EasyControl EasyControl是基于扩散变换器(DiT)架构的高效控制框架,采用轻量级LoRA模块实现多条件控制,支持图像生成、风格转换、动画制作等任务。其具备位置感知训练范式和因果注意力机制,优化计算效率,提升生成质量与灵活性,适用于多种图像处理场景。 AI项目与工具 2025年06月12日 48 点赞 0 评论 844 浏览
讯飞星辰MaaS 讯飞星辰MaaS是一个AI大模型定制微调平台,提供从数据管理到模型微调、评估、托管及推理服务的全流程支持。平台支持多种行业知名模型的零代码微调,具有高度灵活性和可扩展性,适用于逻辑推理、数据管理和多模态应用等场景,为企业提供高效、专业的AI解决方案。 AI项目与工具 2025年06月12日 88 点赞 0 评论 844 浏览
Gemma 2 Gemma 2是一款由谷歌DeepMind开发的开源人工智能模型,提供90亿和270亿参数版本。它具有卓越的性能、高效的推理速度和广泛的硬件兼容性,适用于各种应用场景。Gemma 2不仅支持多种AI框架,还提供了丰富的资源和工具,以支持开发者和研究人员负责任地构建和部署AI。 AI项目与工具 2025年06月12日 57 点赞 0 评论 844 浏览
SketchVideo SketchVideo是一款基于草图和文本提示的视频生成与编辑框架,由多所高校与企业联合研发。它利用DiT模型和草图控制网络,实现对视频内容的精细控制,支持动态调整与细节保留。该工具适用于多种场景,如影视制作、教育、游戏开发等,具备高效生成与高质量输出能力。 AI项目与工具 2025年06月11日 83 点赞 0 评论 844 浏览
TripoSF TripoSF是由VAST推出的新型3D基础模型,采用SparseFlex表示方法和稀疏体素结构,显著降低内存占用并提升高分辨率建模能力。其“视锥体感知的分区体素训练”策略优化了训练效率,使模型在细节捕捉、拓扑结构支持和实时渲染方面表现突出。实验数据显示,TripoSF在Chamfer Distance和F-score等关键指标上分别降低82%和提升88%。适用于视觉特效、游戏开发、具身智能及产品 AI项目与工具 2025年06月12日 71 点赞 0 评论 844 浏览
