Chatterbox Chatterbox是Resemble AI推出的开源文本转语音(TTS)模型,基于0.5B规模的LLaMA架构,用超过50万小时精选音频训练。它支持零样本语音克隆,仅需5秒参考音频即可生成高度逼真的个性化语音,并具备情感夸张控制功能,可调节情绪、语速和语调。Chatterbox还拥有超低延迟的实时语音合成能力,延迟低至200毫秒以下,适用于交互式应用。此外,它采用安全水印技术防止滥用,适用于内容 AI项目与工具 2025年06月11日 55 点赞 0 评论 514 浏览
GameGen GameGen-O 是一款基于 Transformer 架构的AI工具,专注于开放世界游戏视频的生成。它具备角色生成、环境构建、动作模拟及交互式控制等功能,通过两阶段训练方法提升了生成质量和灵活性,可应用于游戏原型设计、场景生成及开发辅助等领域,有助于降低开发成本并提高创作效率。 AI项目与工具 2025年06月12日 17 点赞 0 评论 515 浏览
AudioX AudioX 是一种基于多模态输入的音频生成模型,支持文本、视频、图像等多种输入方式,能够生成高质量的音频和音乐。其核心创新在于多模态掩码训练策略,提升了跨模态理解和生成能力。具备零样本生成、自然语言控制及强大的泛化能力,适用于视频配乐、动画音效、音乐创作等多个场景。 AI项目与工具 2025年06月12日 68 点赞 0 评论 516 浏览
Half_illustration Half_illustration 是一款基于 Flux.1 模型的 LoRA 图像创意工具,融合了摄影写实与插画艺术的元素,创造出独特的视觉效果。该工具支持通过 API 快速生成图像,并与 Diffusers 库兼容。用户可通过详细描述和特定提示词指导模型,实现个性化的艺术创作。其应用广泛,涵盖时尚编辑、广告设计、概念艺术等多个领域。 AI项目与工具 2025年06月12日 55 点赞 0 评论 516 浏览
Deep Paint 3D Deep Paint 3D是一个为 Blender 这个 3D 制作软件设计的插件。可以在 3D 中交互式地绘制 3D 模型并为其添加纹理。它使用可以直接刷涂或投影到 3D 模型和场景上的纹理或自然介质。 3D&游戏 2025年06月05日 100 点赞 0 评论 516 浏览
Mobile Mobile-Agent 是一种具备移动能力的智能代理系统,能够跨设备执行任务并优化资源使用。基于多模态大语言模型和视觉感知技术,支持自动操作、自我规划与反思,适用于多应用协同、跨平台操作及纯视觉交互。其技术架构包含多个智能体协作机制,提升了移动设备任务处理的效率与灵活性。 AI项目与工具 2025年06月12日 18 点赞 0 评论 516 浏览
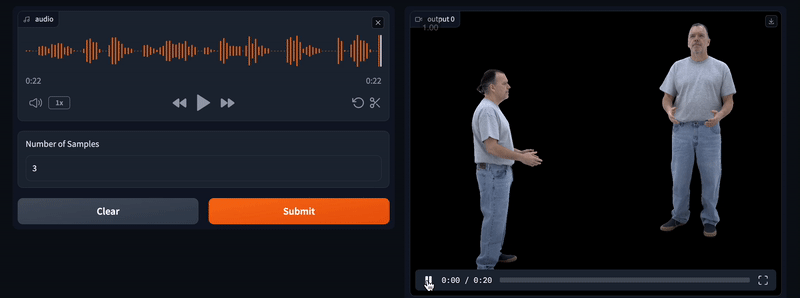
Audio2Photoreal 从音频生成全身逼真的虚拟人物形象。它可以从多人对话中语音中生成与对话相对应的逼真面部表情、完整身体和手势动作。 Ai开源项目 2025年06月05日 77 点赞 0 评论 516 浏览
AgentReview AgentReview是一款基于大型语言模型构建的学术同行评审模拟工具,通过模拟评审者、作者和领域主席的角色,研究评审偏见和决策机制对评审结果的影响。它支持隐私保护,无需真实敏感数据,同时验证了多种社会学理论在评审中的应用,为优化学术评审流程提供了重要参考。 AI项目与工具 2025年06月12日 17 点赞 0 评论 516 浏览
星环无涯•金融大模型 星环无涯•金融大模型是一个综合性的金融投研工具,它通过先进的数据分析和自然语言处理技术,为专业投资者和机构提供了深入的市场分析、策略构建和投资决策支持。 创作工具 2026年06月21日 0 点赞 0 评论 517 浏览