模型
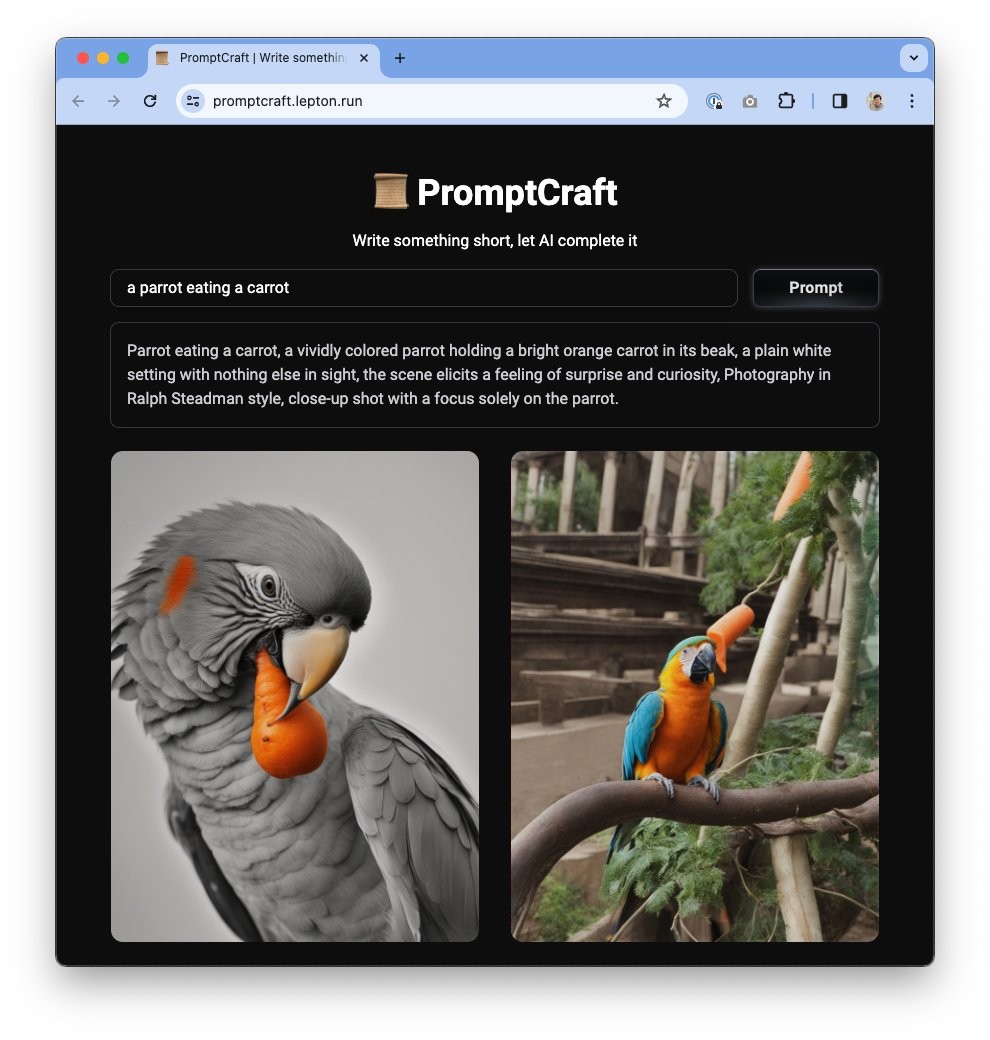
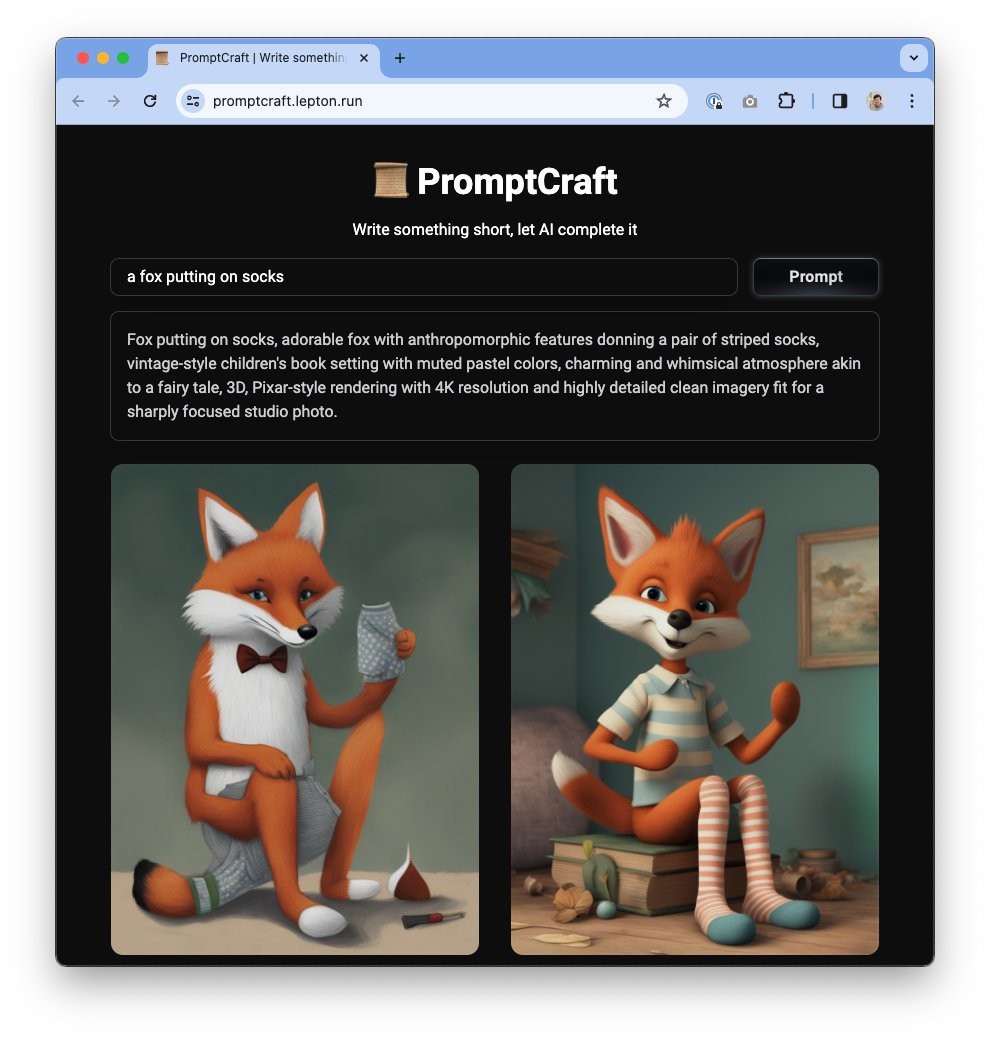

SketchVideo
SketchVideo是一款基于草图和文本提示的视频生成与编辑框架,由多所高校与企业联合研发。它利用DiT模型和草图控制网络,实现对视频内容的精细控制,支持动态调整与细节保留。该工具适用于多种场景,如影视制作、教育、游戏开发等,具备高效生成与高质量输出能力。

月之暗面Moonshot AI
一家专注于人工智能技术的公司,由杨植麟于2023年3月创立。公司致力于开发大型AI模型,其核心产品是Kimi智能助手。







Quasar Alpha
Quasar Alpha是一款预发布AI模型,具备100万token的超大上下文窗口,可高效处理长文本和复杂文档。其在代码生成、指令遵循、多模态处理等方面表现出色,支持联网搜索以增强信息准确性。适用于代码开发、长文本分析、创意写作及智能问答等多种场景,目前可通过OpenRouter平台免费使用,存在一定请求限制。

