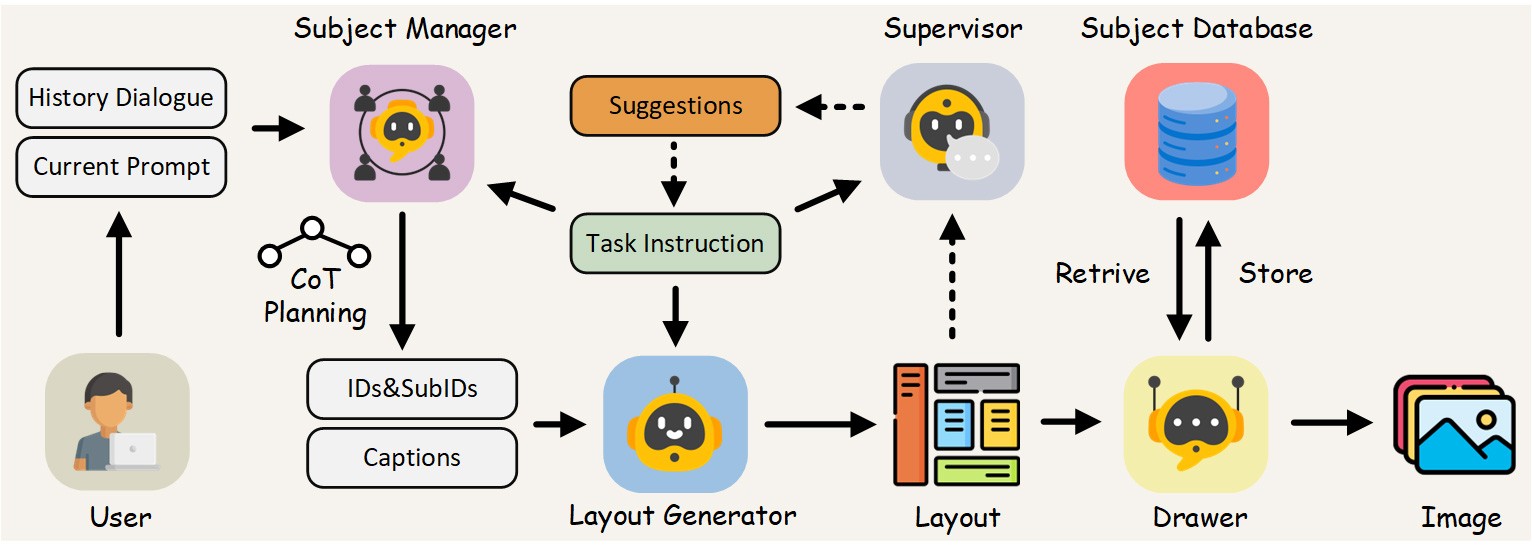
图像生成



Interior AI
Interior AI是一个人工智能图像生成器平台,允许用户上传自己(或其他人)家的图像,并根据17种预选风格之一生成新的外观和布局。它是日益增长的人工智能图像生成器生态系统的一部分...



Freeflo.ai
Freeflo.ai 是一个多功能的 AI 绘画辅助平台,它通过提供丰富的风格提示词和直观的样例图像,极大地丰富了 AI 绘画的创作可能性。

Pollinations.AI
Pollinations.AI是一个开源AI内容生成平台,提供图像生成、文本生成、音频转换及视觉分析等功能。用户无需注册即可使用,支持多种模型和参数配置,适合开发者和创作者快速集成与应用。平台还提供浏览器开发环境,简化了使用流程,提升了效率。


