E言易图 E言易图,基于Apache Echarts的数据洞察和图表制作、文心一言里一款强大的数据可视化插件,目前支持柱状图、折线图、饼图、雷达图、散点图、漏斗图、思维导图等。 思维导图 2025年06月05日 39 点赞 0 评论 520 浏览
Pyecharts pyecharts-gallery是什么?pyecharts-gallery 是一个基于 pyecharts 的开源项目,它通过模仿 ECharts 官方示例, Ai办公效率 2025年06月05日 67 点赞 0 评论 519 浏览
Zapier Zapier是一个强大的自动化工具,它通过简化工作流程,帮助用户节省时间并提高效率。它的易用性、广泛的集成选项和强大的技术支持,使其成为现代企业扩展自动化的理想选择。 创作工具 2026年06月21日 0 点赞 0 评论 519 浏览
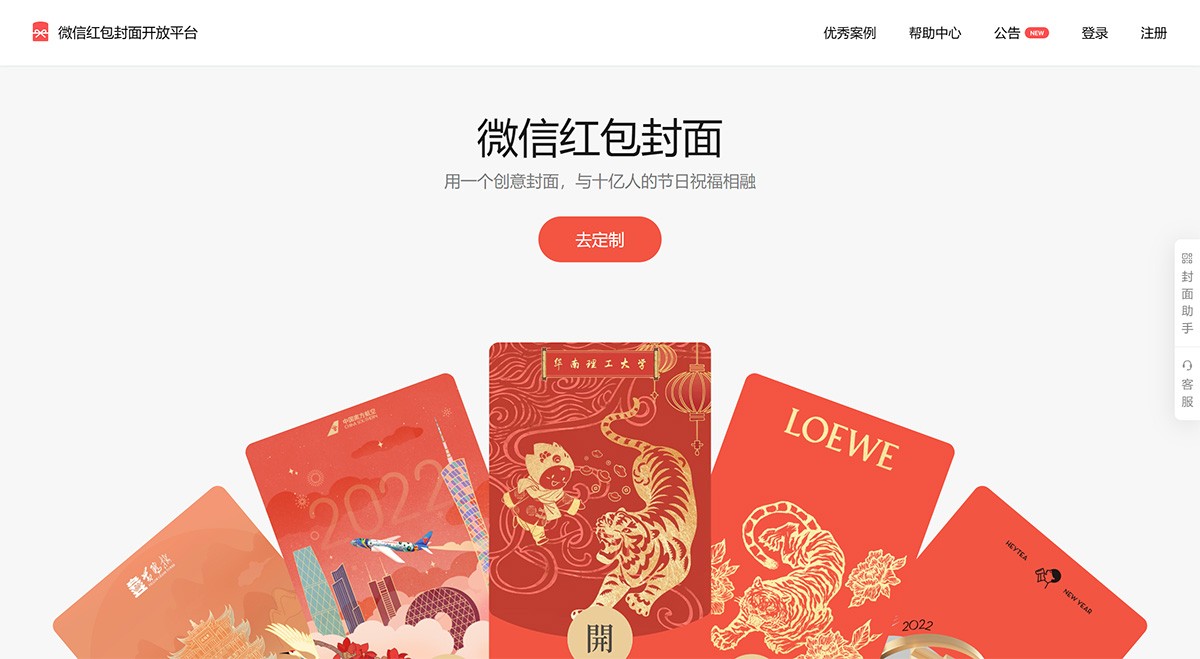
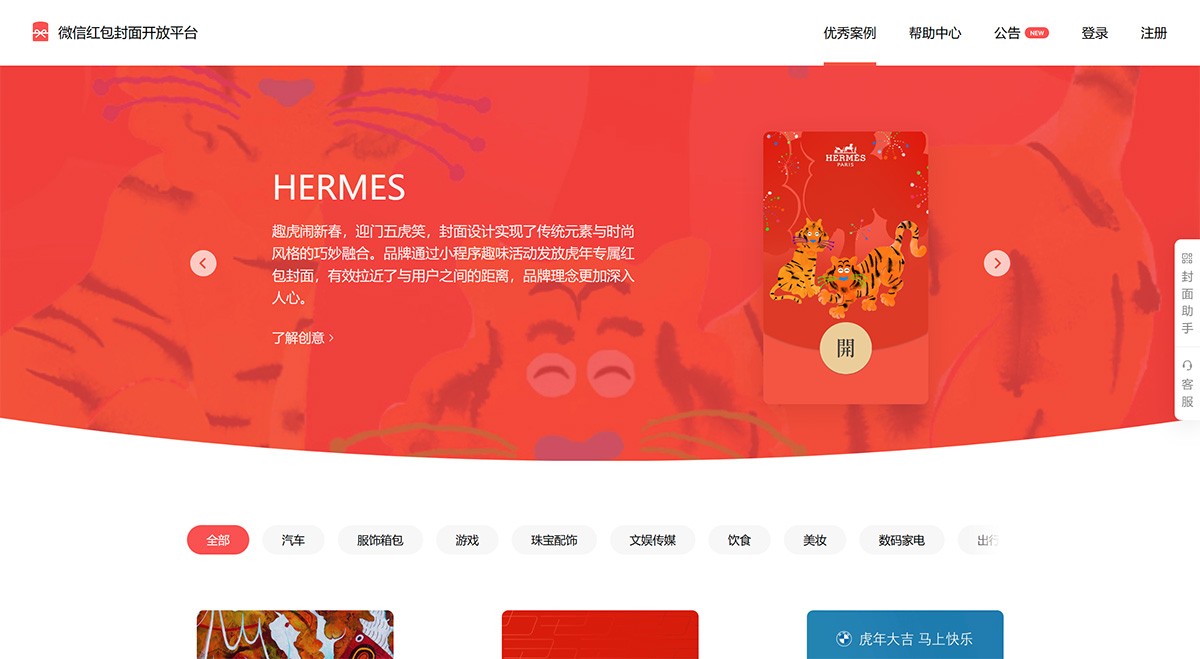
微信红包封面开放平台 是微信红包面向品牌主开放的封面付费定制平台。 在这里,经过认证的定制方可自主设计封面样式、创建封面故事,并通过自有渠道发放给微信用户。 图片处理 2025年06月05日 24 点赞 0 评论 518 浏览
See3D See3D是一款基于视觉条件技术的3D生成模型,能够通过大规模无标注的互联网视频学习3D先验知识,实现从文本、单视图或稀疏视图到3D内容的高效转化。其核心功能包括3D编辑、高斯渲染及基于稀疏图片的3D重建,支持在物体级与场景级复杂相机轨迹下生成长序列视图。此外,See3D还适用于游戏开发、建筑设计、电商展示、AR/VR等多个领域的创新应用。 AI项目与工具 2025年06月12日 25 点赞 0 评论 518 浏览
