PanoDreamer PanoDreamer是一款基于单张图像生成连贯360° 3D场景的AI工具。其核心技术包括将全景图像生成与深度估计转化为优化任务,并引入交替最小化策略,确保场景的一致性和完整性。该工具支持全景图像及深度信息生成,可应用于虚拟现实、游戏开发、内容创作等多个领域,展现出卓越的性能表现。 AI项目与工具 2025年06月12日 83 点赞 0 评论 747 浏览
ComicsMaker ComicsMaker是一款基于人工智能技术的在线漫画创作平台,提供页面设计、漫画风格生成、图像处理、姿势创建、图片修复等功能,支持高清画质输出及多种漫画风格选择,适用于个人创作、教学辅助及商业用途,助力用户快速实现漫画创作目标。 AI项目与工具 2025年06月12日 30 点赞 0 评论 747 浏览
VLM VLM-R1 是由 Om AI Lab 开发的视觉语言模型,基于 Qwen2.5-VL 架构,结合强化学习优化技术,具备精准的指代表达理解和多模态处理能力。该模型适用于复杂场景下的视觉分析,支持自然语言指令定位图像目标,并在跨域数据中表现出良好的泛化能力。其应用场景涵盖智能交互、无障碍辅助、自动驾驶、医疗影像分析等多个领域。 AI项目与工具 2025年06月12日 42 点赞 0 评论 746 浏览
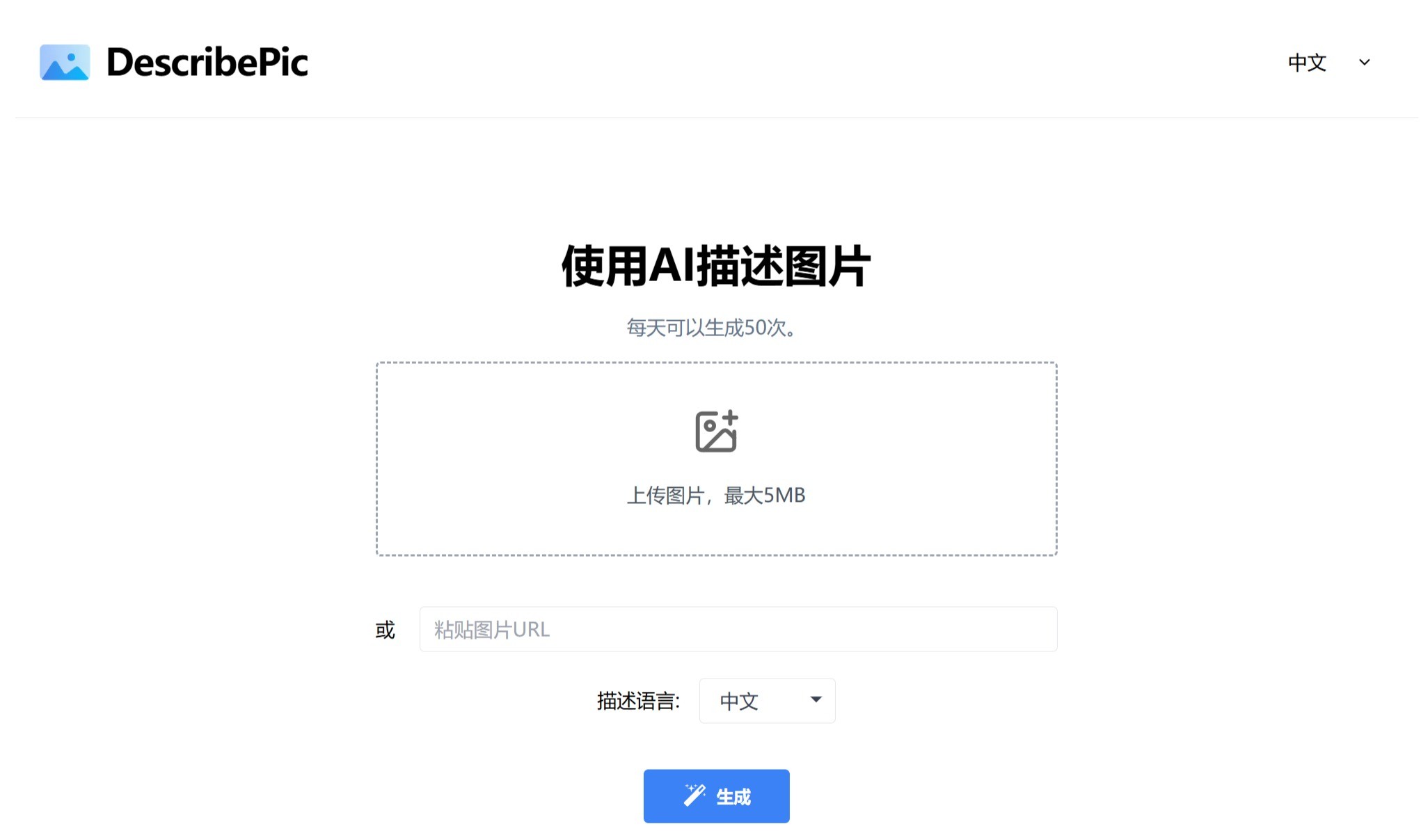
DescribePic 一个利用人工智能来生成上传图片描述的在线工具。DescribePic允许用户上传一张图片,并接收到该图片内容的人工智能生成描述。帮助用户快速生成图片说明,适用于内容创作者、社交媒体用户等。 Ai提示指令 2025年06月05日 87 点赞 0 评论 746 浏览
SynthID SynthID是一款由DeepMind研发的技术工具,通过在AI生成的内容中嵌入数字水印来验证其真实性与原创性。它支持多种内容形式,包括文本、音乐、图像和视频,并具备良好的抗修改性和检测稳定性。SynthID不仅不影响内容质量,还提升了信息可信度,广泛应用于新闻、版权保护、教育、法律及社交媒体等领域。 AI项目与工具 2025年06月12日 43 点赞 0 评论 746 浏览
