图像


TextHarmony
TextHarmony是一款由华东师范大学与字节跳动联合开发的多模态生成模型,擅长视觉与文本信息的生成与理解。该模型基于Slide-LoRA技术,支持视觉文本生成、编辑、理解及感知等功能,广泛应用于文档分析、场景文本识别、视觉问题回答、图像编辑与增强以及信息检索等领域。通过高质量数据集的构建与多模态预训练,TextHarmony在视觉与语言生成任务中表现出色。

Omni Reference
Omni Reference 是 Midjourney V7 提供的一项图像生成辅助功能,允许用户将特定人物、物体或场景嵌入生成图像中。通过 `--oref` 和 `--ow` 参数,用户可灵活控制参考图像的权重与风格融合程度,提升创作精度与多样性。支持 Web 和 Discord 两种平台操作,适用于角色嵌入、产品展示、场景构建等多种应用场景。



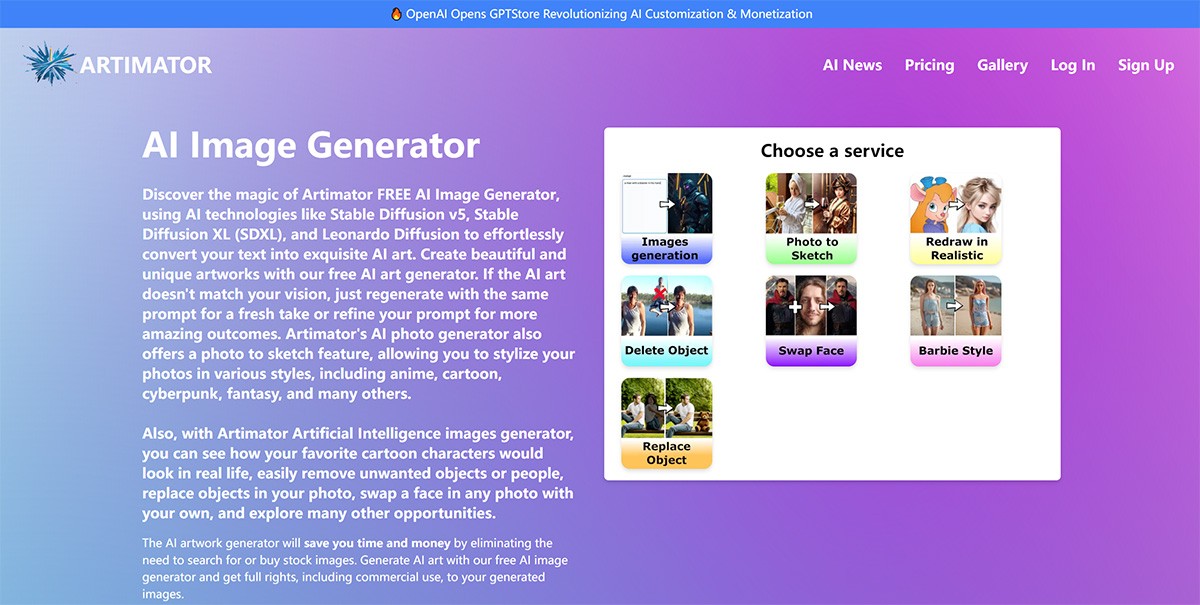
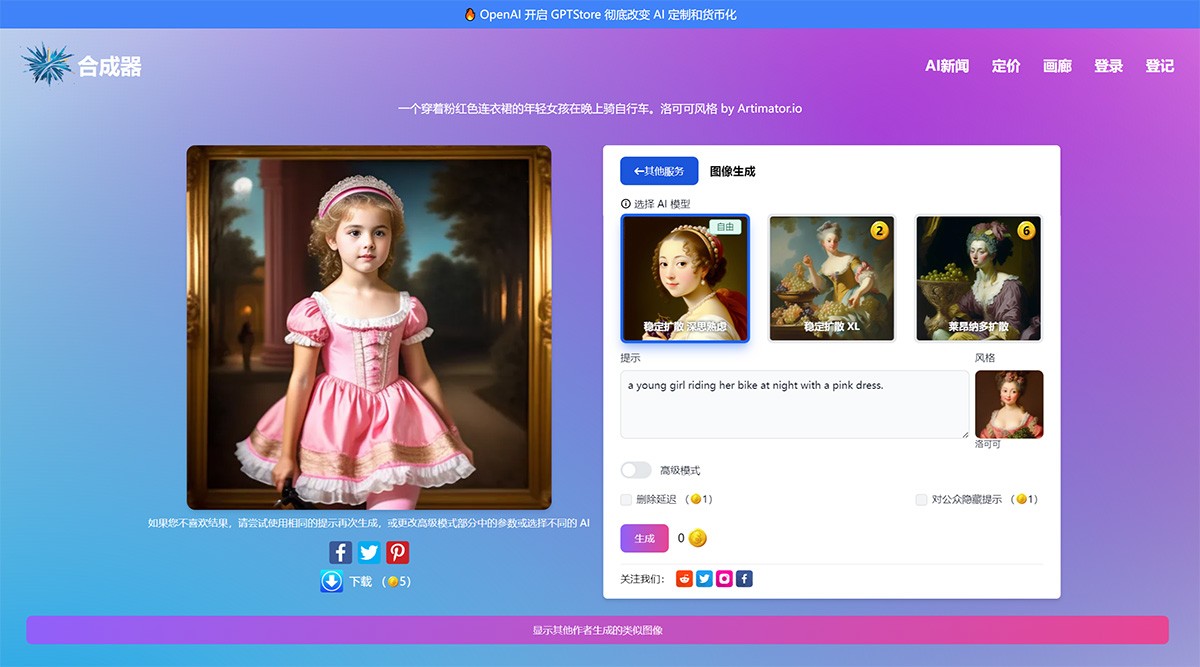

designtools.ai
DesignTools.ai 是一个集成了多种 AI 技术的专业设计平台,专为 UI 和 UX 设计师量身打造。它提供了包括 UI/UX 工具、配色方案生成、图像处理、排版设计、市场营销工具以及生产力提升工具在内的全面服务。通过这些功能,设计师可以更高效地完成各种设计任务,包括生成高质量的产品图像、创建 3D 模型、制定营销内容以及优化日常工作流程。

VideoDrafter
一个高质量视频生成的开放式扩散模型,相比之前的生成视频模型,VideoDrafter最大的特点是能在主体不变的基础上,一次性生成多个场景的视频。

