Teacher2Task Teacher2Task是一个由谷歌团队研发的多教师学习框架,其核心在于引入教师特定的输入标记并重新构建训练过程,以减少对人工聚合方法的依赖。通过将训练数据转化为多个子任务,该框架能够从不同教师的多样化预测中学习,提高模型的性能和鲁棒性,同时降低标签不准确性的风险。它适用于机器翻译、图像理解、自然语言处理等多个领域,显著提升了数据利用效率。 AI项目与工具 2025年06月12日 39 点赞 0 评论 595 浏览
IMAGDressing IMAGDressing是一款由华为与腾讯合作开发的AI换衣工具,支持用户通过模块化方式设计服装并在虚拟环境中试穿。该工具集成了多种先进技术,包括3D建模、图形渲染、物理模拟、用户交互、机器学习和虚拟现实技术,能够实现高度逼真的虚拟试衣效果。IMAGDressing适用于电子商务、时尚设计、虚拟时尚秀和社交媒体等多种应用场景,能够提高用户体验和工作效率。 AI项目与工具 2025年06月12日 76 点赞 0 评论 595 浏览
Mathtutor on Groq Mathtutor on Groq 是一款基于 Groq 架构的 AI 辅导工具,通过语音识别功能接收数学问题,结合强大的数学引擎提供实时解题过程与答案。其主要功能包括语音输入、LaTeX 公式渲染、高精度计算及自然语言处理支持,适用于代数、微积分等领域的学习与教学辅助。此外,它还集成了 xRx 框架、Whisper 和 Llama 模型,确保高效且精准的问题解决能力。Mathtutor on G AI项目与工具 2025年06月12日 18 点赞 0 评论 595 浏览
