多语言



Autoshorts AI
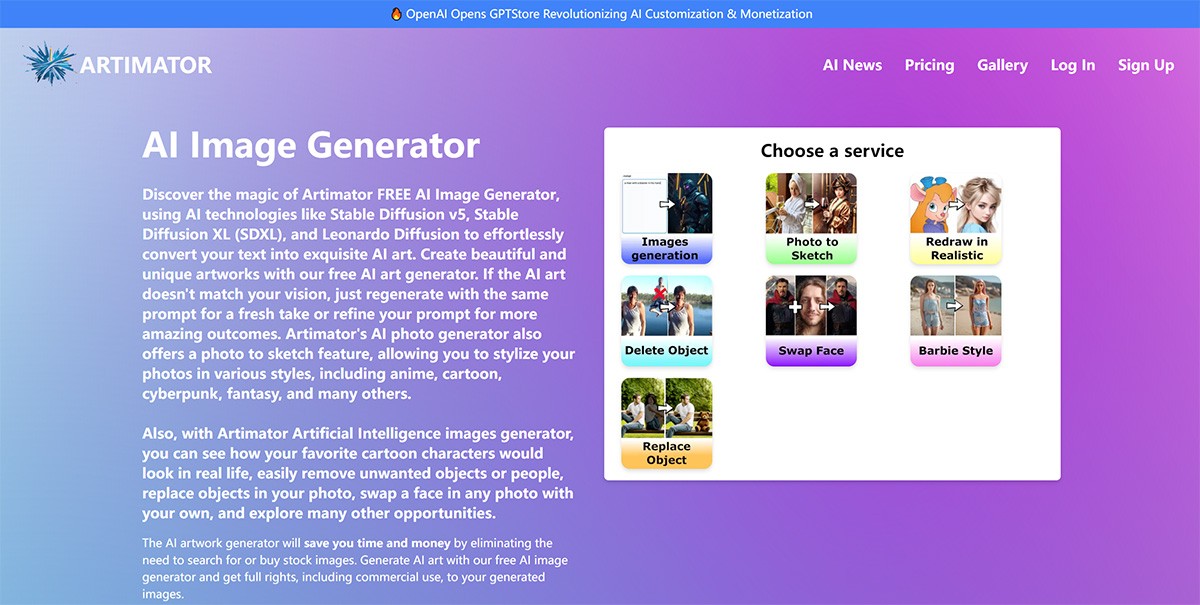
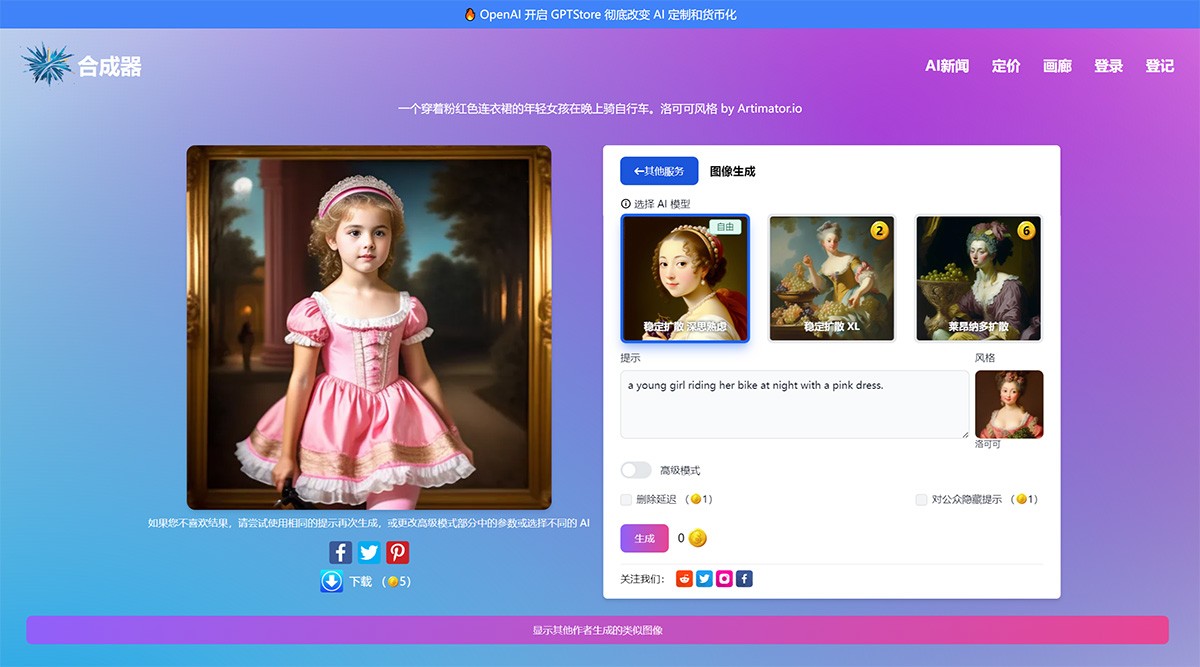
一个将主题和提示转换成简短的垂直视频的全自动视频制作平台。它还支持自动发布到YouTube和 TikTok 并配备可包含音乐的高清输出。



WhisperKeyboard
WhisperKeyboard 是一款基于 OpenAI Whisper 技术的 AI 语音输入工具,支持多语言实时语音转文字,适用于写作、编程、会议记录等场景。具备离线识别、文本润色、多语言翻译和隐私保护等功能,兼容多平台,提升输入效率与文本质量。


Whisper语音识别模型
Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。