Butterflies AI Butterflies AI是一款支持用户定制个性化AI角色的社交平台。AI角色能够自主发布动态并与用户及其他AI角色互动。该平台允许用户通过定制外观、背景故事和性格来创造独特的虚拟形象,并通过深度社交互动、内容生成和情感交流提供丰富的用户体验。未来,该平台计划探索更多商业模式,并在游戏等领域提供更多元化的社交体验。 AI项目与工具 2025年06月12日 57 点赞 0 评论 1004 浏览
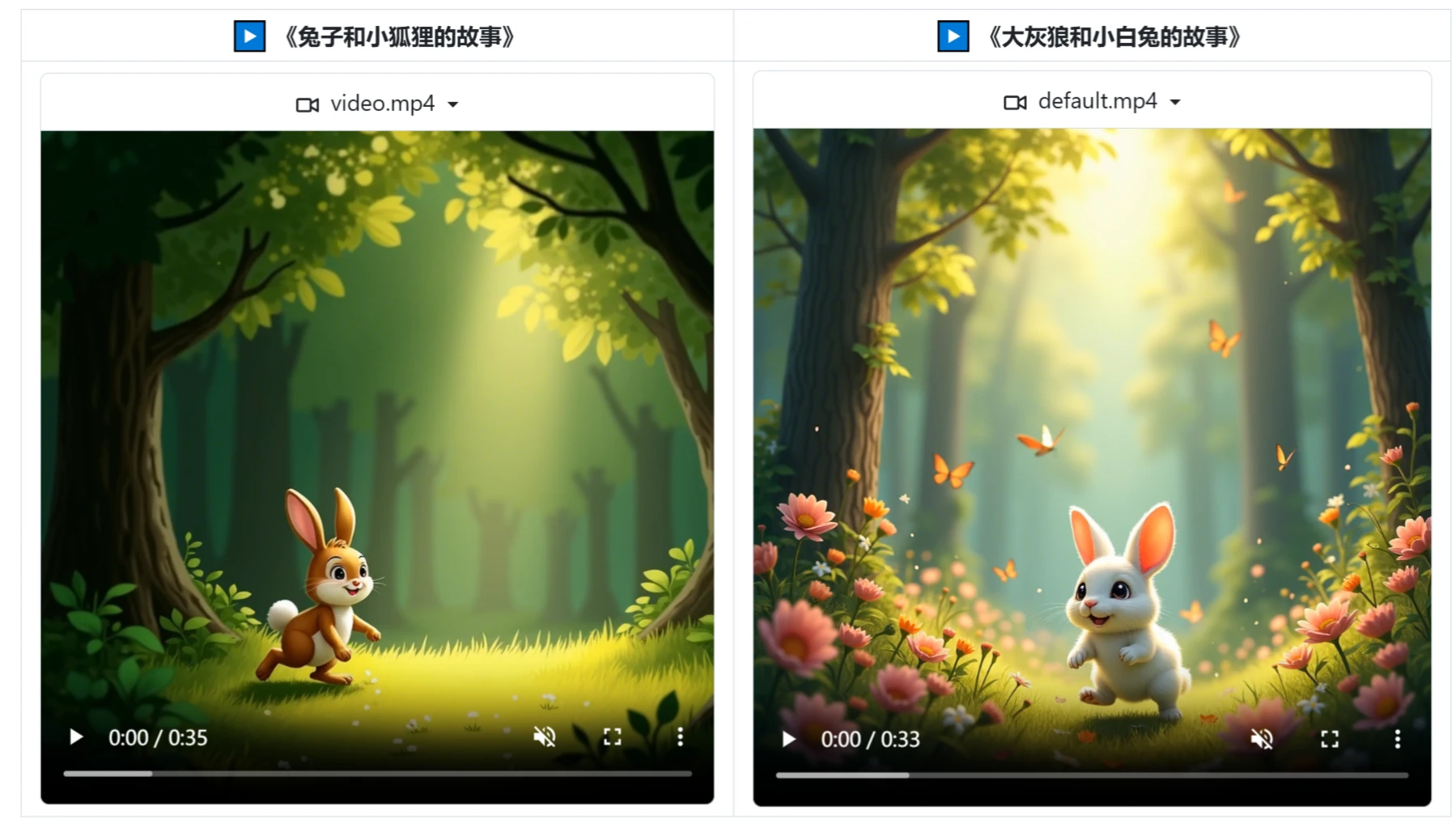
Story Flicks 一款开源的基于AI大模型的故事短视频生成工具。用户输入故事主题,就能够迅速生成包含AI生成图像、故事内容以及音频的视频。 Ai视频生成 2025年06月05日 80 点赞 0 评论 995 浏览
