Vision Search Assistant Vision Search Assistant (VSA) 是一种结合视觉语言模型与网络代理的框架,旨在提升模型对未知视觉内容的理解能力。它通过网络检索,使 VLMs 能够处理和回答有关未见图像的问题。VSA 在开放集和封闭集问答测试中表现出色,支持图像描述生成、网络知识搜索、协作生成等功能,可应用于图像识别、新闻分析、教育、电商和旅游等多个领域。 AI项目与工具 2025年06月12日 100 点赞 0 评论 850 浏览
Fineshare VoiceTrans Fineshare VoiceTrans 是一款支持实时变声的 AI 工具,可将声音转换为多种角色或性别,保留原有情感与语调。提供丰富的音效库、声音实验室和预设声音包,适用于游戏、直播、配音等场景。用户可通过不同订阅计划获得无限使用权限和定制服务,提升创作与互动体验。 AI项目与工具 2025年06月12日 24 点赞 0 评论 848 浏览
Fourier N1 Fourier N1是一款由傅利叶推出的开源人形机器人,具备23个自由度,可完成复杂动作如单足站立、坡道通行和楼梯攀爬。搭载自研控制系统和FSA 2.0执行器,支持高速稳定运行。支持多模态交互,适用于教学、康复辅助、物流搬运、家务服务及灾难救援等领域,提供全面的开源资源以支持开发与研究。 AI项目与工具 2025年06月11日 55 点赞 0 评论 846 浏览
