PersonaMagic PersonaMagic 是一种基于文本条件策略的人脸生成技术,通过动态嵌入学习和双平衡机制实现高保真个性化图像生成。该工具可依据文本提示调整人脸风格、表情和背景,同时保持身份特征。支持单图像训练,降低数据需求,并可与其他模型结合使用。实验显示其在文本对齐和身份保持方面表现优异,适用于娱乐、游戏、影视及营销等多个领域。 AI项目与工具 2025年06月12日 67 点赞 0 评论 548 浏览
MV MV-Adapter是一款基于文本到图像扩散模型的多视图一致图像生成工具,通过创新的注意力机制和条件编码器,实现了高分辨率多视角图像生成。其核心功能包括多视图图像生成、适配定制模型、3D模型重建以及高质量3D贴图生成,适用于2D/3D内容创作、虚拟现实、自动驾驶等多个领域。 AI项目与工具 2025年06月12日 23 点赞 0 评论 548 浏览
汉语新解TextHuman 一个基于李继刚Prompt模板的项目,汉语新解对中文名词进行二次翻译,并生成美观的图像。TextHuman提供智能词汇解释,用户可以输入任何汉语词汇,获得AI生成的新颖解释。 剧本文案 2025年06月05日 30 点赞 0 评论 549 浏览
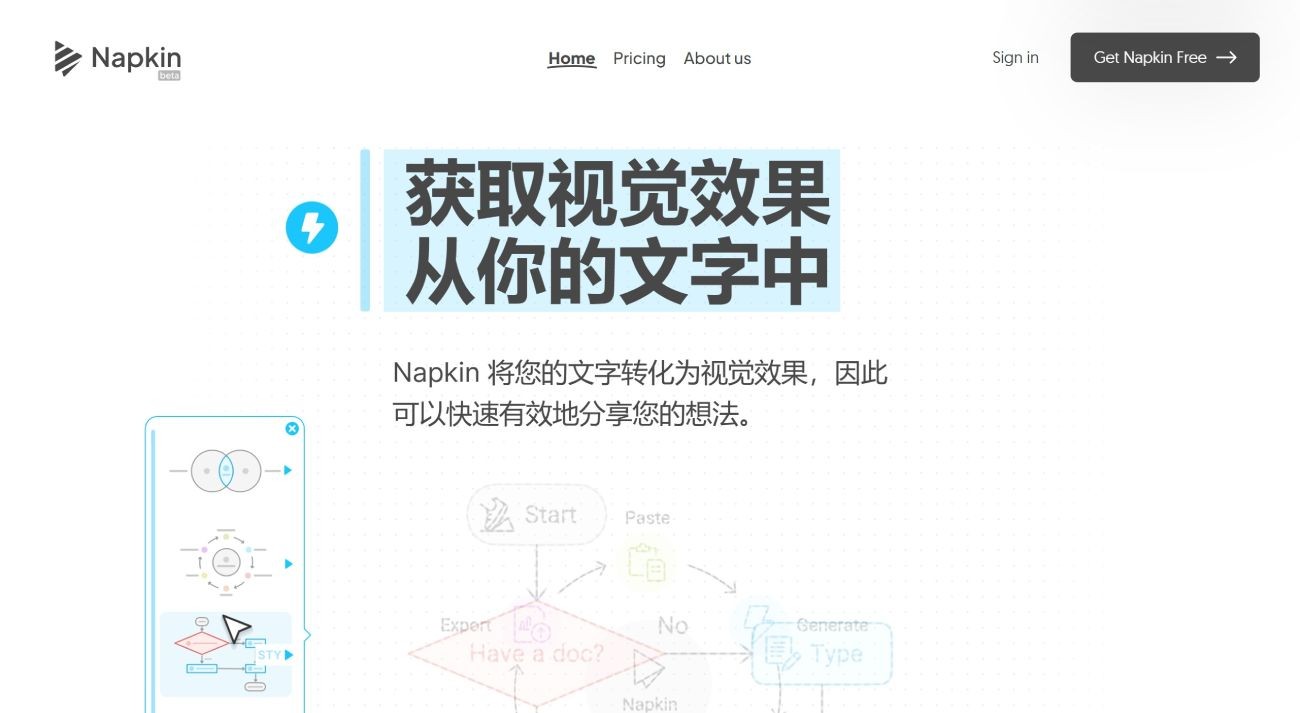
Napkin AI 一款让人眼前一亮的笔记产品,它的强大功能在于能够将文字变成图像。用户只需将文本粘贴到平台上,Napkin便能自动识别文本内容,它能够将你的文字内容,瞬间转化为生动的图表、信息图、流程图等视觉元素。 PPT资源 2025年06月05日 42 点赞 0 评论 549 浏览
在线AI转换 在线AI转换是一个集语音处理与图像优化于一体的AI平台,支持文本转语音、语音转文字、图像去雾、无损放大、黑白上色等功能,操作便捷,适用于多种应用场景,如有声书制作、会议记录、照片修复等,有效提升内容创作与图像处理效率。 AI项目与工具 2025年06月12日 12 点赞 0 评论 550 浏览
Personalized Restoration 一个面部图像精准恢复和个性编辑技术工具,不仅能复原受损图像细节,同时能精准捕捉和重现个人独特的面部特征。同时它还支持换脸。 Ai开源项目 2025年06月05日 52 点赞 0 评论 550 浏览
WebLI WebLI-100B是由Google DeepMind推出的超大规模视觉语言数据集,包含1000亿个图像与文本配对数据,是目前最大的视觉语言数据集之一。其设计旨在提升模型对长尾概念、文化多样性和多语言内容的理解能力。数据集通过网络爬取构建,保留了丰富的语言和文化多样性,支持多模态任务如图像分类、图像描述生成和视觉问答,广泛应用于人工智能研究、工程开发及教育领域。 AI项目与工具 2025年06月12日 51 点赞 0 评论 550 浏览
VideoTuna VideoTuna是一款基于AI的开源视频生成工具,支持文本到视频、图像到视频以及文本到图像的转换。它提供预训练、微调和后训练对齐等功能,兼容U-Net和DiT架构,并计划引入3D视频生成能力。VideoTuna旨在简化视频内容创作流程,提升生成质量与可控性,适用于内容创作、电影制作、广告营销、教育培训等多个领域。 AI项目与工具 2025年06月12日 30 点赞 0 评论 551 浏览
LOOK LOOK是一款面向时尚设计师的AI设计工具,通过AIGC技术实现设计概念的实时可视化。支持草图转图像、批量生产、文生图、图生图及模特试穿等功能,提高设计效率与创意表达。集成多种工具,简化设计流程,适用于教育、创意开发、产品设计等多个场景。 AI项目与工具 2025年06月12日 73 点赞 0 评论 551 浏览