3D AI Studio 3D AI Studio是一款基于AI技术的3D建模工具,支持文本到3D、图像到3D转换以及纹理处理等多种功能。它能够快速生成高质量的3D模型,适用于游戏开发、建筑设计、数字艺术创作等多个领域,同时具备多格式兼容性和便捷的操作体验,为用户提供高效且灵活的解决方案。 AI项目与工具 2025年06月12日 48 点赞 0 评论 796 浏览
文心iRAG 文心iRAG是百度推出的一种检索增强型文生图技术,它通过结合百度搜索引擎中的海量图片资源与先进基础模型能力,解决了大模型在文生图时容易出现的幻觉问题,显著提高了生成图片的真实性和准确性。此技术不仅适用于广告、媒体、教育等多个领域,还具备低成本、高效率的特点,能够快速生成满足需求的高质量图像。 AI项目与工具 2025年06月12日 66 点赞 0 评论 795 浏览
SNOOPI SNOOPI是一种基于增强单步扩散模型的文本到图像生成框架,通过PG-SB和NASA技术提高了模型的稳定性和控制力。它在多方面表现出色,包括提高生成效率、排除不期望的图像元素、支持多种模型背板以及生成高质量图像。SNOOPI广泛应用于数字艺术、游戏开发、广告、社交媒体和影视等领域。 AI项目与工具 2025年06月12日 27 点赞 0 评论 795 浏览
蓝心大模型 蓝心大模型是由vivo研发的通用大模型矩阵,包括语言、端侧、语音、图像及多模态模型。该模型在内容创作、知识问答、逻辑推理、代码生成、信息提取、多语言翻译等方面表现出色。蓝心端侧大模型3B在移动设备上表现出色,蓝心语音大模型支持多语言,蓝心图像大模型融合了中国特色和东方美学,蓝心多模态大模型则提供了流畅的视频对话体验。 AI项目与工具 2025年06月12日 76 点赞 0 评论 794 浏览
PackPack PackPack是一款由AI驱动的书签管理工具,专为新闻和社交媒体等网络资源定制保存功能。它利用AI清理并保存内容。使用PackPack,彻底改变你的书签管理方式,更智能地管理你的收藏。 创作工具 2026年06月22日 0 点赞 0 评论 794 浏览