VisoMaster VisoMaster 是一款基于 AI 的面部编辑与换脸工具,支持图片、视频及直播场景,能生成自然逼真的换脸效果。采用 GPU 加速与自定义模型功能,适用于影视、广告、视频创作等领域。核心技术包括深度学习与 GANs,实现高精度面部特征提取与图像合成,支持实时预览与参数调整,提升用户体验与效率。 AI项目与工具 2025年06月12日 82 点赞 0 评论 843 浏览
月之暗面Moonshot AI 一家专注于人工智能技术的公司,由杨植麟于2023年3月创立。公司致力于开发大型AI模型,其核心产品是Kimi智能助手。 Ai科技公司 2025年06月05日 50 点赞 0 评论 843 浏览
AgiBot Digital World AgiBot Digital World 是一款基于 NVIDIA Isaac-Sim 的高保真机器人仿真框架,支持多模态大模型驱动的任务与场景自动生成,具备真实感强的视觉与物理模拟能力。其提供多样化专家轨迹生成、域随机化与数据增强功能,助力机器人技能训练与算法优化,并开源了包含多种场景和技能的数据集,适用于工业自动化、服务机器人开发及人工智能研究等领域。 AI项目与工具 2025年06月12日 63 点赞 0 评论 843 浏览
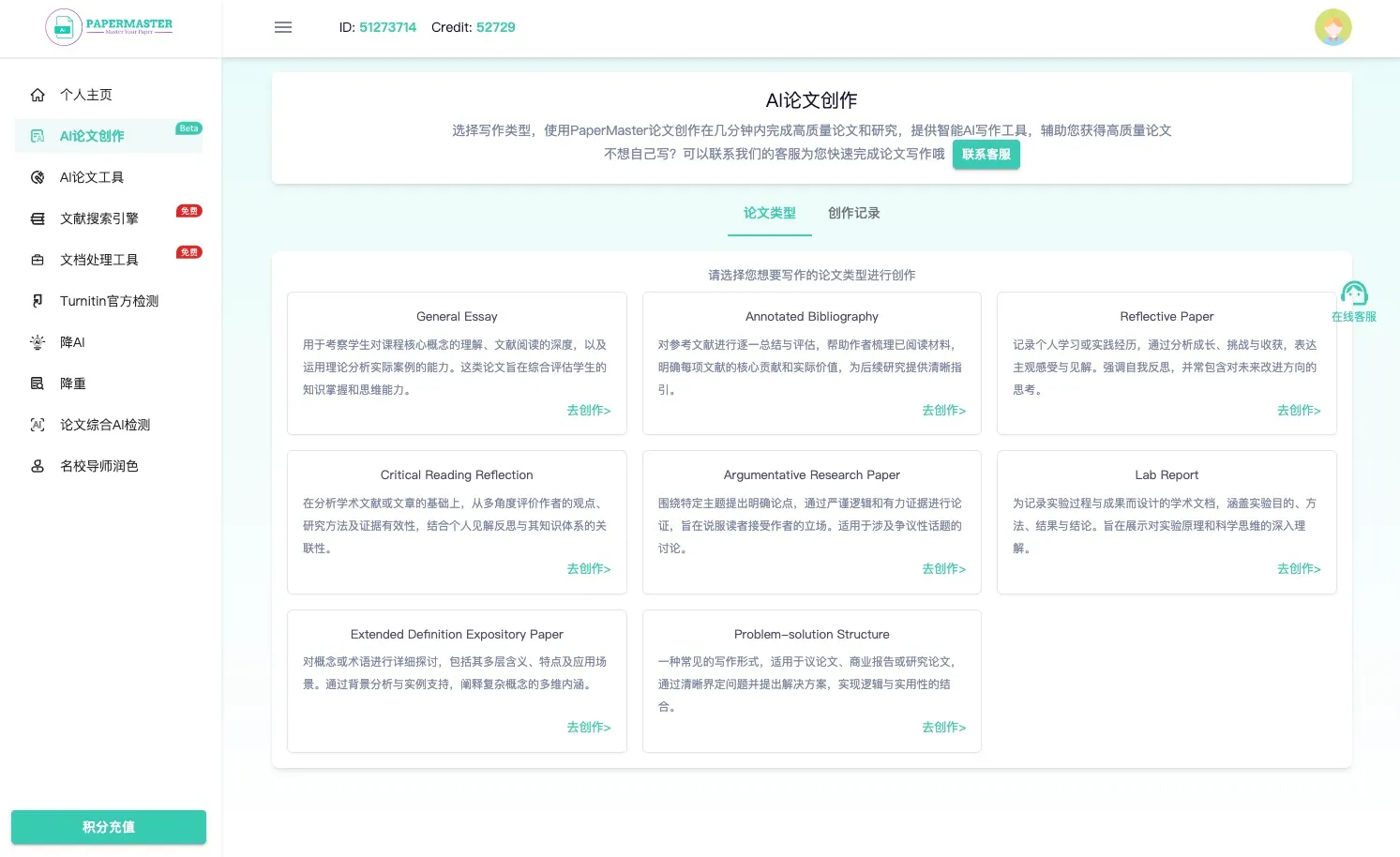
PaperMaster AI 安全、专业、权威的全体系论文解决方案,PaperMaster通过AI快速生成高质量的学术论文和研究报告,并提供论文创作、查重检测和降重服务等功能。 教育学习 2025年06月05日 93 点赞 0 评论 843 浏览