Ideogram 2.0 Ideogram 2.0 是一款文本到图像的AI工具,能够将文字转化为高质量的视觉内容。该工具支持多种风格选择,包括写实、设计、3D和动漫,具有强大的语义理解能力和先进的文本渲染技术。通过Magic Prompt功能,用户可以输入中文提示词并自动翻译优化。此外,该工具还提供API和搜索功能,支持用户和开发者进行深度集成。 AI项目与工具 2025年06月12日 38 点赞 0 评论 695 浏览
Future You Future You是一款由麻省理工学院开发的AI对话工具,通过生成用户60岁后的虚拟形象,让用户与其互动交流,增强对未来自我的连续感。它结合了自然语言处理、机器学习和图像处理技术,帮助用户在个人发展、职业规划、教育、心理咨询及财务规划等领域实现更好的决策和规划。 AI项目与工具 2025年06月12日 81 点赞 0 评论 695 浏览
LeviTor LeviTor是一款由多所高校和企业联合研发的图像到视频合成工具,它利用深度信息和K-means聚类点来控制视频中3D物体的轨迹,无需显式3D轨迹跟踪。通过高质量视频对象分割数据集训练,该工具能精准捕捉物体运动与交互,支持用户通过简单的2D图像操作实现复杂的3D效果,大幅降低了技术门槛,广泛应用于电影特效、游戏动画、虚拟现实等领域。 AI项目与工具 2025年06月12日 52 点赞 0 评论 695 浏览
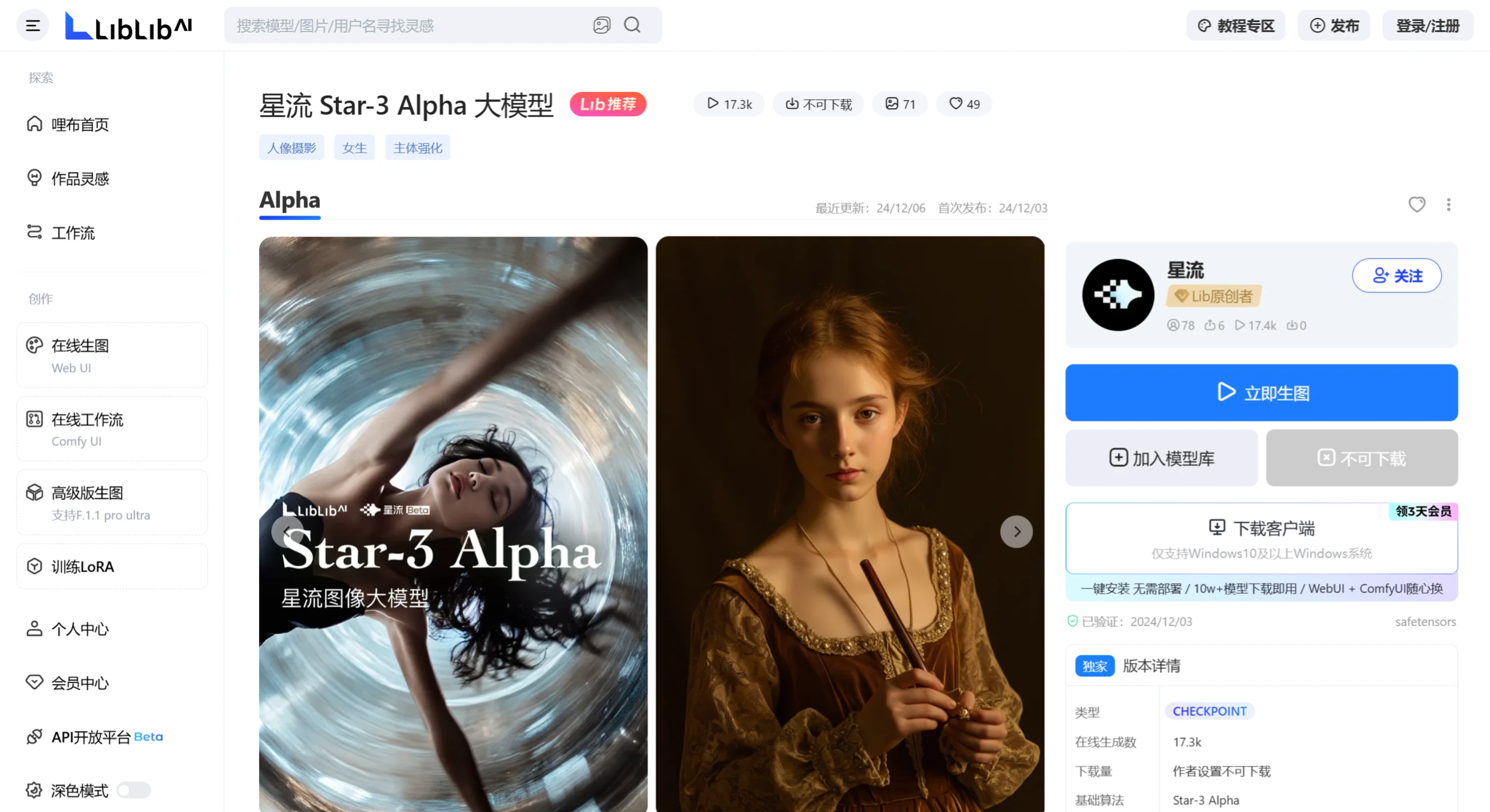
星流图像大模型 星流图像大模型是由LiblibAI发布的一款自研图像大模型,名为Star-3 Alpha。由LiblibAl团队于2024年启动研发,将于2025年Q1发布正式 Ai绘画生成 2025年06月05日 62 点赞 0 评论 696 浏览
DreamActor DreamActor-M1是字节跳动推出的AI图像动画框架,能够将静态照片转化为高质量动态视频。其核心在于混合引导机制,结合隐式面部表示、3D头球和身体骨架,实现对表情和动作的精准控制。支持多语言语音驱动、口型同步、灵活运动转移及多样化风格适配,适用于虚拟角色创作、个性化动画生成、虚拟主播制作及创意广告等领域,具备高保真、强连贯性和广泛适用性。 AI项目与工具 2025年06月12日 86 点赞 0 评论 696 浏览
