图像生成


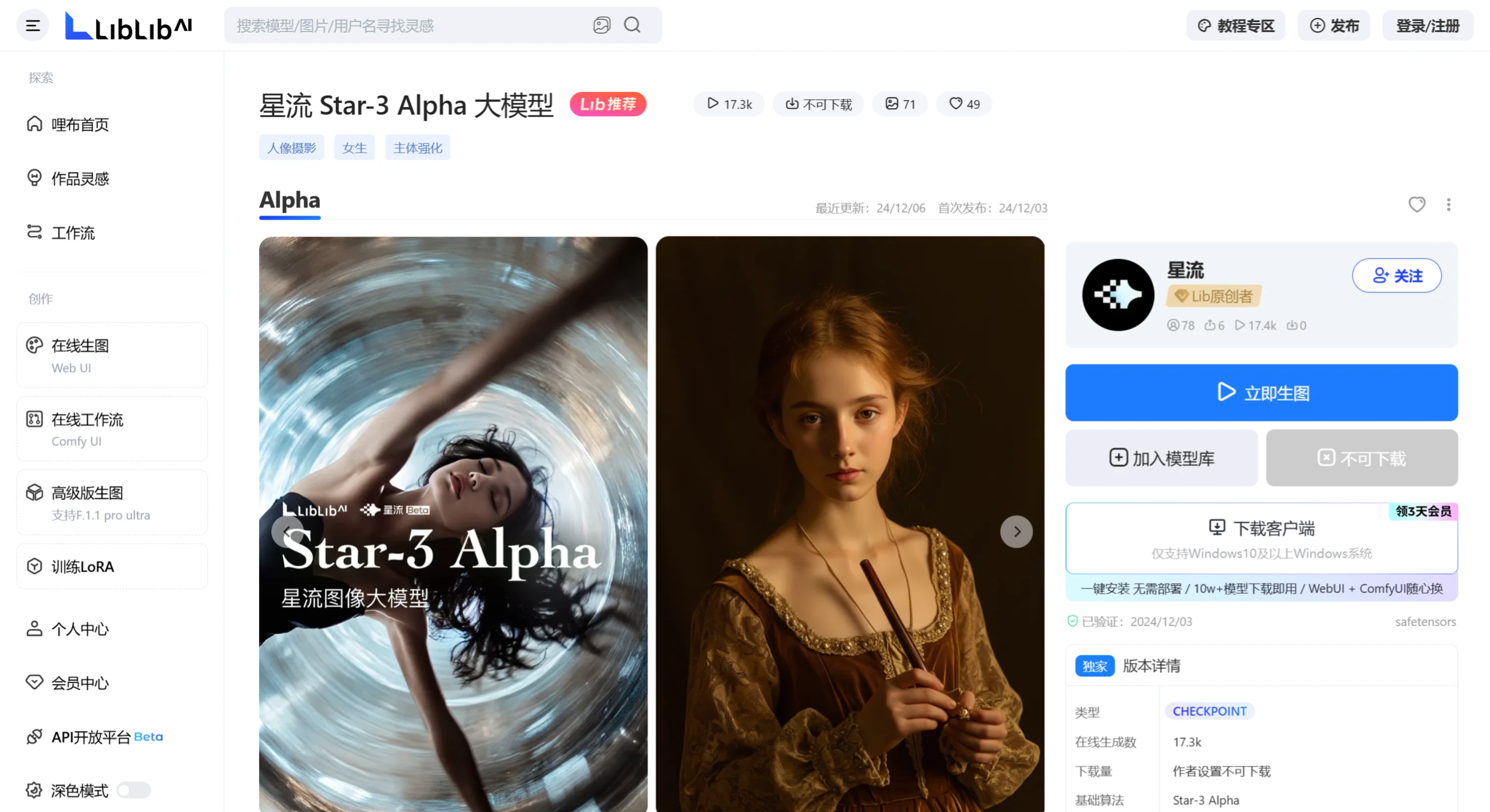

Mini DALL·E 3
Mini DALL·E 3是一款由多所高校联合开发的交互式文本到图像生成工具,支持多轮自然语言对话,实现高质量图像的生成与编辑。系统结合大型语言模型与文本到图像模型,提供内容一致性控制与问答功能,提升交互体验。广泛应用于创意设计、故事插图、概念设计、教育及娱乐等领域,具有高效、灵活和易用的特点。


Go Charlie
一款AI营销助手,帮助企业家和企业快速轻松地创建和发布内容,Go Charlie可帮助您在几秒钟内创建图像、博客、广告、影响者帖子等。


右脑科技 | RightBrain
北京右脑科技有限公司(RightBrain AI)是一家专注研发AI图像和视频生成的初创公司, 致力于将AIGC技术应用于图像及视频领域。

MoneyPrinterPlus
MoneyPrinterPlus是一款基于AI技术的短视频生成工具,能够实现一键批量生成并自动混剪短视频。该工具支持将视频自动发布至多个社交平台,简化了视频内容创作流程。MoneyPrinterPlus的核心功能包括AI一键批量生成短视频、自动批量混剪、自动发布到社交平台、支持本地和云语音服务以及AI生图功能。

ImageToPromptAI
ImageToPromptAI 是一款AI驱动的图像转文本工具,可快速生成高精度的图像描述,适用于图像生成、艺术创作及内容设计等领域。其功能包括图像分析、文本提示生成和隐私保护,支持多场景应用,助力创作者提高效率与创意表现。

STOCKIMG.AI
STOCKIMG.AI 是一款以人工智能驱动的在线设计与内容生成平台,用户可通过文本提示生成高质量图像、标志、书籍封面、海报等内容。平台支持 4K 分辨率图像放大、多风格 AI 模型选择及快速生成,适用于设计师、营销人员及内容创作者,广泛应用于社交媒体营销、品牌设计、图书出版等领域。