AnimateAnything AnimateAnything是一项由浙江大学与北京航空航天大学联合研发的统一可控视频生成技术。它能够根据相机轨迹、文本提示及用户动作注释等多样化控制信号生成高质量视频,并通过多尺度特征融合网络将这些信号转化为逐帧光流进行精准引导。此外,为解决大范围运动带来的视频闪烁问题,该技术采用了基于频率的稳定模块,显著增强了视频的时间稳定性。主要应用于影视制作、虚拟现实、游戏开发以及教育培训等多个领域。 AI项目与工具 2025年06月12日 36 点赞 0 评论 842 浏览
GRUtopia 2.0 GRUtopia 2.0是上海人工智能实验室推出的通用具身智能仿真平台,提供模块化框架、场景自动生成与高效数据采集功能。用户可使用“三行代码”快速定义任务,平台内置百万级标准化物体资产,支持复杂场景的一键生成。同时具备大规模3D场景数据集、AI驱动的NPC系统及基准测试平台,适用于机器人训练、社交互动、导航与操作等任务,推动具身智能从仿真走向现实。 AI项目与工具 2025年06月12日 16 点赞 0 评论 835 浏览
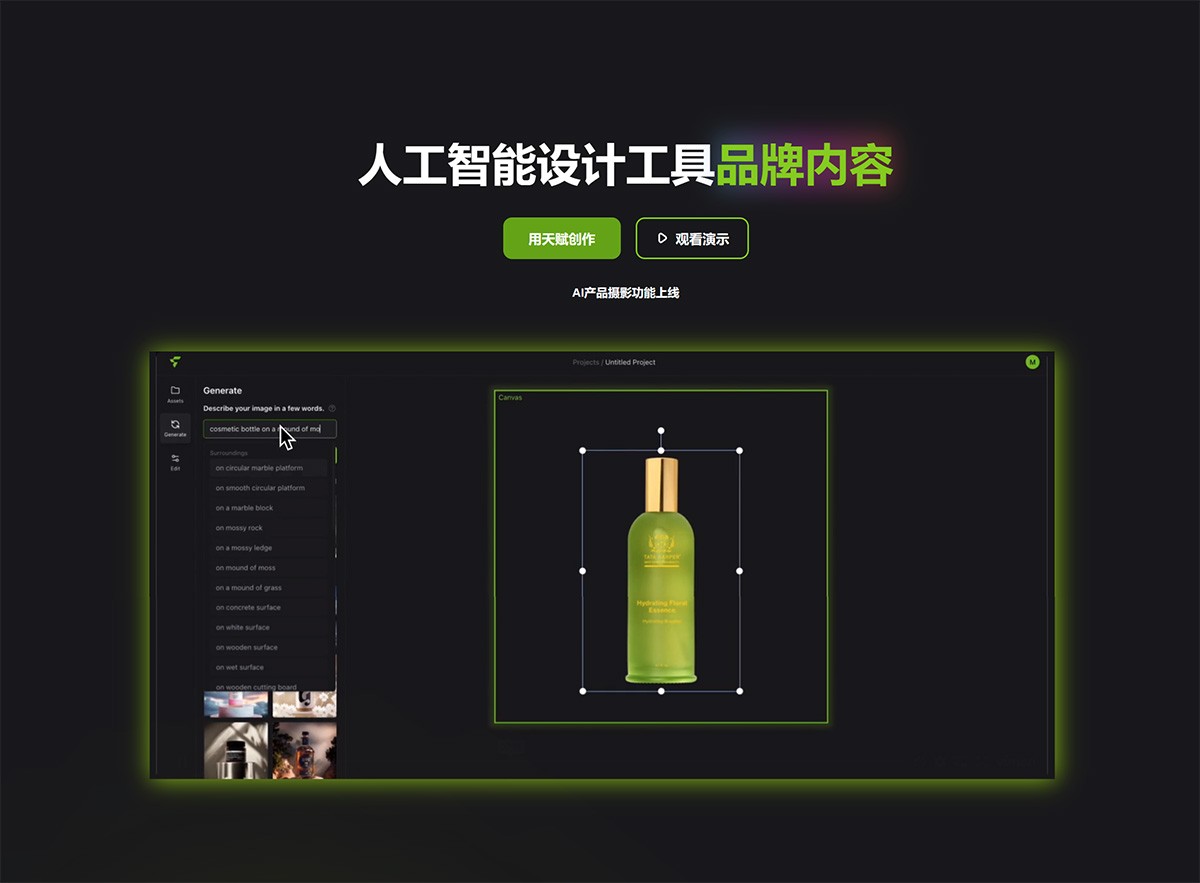
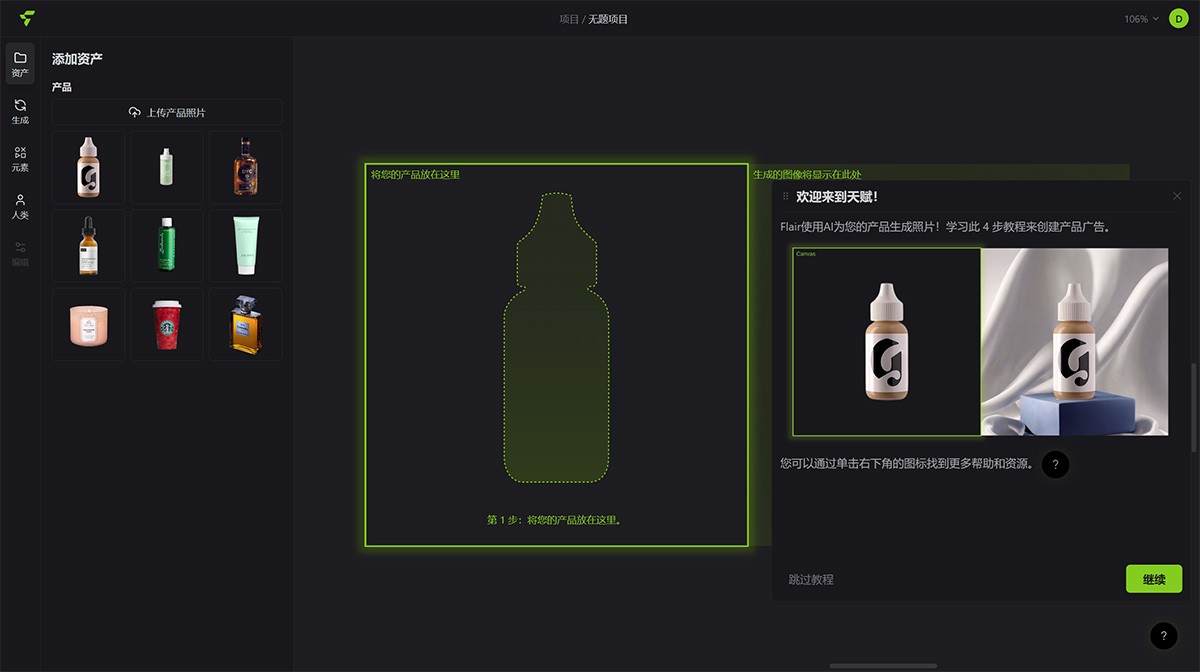
Flair Ai Flair Ai-人工智能产品AI图片生成器 一键成图。 用户只需要上传产品照片,然后使用关键词描述想要的效果,AI即可根据描述自动生成产品照片,而且内置多种模板和元素可选。 Ai绘画生成 2025年06月05日 18 点赞 0 评论 832 浏览
SnapDrop 一款跨平台文件传输工具,具有在同一局域网内通过浏览器实现设备间点对点传输文件、图片、文档或文本,具备跨平台兼容、无需安装,网页即开即用的特点。 网盘传输 2025年06月05日 45 点赞 0 评论 832 浏览