ModelEngine ModelEngine 是华为开源的全流程 AI 开发工具链,涵盖数据处理、模型训练与应用开发三大核心模块。支持多模态数据清洗、知识向量化及模型推理,提供低代码编排和 RAG 框架,适用于医疗、金融、制造等领域的 AI 应用开发与行业化落地。 AI项目与工具 2025年06月12日 75 点赞 0 评论 517 浏览
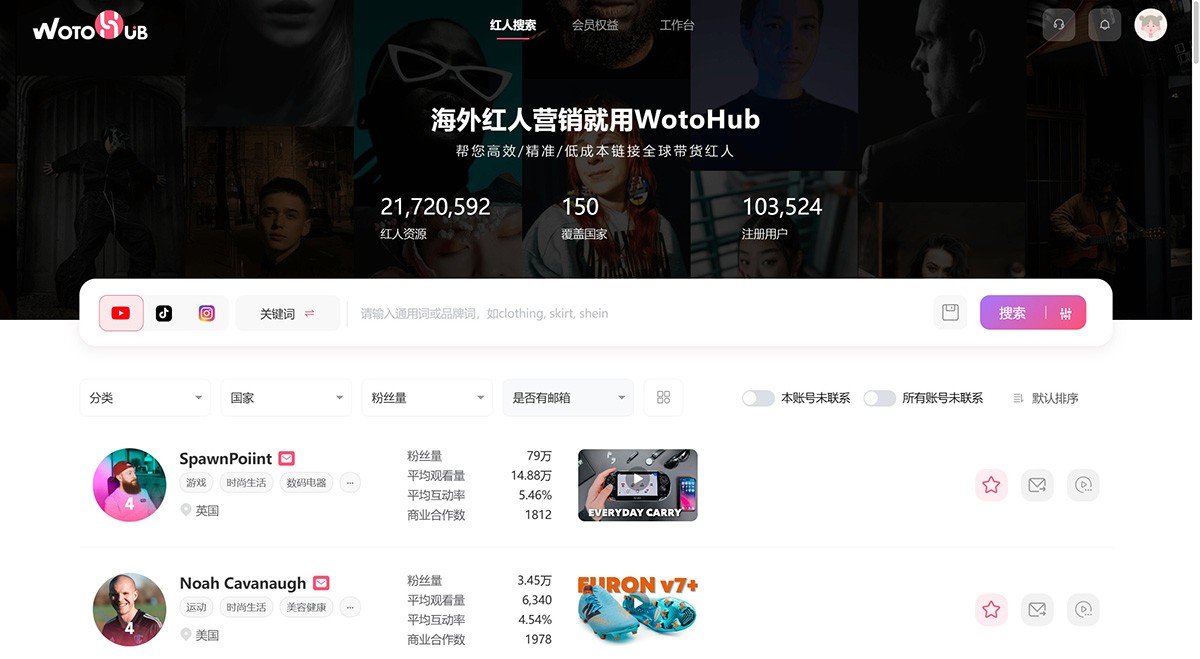
WotoHub 一款覆盖海外红人检索、商业价值分析、营销自动化、竞品数据洞察、带货数据监控的saas产品,帮助您完整构建海外红人营销体系,抢占海外社媒营销流量高地。 红人营销 2025年06月05日 32 点赞 0 评论 516 浏览
andu.ai 案牍AI是一款基于大型语言模型技术开发的法律智能化工具,提供合同审查、尽职调查、穿透核查等功能,支持自定义规则与模板,并通过持续学习优化审查质量,保障数据安全与合规性。它适用于IPO核查、企业内部法律合规及法务管理等场景,助力提升工作效率与准确性。 AI项目与工具 2025年06月12日 43 点赞 0 评论 516 浏览
Xyne 一款日常办公工的智能搜索问答工具,Xyne整合了工作中的各种数据,可以高效查找各种文件、邮件、聊天记录、应用工具等数据并智能回答。 AI搜索问答 2025年06月05日 87 点赞 0 评论 516 浏览