Emu Video Meta开发的文本到视频生成模型,Emu Video使用扩散模型根据文本提示创建视频,首先生成图像,然后根据文本和生成的图像创建视频。 Ai视频生成 2025年06月05日 40 点赞 0 评论 575 浏览
S2V S2V-01是MiniMax研发的视频生成模型,基于单图主体参考架构,可快速生成高质量视频。它能精准还原图像中的面部特征,保持角色一致性,并通过文本提示词灵活控制视频内容。支持720p、25fps高清输出,具备电影感镜头效果,适用于短视频、广告、游戏、教育等多种场景,具有高效、稳定和高自由度的特点。 AI项目与工具 2025年06月12日 100 点赞 0 评论 575 浏览
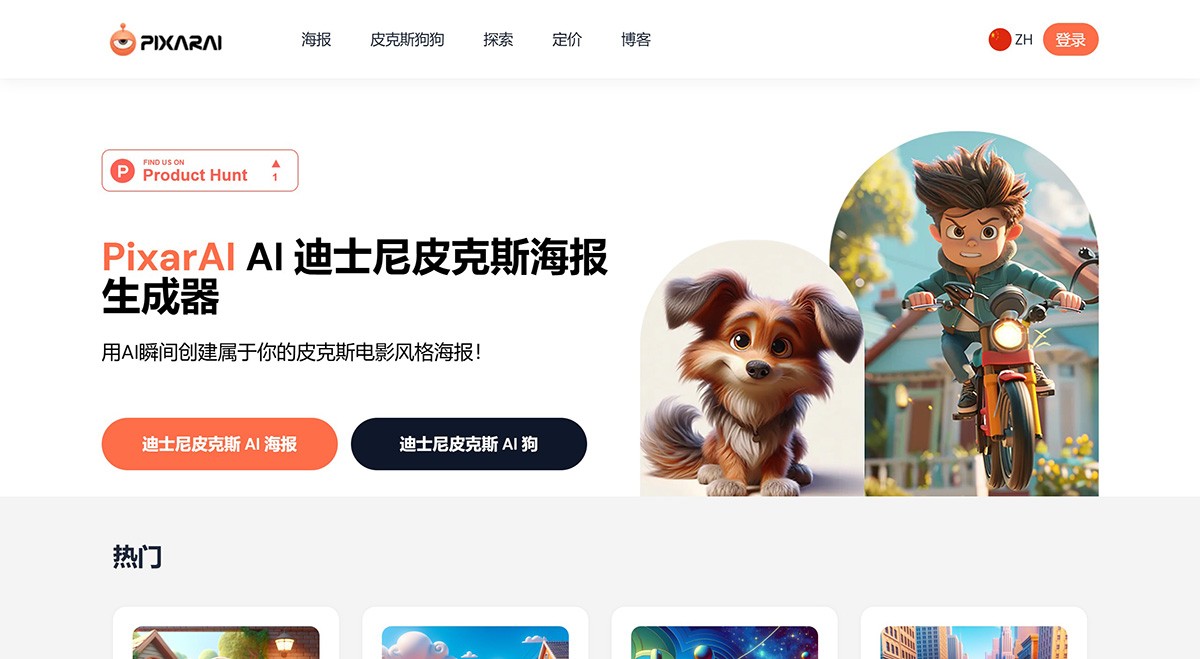
PixarAI PixarAI 一个可以为您喜欢的角色或宠物生成迪士尼皮克斯风格海报的网站 链接传送门->https://www.pixarai.com PixarAI Ai绘画生成 2025年06月05日 80 点赞 0 评论 575 浏览
Video Video-LLaVA2是一款由北京大学ChatLaw课题组开发的开源多模态智能理解系统。该系统通过时空卷积(STC)连接器和音频分支,显著提升了视频和音频的理解能力。其主要功能包括视频理解、音频理解、多模态交互、视频问答和视频字幕生成。时空建模和双分支框架是其核心技术原理。Video-LLaVA2广泛应用于视频内容分析、视频字幕生成、视频问答系统、视频搜索和检索、视频监控分析及自动驾驶等领域。 AI项目与工具 2025年06月12日 50 点赞 0 评论 575 浏览
FantasyID FantasyID是由阿里巴巴集团与北京邮电大学联合开发的视频生成框架,基于扩散变换器和3D面部几何先验,实现高质量、身份一致的视频生成。其通过多视角增强和分层特征注入技术,提升面部动态表现,同时保持身份稳定性。支持多种应用场景,如虚拟形象、内容创作和数字人交互,具备无需微调的高效生成能力。 AI项目与工具 2025年06月12日 81 点赞 0 评论 576 浏览