书生·筑梦2.0(Vchitect 2.0) 书生·筑梦2.0是一款由上海人工智能实验室开发的开源视频生成大模型,支持文本到视频和图像到视频的转换,生成高质量的2K分辨率视频内容。它具备灵活的宽高比选择、强大的超分辨率处理能力以及创新的视频评测框架,适用于广告、教育、影视等多个领域。 AI项目与工具 2025年06月12日 32 点赞 0 评论 596 浏览
Conbrie Conbrie 是一款基于 AI 的知识整理与学习工具,支持文档解析、知识卡片生成、思维导图创建等功能,帮助用户高效整理和复习知识。具备多平台兼容性和多种文件导出格式,适用于个性化学习、在线教学等多种场景,提升学习效率与知识系统化程度。 AI项目与工具 2025年06月11日 18 点赞 0 评论 596 浏览
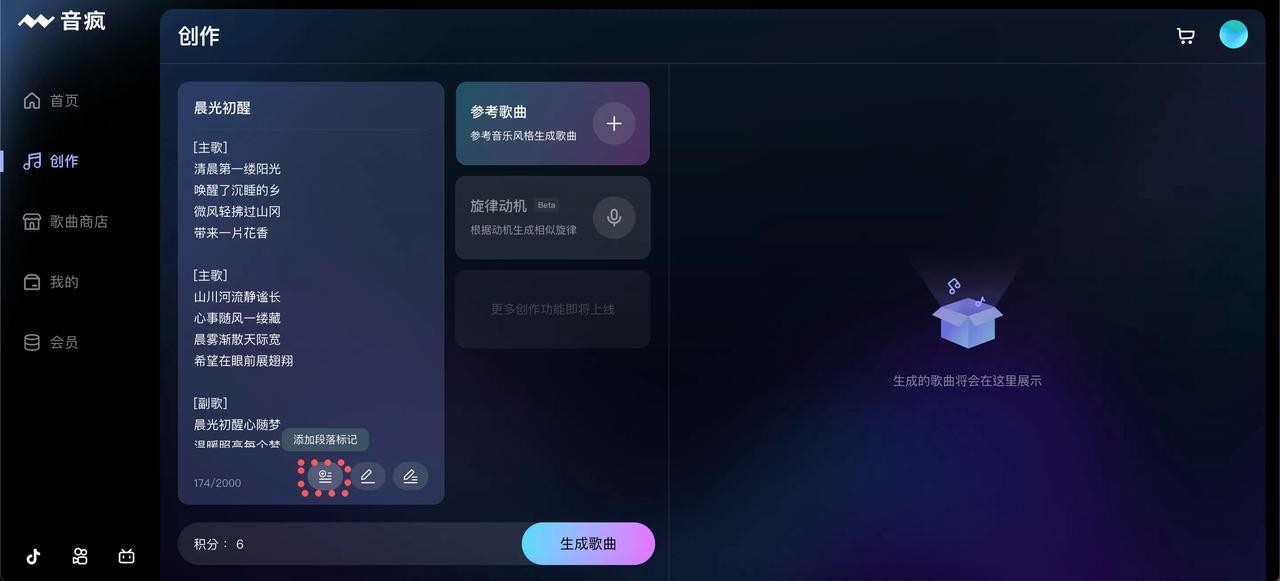
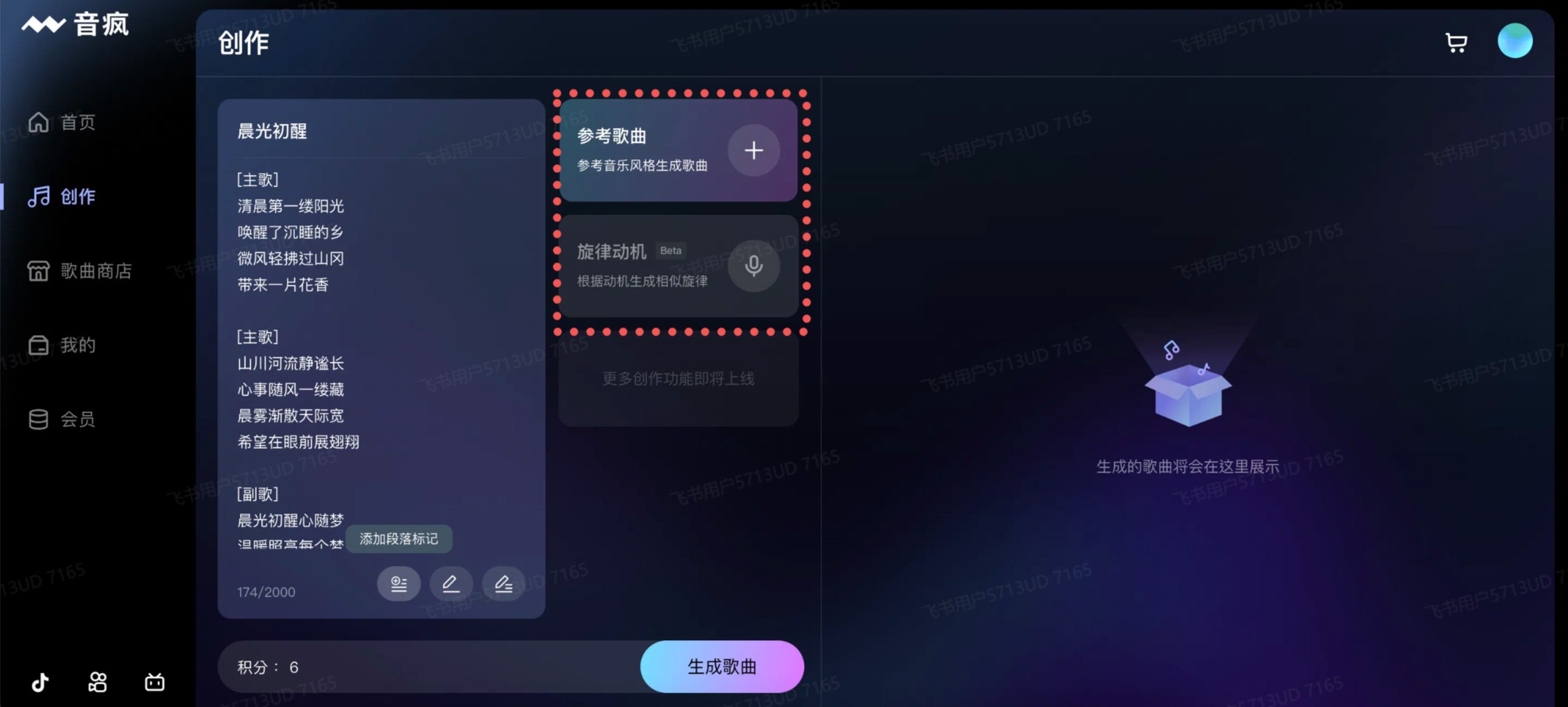
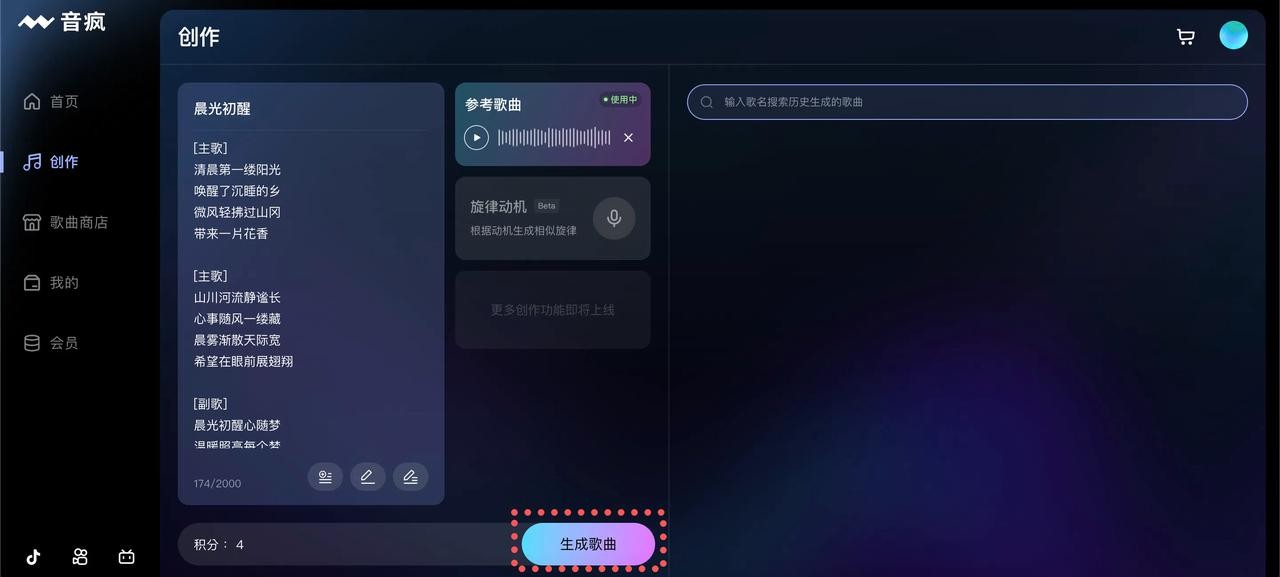
音疯 昆仑万维推出的一个集音乐创作、分享、学习和销售于一体的AI音乐生成平台,用户可以在平台上输入歌词,一键生成专属的歌曲,还可以通过参考其他音乐来生成相似风格的作品。 Ai语音工具 2025年06月05日 100 点赞 0 评论 596 浏览
