Masterpiece X Masterpiece X 是一款基于AI的3D建模工具,支持通过文本或图像生成高质量3D模型,具备自动纹理、骨骼绑定和动画功能,支持多格式导出并兼容主流3D软件。无需专业技能,适合艺术创作、游戏开发、影视制作等多种场景,提升创意效率与设计体验。 AI项目与工具 2025年06月12日 33 点赞 0 评论 737 浏览
Alpaca Alpaca 是一个强大的 AI 工具,它为艺术家和创意人士提供了一个创新的数字画布。通过其快速迭代、风格生成和非破坏性工作流的特点,Alpaca 能够帮助用户提升创作效率,实现个性化... 创作工具 2026年06月22日 0 点赞 0 评论 736 浏览
Cobra Cobra是由清华大学、香港中文大学和腾讯ARC实验室联合开发的漫画线稿上色框架,采用因果稀疏注意力机制和局部可复用位置编码技术,实现高精度、高效率的自动上色。支持颜色提示调整,提升灵活性与个性化。适用于漫画、动画、插画等多种场景,具有高效的推理能力和良好的扩展性。项目已开源,包含技术论文与模型资源。 AI项目与工具 2025年06月11日 21 点赞 0 评论 734 浏览
FLUX1.1 FLUX1.1 Pro是一款由Black Forest Labs开发的AI图像生成工具,以其高达6倍的生成速度、高精度图像质量和多样化风格著称。它支持通过模仿单反相机文件名提升图像真实感,广泛应用于艺术创作、设计、广告和社交媒体内容生成等领域。此外,FLUX1.1 Pro还具备商业化API接口,便于集成到各类应用中,是一款兼具高效性和实用性的专业工具。 AI项目与工具 2025年06月12日 33 点赞 0 评论 734 浏览
PaliGemma 2 PaliGemma 2是一款由Google DeepMind研发的视觉语言模型(VLM),结合了SigLIP-So400m视觉编码器与Gemma 2语言模型,支持多种分辨率的图像处理。该模型具备强大的知识迁移能力和出色的学术任务表现,在OCR、音乐乐谱识别以及医学图像报告生成等方面实现了技术突破。它能够处理多模态任务,包括图像字幕生成、视觉推理等,并支持量化和CPU推理以提高计算效率。 AI项目与工具 2025年06月12日 10 点赞 0 评论 733 浏览
AskManyAI AskManyAI是一站式AI大模型聚合平台,汇集了多个顶级AI模型,如GPT、Claude、Kimi等。它通过多角度解答提升问题解决的效率和可信度,支持多AI模型协同工作、高效决策与智能筛选、智能写作与文案生成、AI绘画与设计、论文检索与学术探索等功能。平台界面简洁,支持多种文件格式和输入方式,并持续集成最新的AI模型更新。AskManyAI适用于各类创作和研究需求,提供免费和VIP套餐,VIP AI项目与工具 2025年06月12日 28 点赞 0 评论 733 浏览
DeOldify DeOldify是一款利用深度学习技术的AI工具,可为黑白照片和视频上色并增强其视觉效果。它支持静态图像转动态视频、跨时代人物模拟等功能,适用于家庭相册修复、历史档案管理、教育演示及影视制作等多个场景,帮助用户更生动地记录和分享历史记忆。 AI项目与工具 2025年06月12日 88 点赞 0 评论 732 浏览
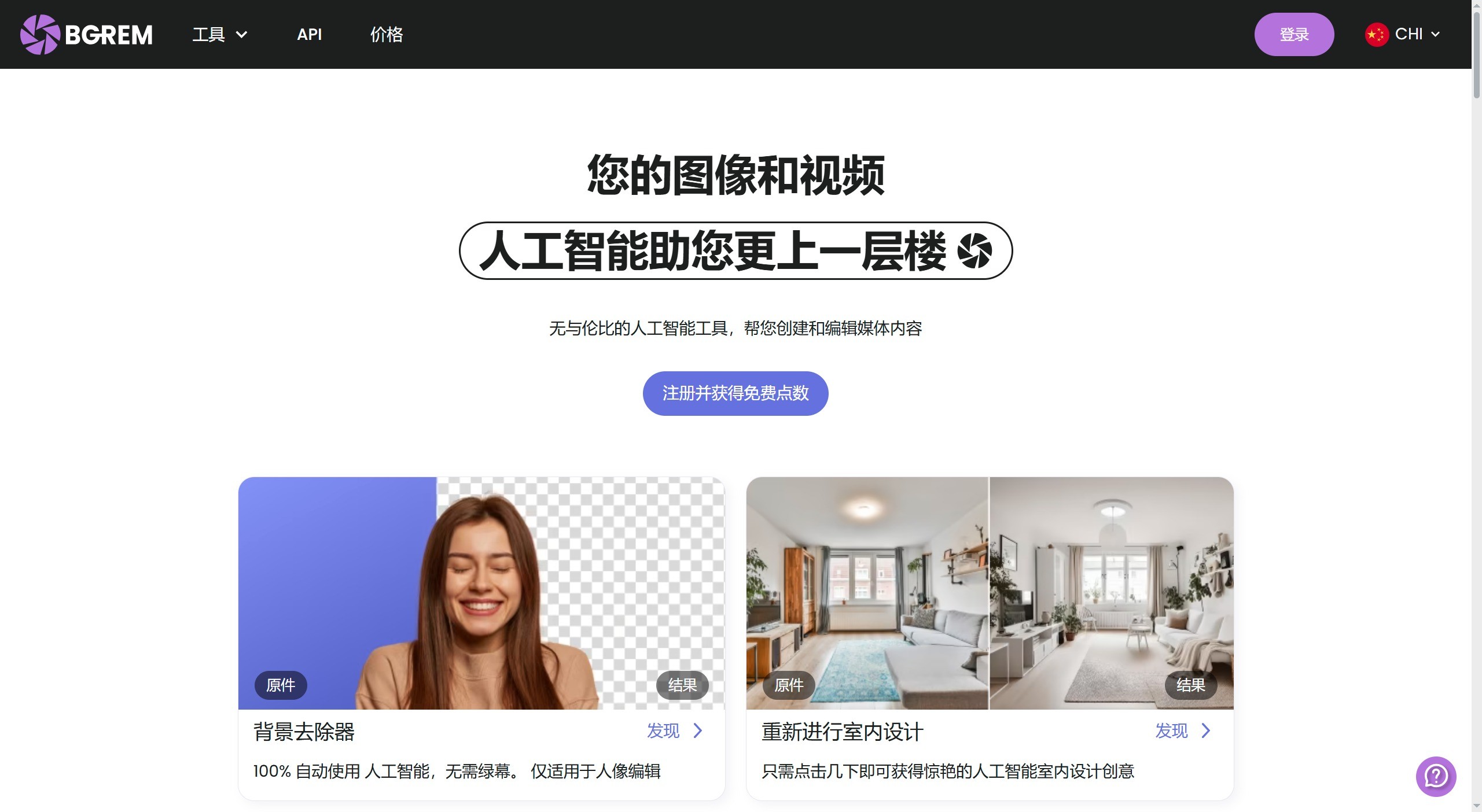
Bgrem.AI 一款可提供包括去除视频背景、生成图像、重新设计室内装饰、AI 滤镜、生成插图、去除不需要的对象等多种服务的AI工具,用户不需具备编辑技能或技术知识,就可使用 Bgrem.ai 进行图像和视频的编辑。 Ai图片处理 2025年06月05日 61 点赞 0 评论 732 浏览