CAVIA CAVIA是一款由苹果、得克萨斯大学奥斯汀分校和谷歌联合研发的多视角视频生成框架。它通过单一输入图像生成多个时空一致的视频序列,并采用视角集成注意力模块增强视频的一致性和连贯性,支持用户精准控制相机运动。此外,CAVIA利用多种数据源进行联合训练,优化生成视频的质量和真实感,在虚拟现实、增强现实以及电影制作等领域具有重要价值。 AI项目与工具 2025年06月12日 76 点赞 0 评论 814 浏览
Slax Note SlaxNote是一款利用语音识别技术的AI语音笔记应用,能够实时将语音转换为文本,并自动润色以提升文本质量。它特别适用于户外灵感捕捉、想法整理和内容总结。其主要功能包括实时语音转文字、自动润色、录音保存以及用户友好的界面设计,广泛应用于会议记录、灵感捕捉、日常笔记、亲子时光记录及内容创作等多个场景。 AI项目与工具 2025年06月12日 14 点赞 0 评论 817 浏览
Universal Universal-1是一款由AssemblyAI开发的多语言语音识别和转录模型,经过大量多语种音频数据训练,支持英语、西班牙语、法语和德语等。该模型在各种复杂环境中提供高精度的语音转文字服务,具备快速响应能力和改进的时间戳准确性。Universal-1在准确率、响应时间、时间戳估计和用户偏好等方面表现优异,适用于对话智能平台、AI记事本、创作者工具和远程医疗平台等多个应用场景。 AI项目与工具 2024年01月01日 88 点赞 0 评论 819 浏览
LLaVA LLaVA-OneVision是字节跳动开发的开源多模态AI模型,主要功能包括多模态理解、任务迁移、跨场景能力、开源贡献及高性能。该模型采用多模态架构,集成了视觉和语言信息,通过Siglip视觉编码器和Qwen-2语言模型,实现高效特征映射和任务迁移学习。广泛应用于图像和视频分析、内容创作辅助、聊天机器人、教育和培训以及安全监控等领域。 AI项目与工具 2025年06月12日 34 点赞 0 评论 819 浏览