Call Annie Call Annie是一款基于AI技术的对话工具,通过视频通话形式提供虚拟AI助手Annie,支持实时交流和多种应用场景。主要功能包括实时视频通话、自然语言处理、个性化协助和多平台访问,适用于语言学习、情感陪伴、信息查询、旅行规划、教育辅导及职业发展等场景。 AI项目与工具 2025年06月12日 95 点赞 0 评论 597 浏览
CustomVideoX CustomVideoX是一种基于视频扩散变换器的个性化视频生成框架,能够根据参考图像和文本描述生成高质量视频。其核心技术包括3D参考注意力机制、时间感知注意力偏差(TAB)和实体区域感知增强(ERAE),有效提升视频的时间连贯性和语义一致性。支持多种应用场景,如艺术设计、广告营销、影视制作等,具备高效、精准和可扩展的特点。 AI项目与工具 2025年06月12日 98 点赞 0 评论 597 浏览
BFS BFS-Prover 是一种基于大语言模型的自动定理证明系统,通过改进广度优先搜索算法和长度归一化评分机制,提高证明搜索效率。系统结合专家迭代、直接偏好优化和分布式架构,支持复杂定理的高效验证,并与 Lean4 深度集成,确保形式化数学问题的逻辑正确性。适用于数学竞赛题、本科及研究生数学研究等领域,推动了自动定理证明技术的发展。 AI项目与工具 2025年06月12日 75 点赞 0 评论 598 浏览