MagicVideo MagicVideo-V2是一款由字节跳动公司团队开发的AI视频生成模型和框架。该模型通过集成文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块,实现了从文本到高保真视频的转换。生成的视频不仅具有高分辨率,而且在视觉质量和运动流畅度方面表现出色,为用户提供卓越的观看体验。 AI项目与工具 2024年01月01日 56 点赞 0 评论 907 浏览
Composio Composio 是一款专为简化 AI 智能体开发和部署设计的辅助工具,支持超过100种集成工具,通过简单的代码调用多种工具和框架。它提供丰富的 API 和插件系统,支持多种身份验证协议,适用于自动化软件开发、内容管理、数据管理等多种场景,帮助开发者构建和管理高效的 AI 智能体。 AI项目与工具 2025年06月12日 89 点赞 0 评论 905 浏览
OCode OCode 是终端原生 AI 编程助手,为开发者提供深度代码库智能和自动任务执行功能。它与本地 Ollama 模型无缝集成,支持多文件重构、项目理解、开发自动化、数据处理、系统操作、交互式操作、文件操作、文本处理和开发工具等功能。OCode 通过终端原生工作流、深度代码库智能、自动任务执行、直接 Ollama 集成和可扩展插件层提升编程效率和质量,适用于前端开发、设计与开发协作、无代码开发、数据管 AI项目与工具 2025年06月11日 61 点赞 0 评论 905 浏览
LTXV LTXV-13B 是 Lightricks 推出的开源 AI 视频生成模型,拥有 130 亿参数,可在消费级显卡上高效运行,生成速度比同类产品快 30 倍。支持文本、图像转视频及多关键帧调节,具备多尺度渲染和高压缩率技术,适用于影视、广告、游戏、教育等多个领域,提升内容创作效率与质量。 AI项目与工具 2025年06月11日 18 点赞 0 评论 905 浏览
SmoothCache SmoothCache是一种针对Diffusion Transformers(DiT)模型的推理加速技术,通过分析层输出的相似性实现自适应缓存和特征重用,有效减少计算成本并提升生成效率。该技术具有模型无关性、跨模态适用性和易于集成的特点,支持图像、视频、音频及3D模型生成,并在多种应用场景中展现出卓越的性能表现。 AI项目与工具 2025年06月12日 52 点赞 0 评论 904 浏览
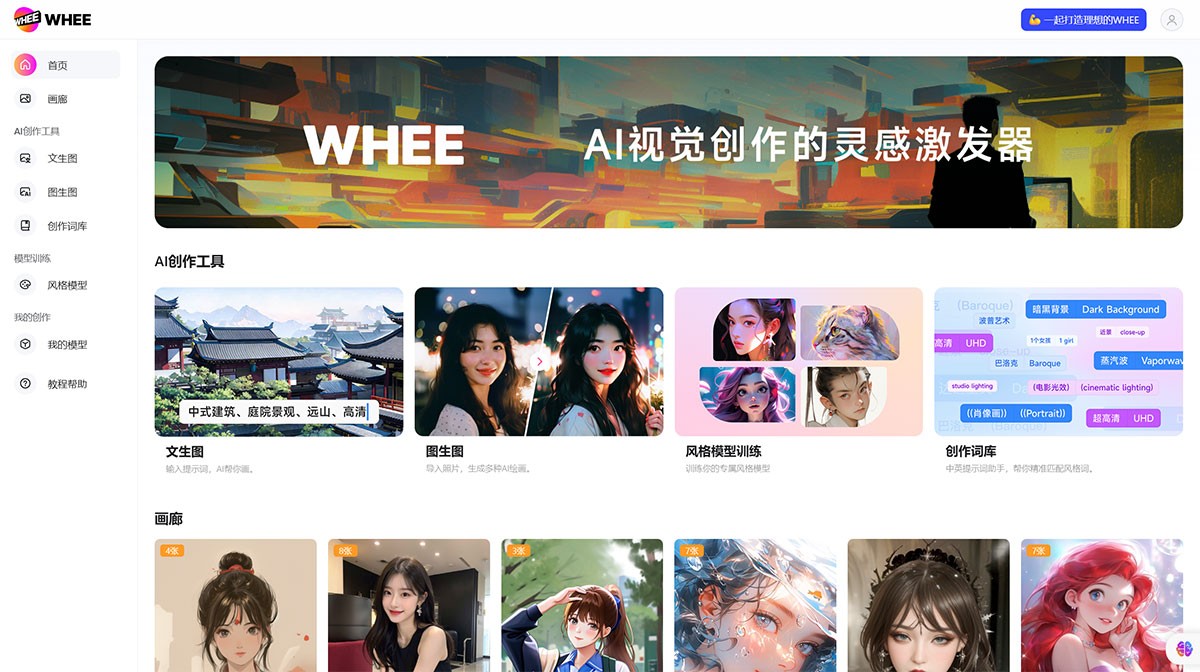
美图Whee 美图Whee是美图旗下AI绘画平台,提供文生图和图生图功能,你只需要输入提示词,AI就能根据提示词画出对应的图象,也可以导入一张照片,Al会生成多种风格的绘画。 Ai绘画生成 2025年06月05日 51 点赞 0 评论 903 浏览
Wepost Wepost是一款AI驱动的社交媒体营销工具,支持内容创作、发布与分析。它能生成符合品牌调性的文案、图像和视频,支持多平台同步发布,并提供内容日历、数据分析和优化建议等功能。平台还具备团队协作能力,便于多人协同管理内容,确保品牌一致性,适用于企业、代理机构及个人营销人员。 AI项目与工具 2025年06月12日 17 点赞 0 评论 903 浏览
Animate Anyone Animate Anyone是一款由阿里巴巴智能计算研究院开发的开源框架,旨在将静态图像中的角色或人物动态化。它采用扩散模型,结合ReferenceNet、Pose Guider姿态引导器和时序生成模块等技术,确保输出的动态视频具有高度一致性和稳定性。该框架支持多种应用,包括角色动态化、时尚视频合成及人类舞蹈生成,用户可通过GitHub或Hugging Face社区轻松体验。 AI项目与工具 2025年06月12日 19 点赞 0 评论 903 浏览