Weights Weights 是一款基于人工智能技术的多媒体创作平台,支持语音翻唱、文字转语音、图片、视频、音乐等多种内容生成。用户可通过简单操作实现创意表达,并在社区中分享与交流。平台提供丰富的创作工具,适合不同层次的创作者,广泛应用于娱乐、教育、营销等多个领域。 AI项目与工具 2025年04月13日 58 点赞 0 评论 698 浏览
LineArt LineArt是一种无需训练的高质量设计绘图外观迁移框架,能将复杂外观特征准确转移到设计图纸上,同时保留结构细节。其技术基于模拟人类视觉认知过程,结合艺术经验指导扩散模型,支持工业设计、室内设计、服装设计等多个领域应用。具备高效、高保真和易用性等特点,适用于快速生成逼真效果和优化设计流程。 AI项目与工具 2025年06月12日 34 点赞 0 评论 698 浏览
Champ Champ是由阿里巴巴、复旦大学和南京大学的研究人员共同开发的一款基于3D的AI工具,能够将人物图片转换为高质量的视频动画。Champ通过结合3D参数化模型和潜在扩散模型,精准捕捉和再现人体的3D形态和动态,保证动画的连贯性和视觉逼真度。此外,Champ还支持跨身份动画生成,并能与文本生成图像模型结合,使用户可以根据文本描述生成特定的角色外观和动作。 AI项目与工具 2024年01月01日 81 点赞 0 评论 698 浏览
MangaNinja MangaNinja是一款基于参考图像的线稿上色工具,采用Reference U-Net和Denoising U-Net架构,结合补丁重排模块与点驱动控制方案,实现高精度、细粒度的上色效果。其可处理复杂场景、多参考图像协调及极端姿势等问题,广泛应用于漫画创作、插画设计、平面设计和数字艺术等领域。 AI项目与工具 2025年06月12日 66 点赞 0 评论 698 浏览
书生·万象InternVL 2.5 书生·万象InternVL 2.5是一款开源多模态大型语言模型,基于InternVL 2.0升级而来。它涵盖了从1B到78B不同规模的模型,支持多种应用场景,包括图像和视频分析、视觉问答、文档理解和信息检索等。InternVL 2.5在多模态理解基准上表现优异,性能超越部分商业模型,并通过链式思考技术提升多模态推理能力。 AI项目与工具 2025年06月12日 100 点赞 0 评论 698 浏览