场景






WeChat Bot
基于WeChaty结合OpenAI ChatGPT、Kimi、讯飞等多种AI服务实现的开源微信机器人项目,用于自动回复微信消息或管理微信群/好友。
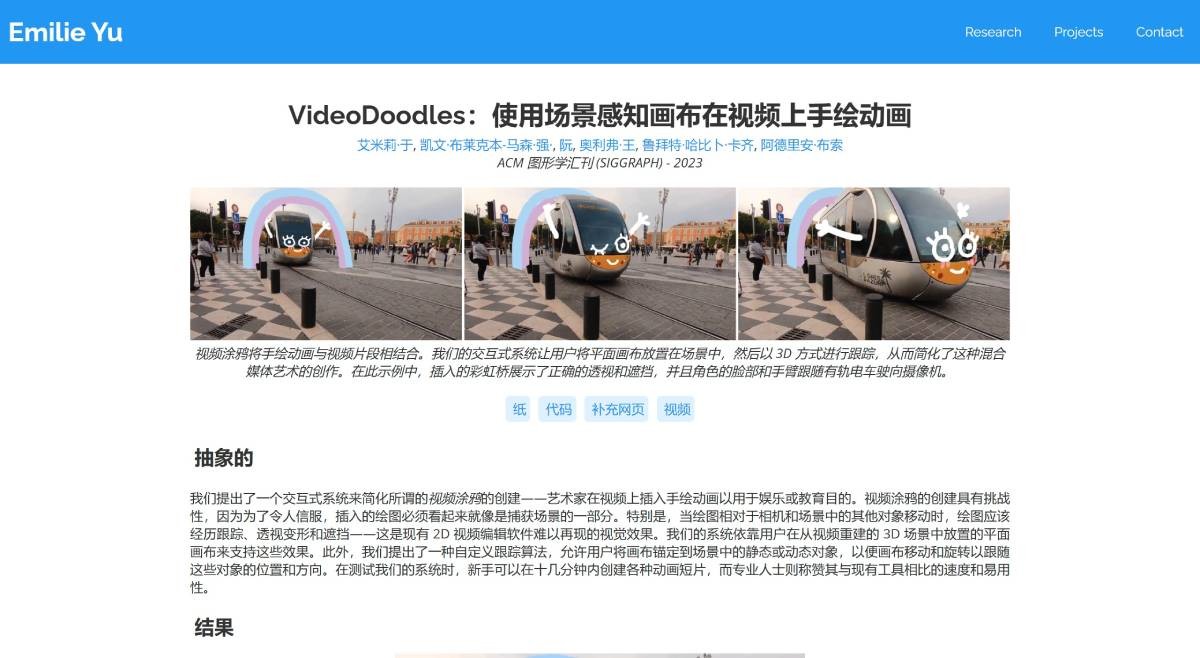



Diffuse to Choose
一种基于扩散的图像修复模型,主要用于虚拟试穿场景。它能够在修复图像时保留参考物品的细节,适用于在线购物等虚拟试穿场景中的图像修复任务。


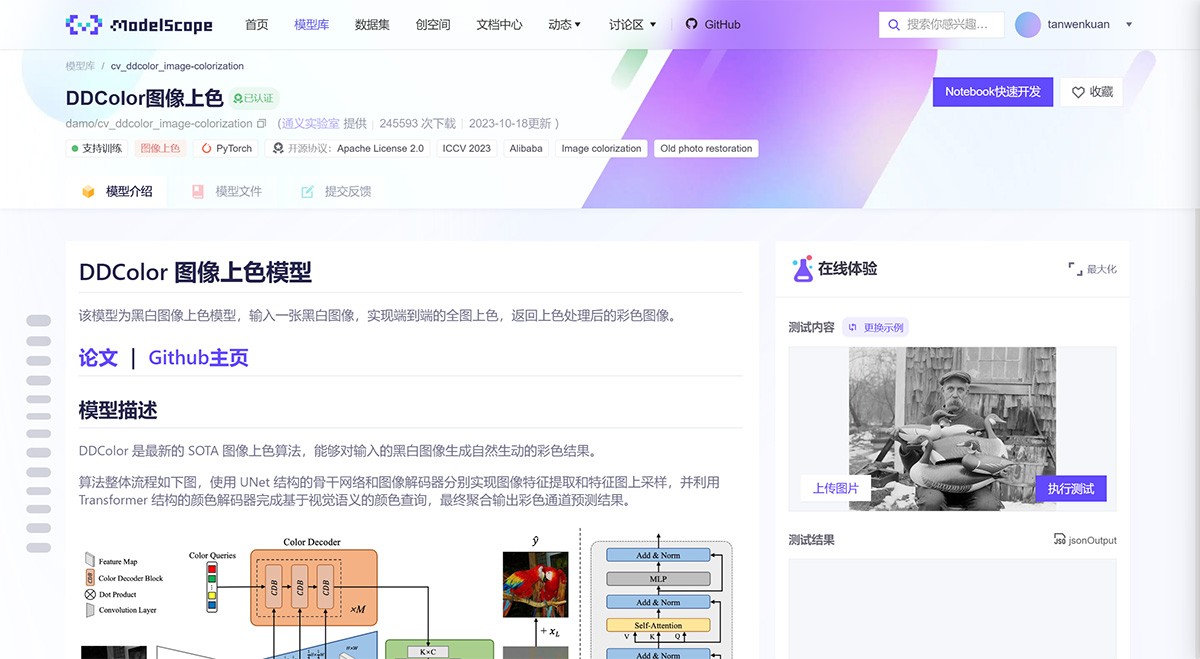

LucidDreamer
LucidDreamer,可以从单个图像的单个文本提示中生成可导航的3D场景。 单击并拖动(导航)/移动和滚动(缩放)以感受3D。
