ViewExtrapolator ViewExtrapolator是一种基于稳定视频扩散(SVD)的新视角外推方法,能够生成超出训练视图范围的新视角图像,特别适用于提升3D渲染质量和视觉真实性。该工具通过优化SVD的去噪过程,减少了伪影问题,同时支持多视图一致性生成,无需额外微调即可实现高效的数据和计算性能,广泛适用于虚拟现实、3D内容创作及文物保护等多个领域。 AI项目与工具 2025年06月12日 40 点赞 0 评论 642 浏览
HiFiVFS HiFiVFS是一款基于Stable Video Diffusion框架的高保真视频换脸工具,结合多帧输入与时间注意力机制保障视频稳定性。其核心技术包括细粒度属性学习(FAL)和详细身份学习(DIL),分别用于属性解耦和身份相似性提升。HiFiVFS适用于电影制作、游戏开发、虚拟现实及社交媒体等多个领域,支持高质量的视频换脸操作。 AI项目与工具 2025年06月12日 60 点赞 0 评论 640 浏览
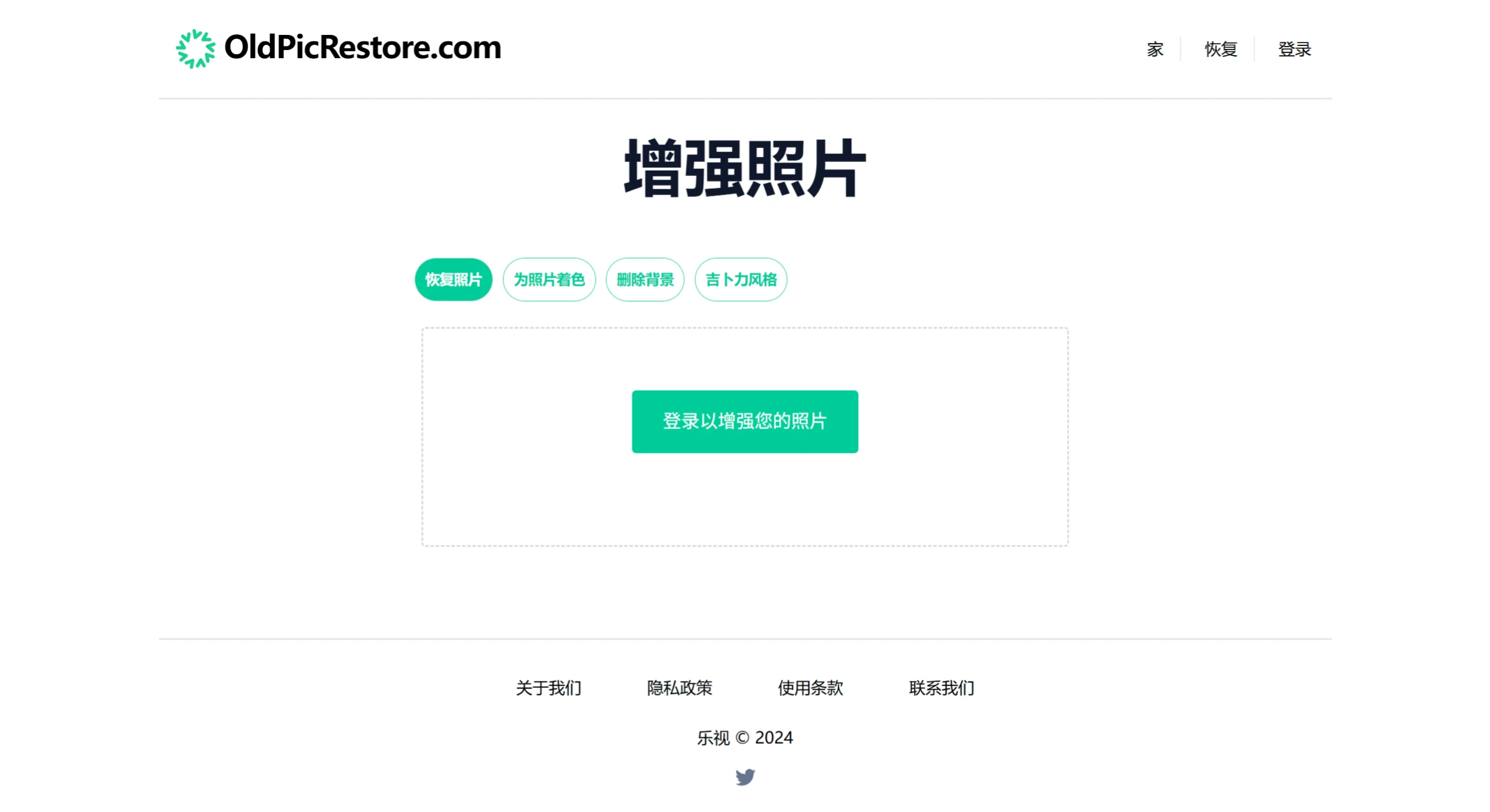
OldPicRestore 一个免费的老照片修复工具,可修复老照片中的损坏、模糊和褪色问题,还能增强照片的清晰度、对比度和色彩饱和度,同时提供去除背景、吉卜力风格转换功能。 Ai图片处理 2025年06月05日 16 点赞 0 评论 639 浏览
PSHuman PSHuman是一款基于跨尺度多视图扩散模型的单图像3D人像重建工具,仅需一张照片即可生成高保真度的3D人体模型,支持全身姿态和面部细节的精确重建。其核心技术包括多视角生成、SMPL-X人体模型融合及显式雕刻技术,确保模型在几何和纹理上的真实感。该工具适用于影视、游戏、VR/AR、时尚设计等多个领域,具备高效、精准和易用的特点。 AI项目与工具 2025年06月12日 49 点赞 0 评论 637 浏览
LuminaBrush LuminaBrush是一款基于深度学习的图像照明生成工具,采用两阶段处理流程:首先提取图像的均匀光照状态,再根据用户涂鸦生成具体光照效果。它支持实时调整光照参数,适用于复杂图像细节处理,广泛应用于数字艺术、游戏设计、影视后期等领域。工具提供交互式界面,便于用户高效创作。 AI项目与工具 2025年06月12日 81 点赞 0 评论 635 浏览