腾讯混元游戏 腾讯发布的混元游戏视觉生成平台,这是依托混元大模型打造的首个工业级AIGC游戏内容生产引擎,可以优化游戏资产生成与游戏制作流程。 3D&游戏 2025年06月05日 38 点赞 0 评论 745 浏览
3DIS 3DIS-FLUX是一种基于深度学习的多实例图像生成框架,采用两阶段流程:先生成场景深度图,再进行细节渲染。通过注意力机制实现文本与图像的精准对齐,无需额外训练即可保持高生成质量。适用于电商设计、创意艺术、虚拟场景构建及广告内容生成等领域,具备良好的兼容性和性能优势。 AI项目与工具 2025年06月12日 32 点赞 0 评论 745 浏览
改图鸭 改图鸭是一个在线图片处理工具,用户无需下载、安装任何程序,即可在线对图片进行多种编辑处理。它拥有多功能图片处理功能,如图片编辑、图片格式转换、证件照制作、图片变漫画、... 创作工具 2026年06月22日 0 点赞 0 评论 745 浏览
LEOPARD LEOPARD是一款由腾讯AI Lab开发的视觉语言模型,专为处理包含大量文本的多图像任务而设计。它通过自适应高分辨率多图像编码模块和大规模多模态指令调优数据集,实现对复杂视觉语言任务的高效处理,包括跨图像推理、高分辨率图像处理及动态视觉序列长度优化。LEOPARD在自动化文档理解、教育、商业智能等领域具有广泛应用潜力。 AI项目与工具 2025年06月12日 35 点赞 0 评论 745 浏览
Kandinsky Kandinsky-3是一款基于潜在扩散模型的文本到图像生成框架,支持文本到图像生成、图像修复、图像融合、文本-图像融合、图像变化生成及视频生成等多种功能。其核心优势在于简洁高效的架构设计,能够快速生成高质量图像并提升推理效率。 AI项目与工具 2025年06月12日 84 点赞 0 评论 745 浏览