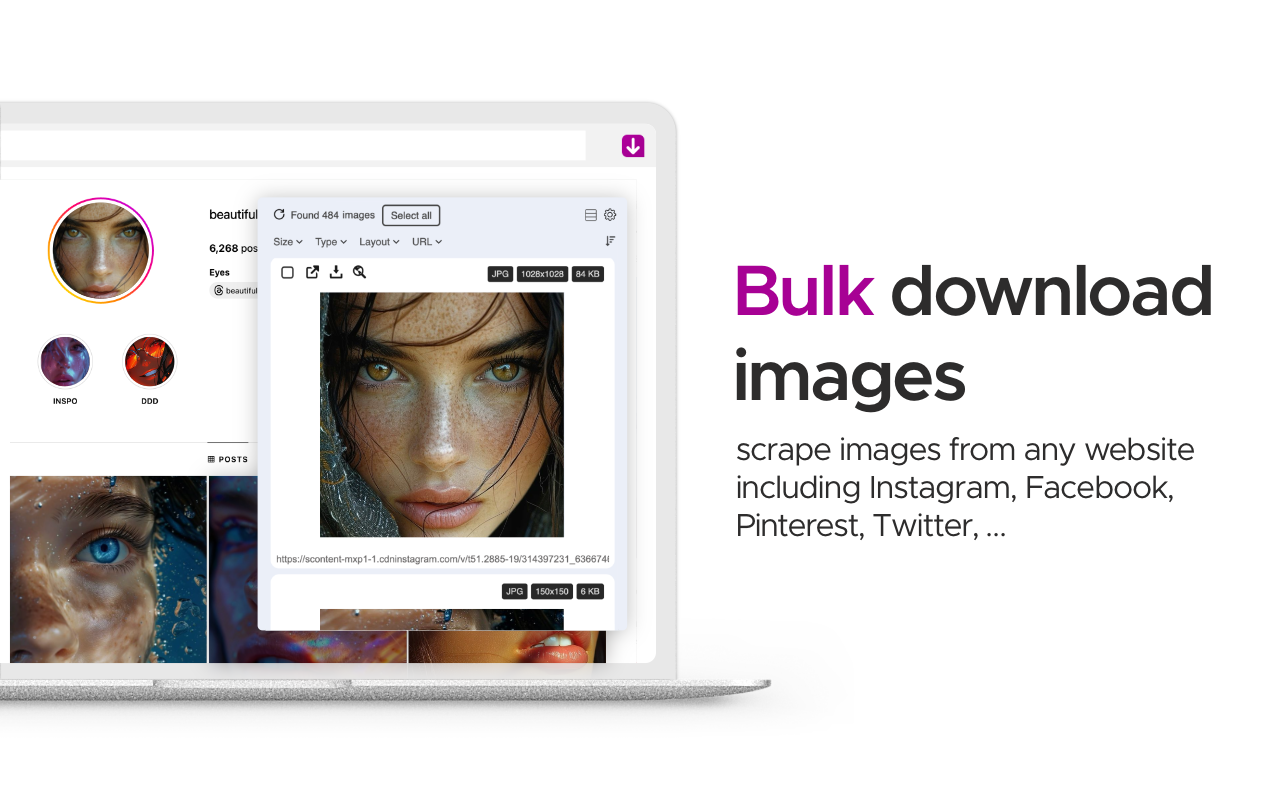
Imageye 一款用于嗅探、分析网页图片并提供批量下载等功能的浏览器扩展程序。Imageye支持批量下载和图片过滤功能,适用于 Chrome 和 Firefox 浏览器。 图片处理 2025年06月05日 93 点赞 0 评论 793 浏览
DreamActor DreamActor-M1是字节跳动推出的AI图像动画框架,能够将静态照片转化为高质量动态视频。其核心在于混合引导机制,结合隐式面部表示、3D头球和身体骨架,实现对表情和动作的精准控制。支持多语言语音驱动、口型同步、灵活运动转移及多样化风格适配,适用于虚拟角色创作、个性化动画生成、虚拟主播制作及创意广告等领域,具备高保真、强连贯性和广泛适用性。 AI项目与工具 2025年06月12日 86 点赞 0 评论 793 浏览
Qreates 高质量产品照片生成网站,用户只需通过Qreates输入简单的提示(如风格或氛围)就可以生成特定风格的产品照片,从而提升产品的吸引力。 Ai图片处理 2025年06月05日 41 点赞 0 评论 793 浏览
CustomCrafter CustomCrafter是一个由腾讯和浙江大学合作开发的自定义视频生成框架,能够根据文本提示和参考图像生成高质量的个性化视频。该框架支持自定义主体身份和运动模式,具备文本提示生成视频、保留运动生成能力和概念组合能力等功能。其核心技术包括视频扩散模型、空间主题学习模块和动态加权视频采样策略等,广泛应用于影视制作、虚拟现实、游戏开发、广告营销和社交媒体内容创作等领域。 AI项目与工具 2025年06月12日 31 点赞 0 评论 793 浏览
洞图 洞图是一款集多功能于一体的AI图片处理工具,主要功能包括制作隐藏文字的幻觉图片、生成逼真的AI写真、智能擦除路人、照片动态化、AI换脸、美肤优化、风格滤镜应用以及照片清晰度提升等。其简洁的操作界面和强大处理能力,使用户能快速生成个性化图文素材,适用于多种应用场景,如社交媒体分享、隐私保护、形象照制作及照片修复等。 AI项目与工具 2025年06月12日 67 点赞 0 评论 792 浏览