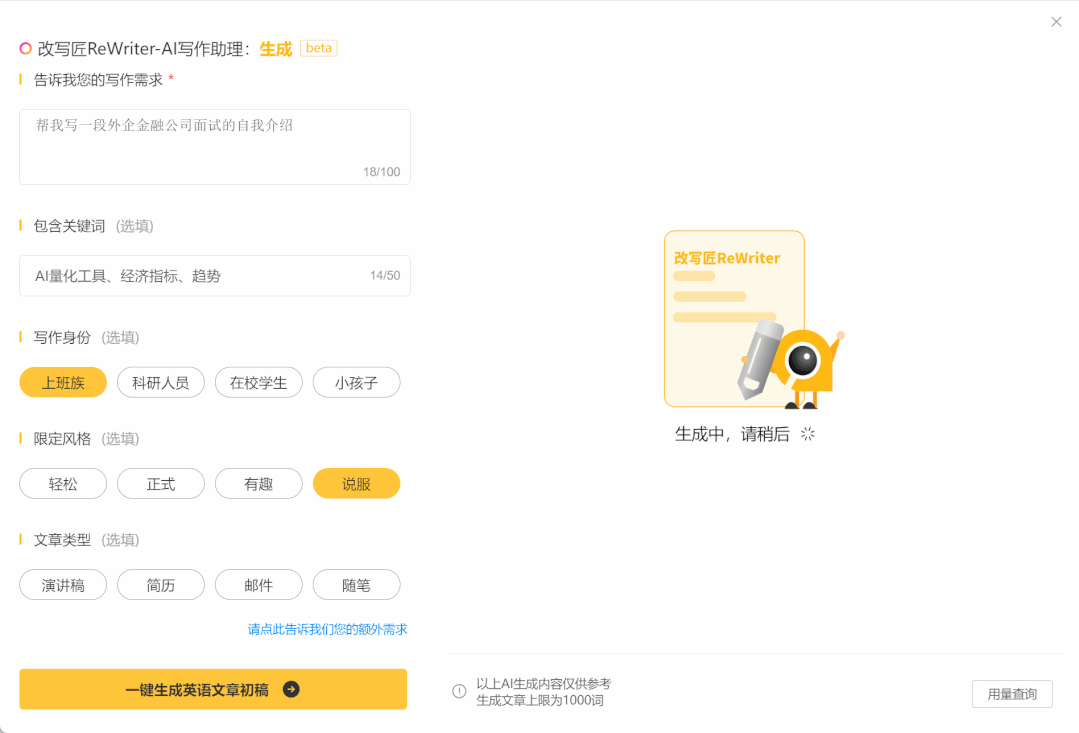
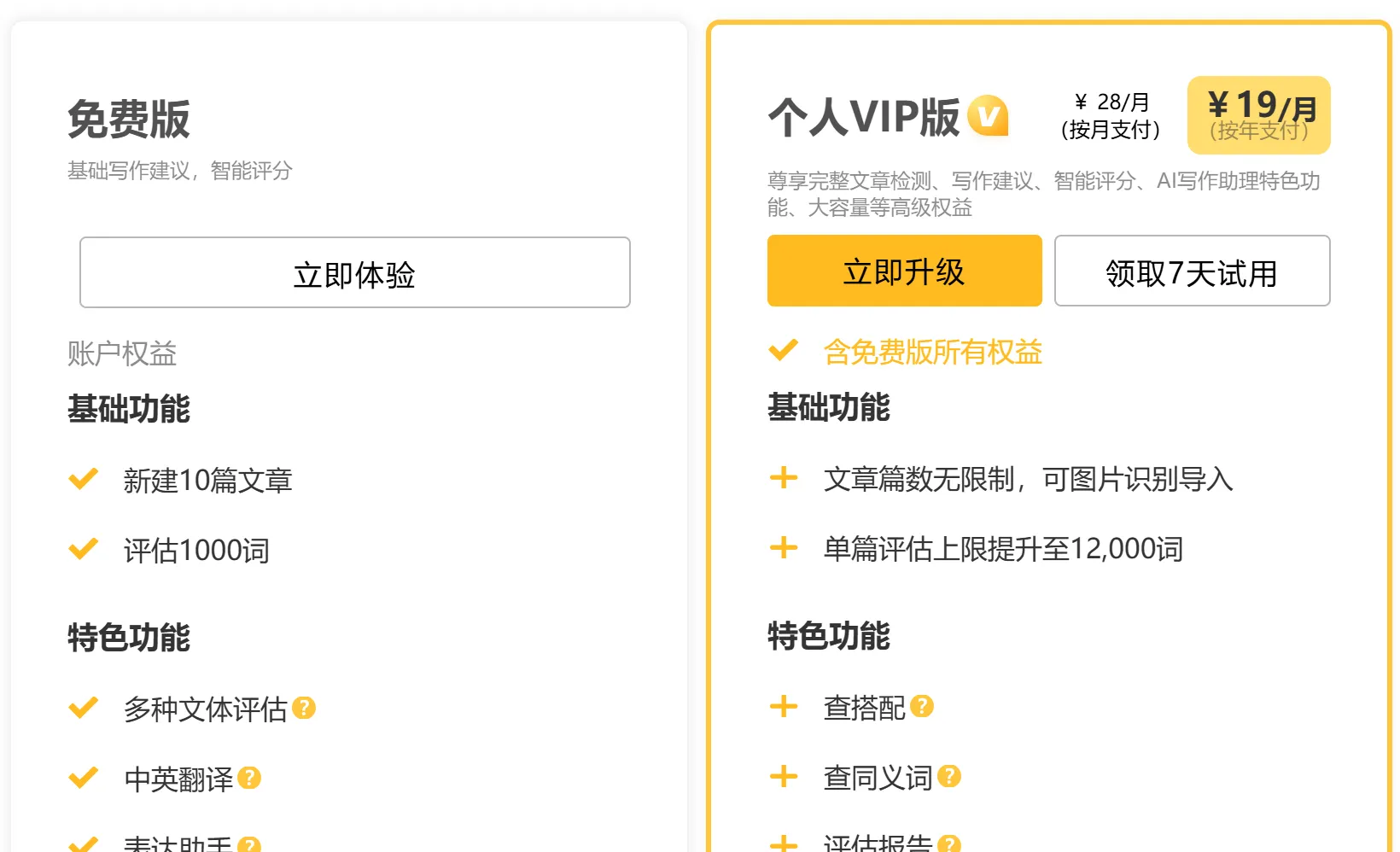
改写匠ReWriter 一款基于AI和深度学习技术的英文写作智能批改工具,可以帮助用户提升英语写作水平,避免中式英语,增强逻辑衔接性,优化语言表达,提升文章质量。 AI写作对话 2025年06月05日 24 点赞 0 评论 822 浏览
FILM Frame Interpolation是一个开源的神经网络模型,能够在两个视频帧之间生成高质量的中间帧,特别适合需要处理大范围场景运动的应用。 Ai视频生成 2026年06月21日 0 点赞 0 评论 824 浏览
TrackVLA TrackVLA是银河通用推出的端到端导航大模型,具备纯视觉环境感知、语言指令驱动、自主推理和零样本泛化能力。它能在复杂环境中自主导航、灵活避障,并根据自然语言指令识别和跟踪目标对象。无需提前建图,适用于多种场景,如陪伴服务、安防巡逻、物流配送等,为具身智能商业化提供支撑,推动机器人走向日常生活。 AI项目与工具 2025年06月11日 79 点赞 0 评论 825 浏览
Bolt3D Bolt3D是由谷歌研究院、牛津大学VGG团队与谷歌DeepMind联合开发的3D场景生成技术,基于潜在扩散模型,能在单块GPU上仅需6.25秒生成高质量3D场景。支持多视角输入,具备良好泛化能力,采用高斯溅射技术实现高保真表示,并支持实时交互。适用于游戏开发、VR/AR、建筑设计和影视制作等领域。 AI项目与工具 2025年06月12日 47 点赞 0 评论 826 浏览