台提供包括AI头像生成、图像变体、艺术模板选择及滤镜应用在内的多项功能,适用于广告设计、数字艺术创作、游戏开发及社交媒体营销等多个场景,助力用户高效产出高质量视觉内容。 AI项目与工具 2025年06月12日 81 点赞 0 评论 802 浏览
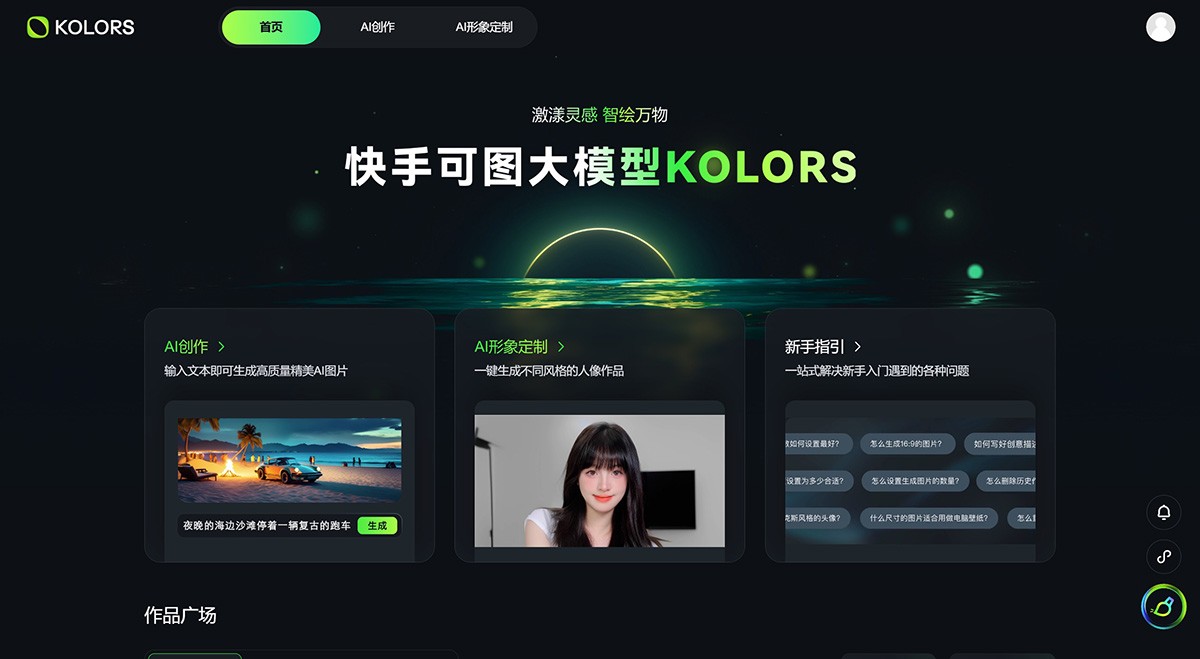
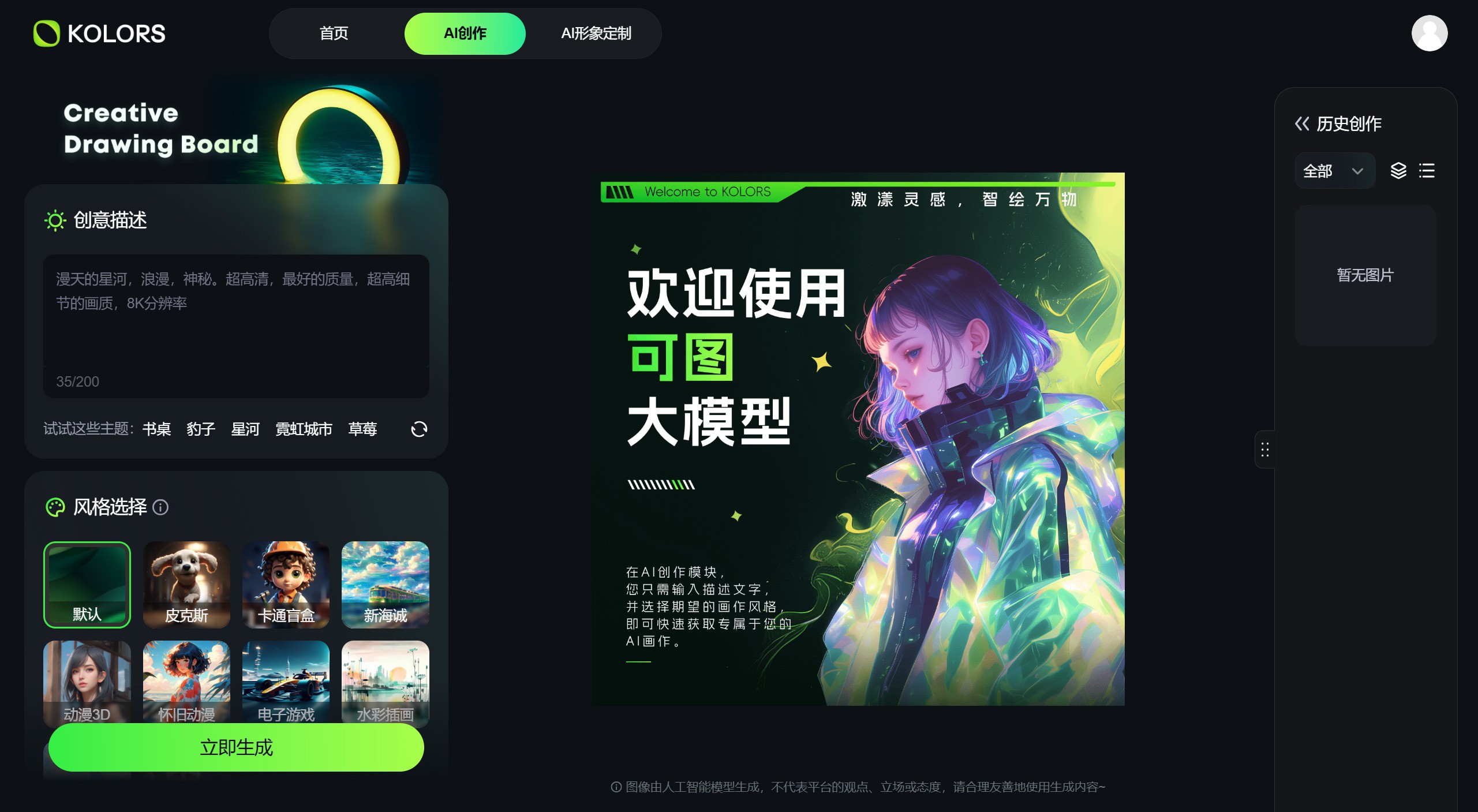
快手可图 快手可图大模型(Kolors)是快手公司自主研发的一款AI图像生成工具。支持文生图和图生图两大功能并提供了20多种AI图像玩法,Kolors可用于AI创作图像以及AI形象定制。 Ai平台模型 2025年06月05日 80 点赞 0 评论 802 浏览
SPAR3D SPAR3D是一种基于两阶段设计的单图像3D重建工具,能从单张2D图像生成高质量的3D网格。它结合点扩散模型与三平面Transformer技术,实现快速、精确的几何与纹理重建,并支持用户交互式编辑。适用于增强现实、影视制作、工业设计等多个领域。 AI项目与工具 2025年06月12日 86 点赞 0 评论 803 浏览
Ecomtent Ecomtent 是一个专为电子商务设计的 AI 内容生成与优化平台,提供包括产品图片、文案及图表在内的全方位服务。其核心功能涵盖 AI 图像生成、文案优化、搜索算法适配以及多渠道内容同步管理,旨在提升品牌在电商平台上的竞争力。无论是亚马逊还是 eBay 卖家,均可借助 Ecomtent 实现高效、精准的内容创作,从而优化用户体验并促进销售增长。 AI项目与工具 2025年06月12日 14 点赞 0 评论 804 浏览
Crypko.Ai crypko.ai是一款基于AI的动漫角色生成工具。不需要绘画基础,用户即可修改角色的设计,添加自然的动画。 Ai绘画生成 2025年06月05日 86 点赞 0 评论 804 浏览