BeautyPlus BeautyPlus是一款结合AI技术的照片编辑软件,支持iOS、Android及网页端操作。它提供AI图像生成、视频编辑、人像优化等功能,可将普通照片转化为创意艺术作品,并包含裁剪、格式转换、滤镜增强等实用工具,适用于社交媒体内容创作、个人肖像美化、艺术创作及商业用途等多个场景。 AI项目与工具 2025年06月12日 64 点赞 0 评论 991 浏览
Sourcetable Sourcetable 是一款基于AI的电子表格与数据分析工具,支持数据清理、公式生成、图表创建、实时同步及自然语言交互。具备超过500种公式支持,可自动生成SQL查询与数据报告,适用于财务、市场、科研等多场景,提升数据处理效率与协作能力。 AI项目与工具 2025年06月12日 46 点赞 0 评论 990 浏览
VideoTutor VideoTutor是一款AI教育辅助工具,能够生成动画讲解视频,帮助学生理解知识点和解题过程。用户可通过文字、截图或语音输入问题,系统自动生成包含语音和动画的视频。支持SAT数学、AP数学、STEM知识和语言学习等领域,提供个性化学习内容,24小时在线使用,适合家长、学生和教师,尤其在SAT数学备考方面表现突出。 AI项目与工具 2025年06月11日 90 点赞 0 评论 978 浏览
OmniSVG OmniSVG是复旦大学与StepFun联合开发的全球首个端到端多模态SVG生成模型,基于预训练视觉语言模型,通过创新的SVG标记化技术实现结构与细节的解耦,支持从文本、图像或角色参考生成高质量矢量图形。其训练效率高,支持长序列处理,适用于图标设计、网页开发、游戏角色生成等场景,生成结果具备高度可编辑性和跨平台兼容性。 AI项目与工具 2025年06月12日 90 点赞 0 评论 977 浏览
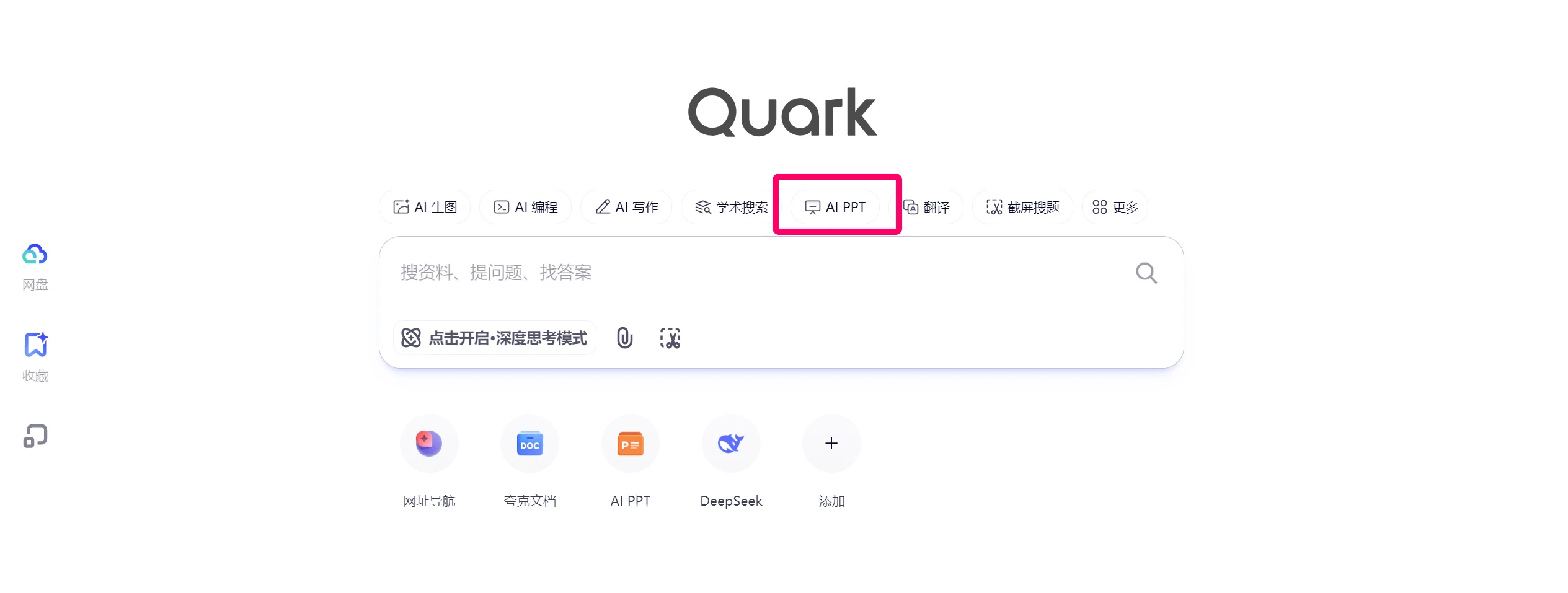
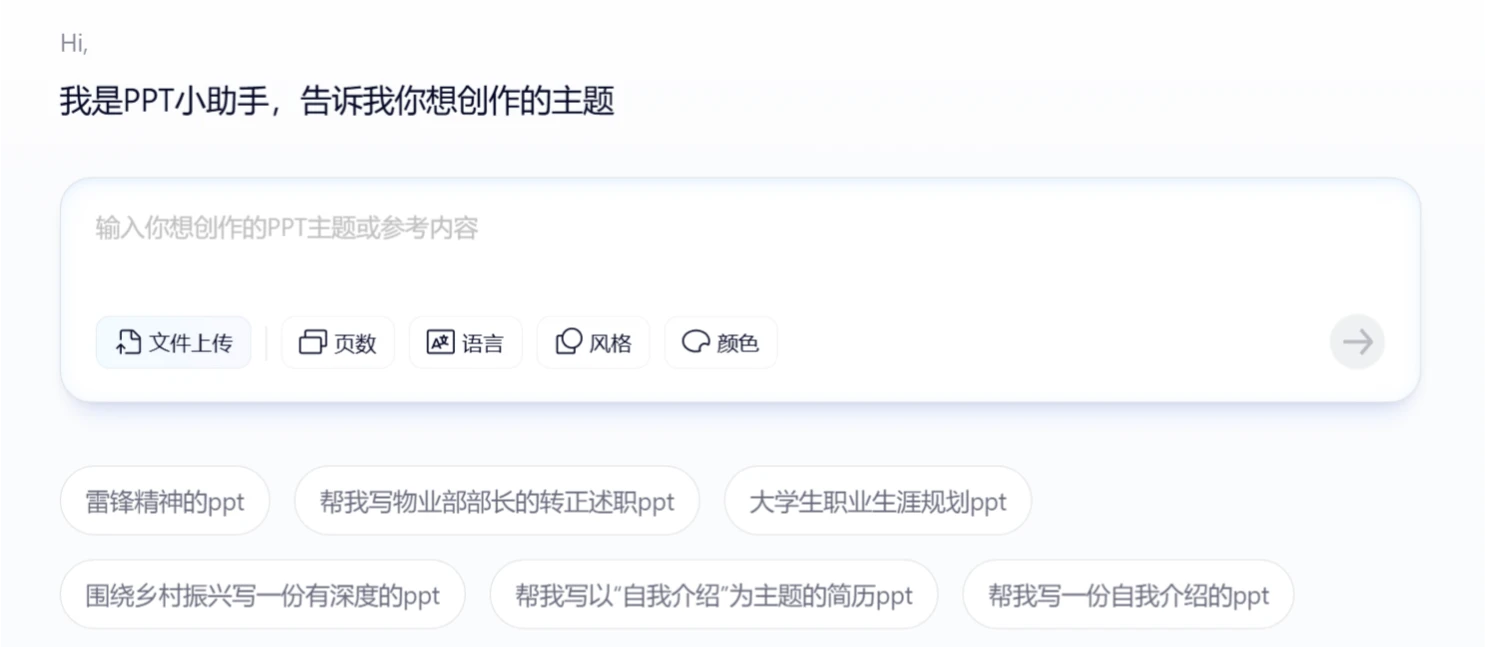
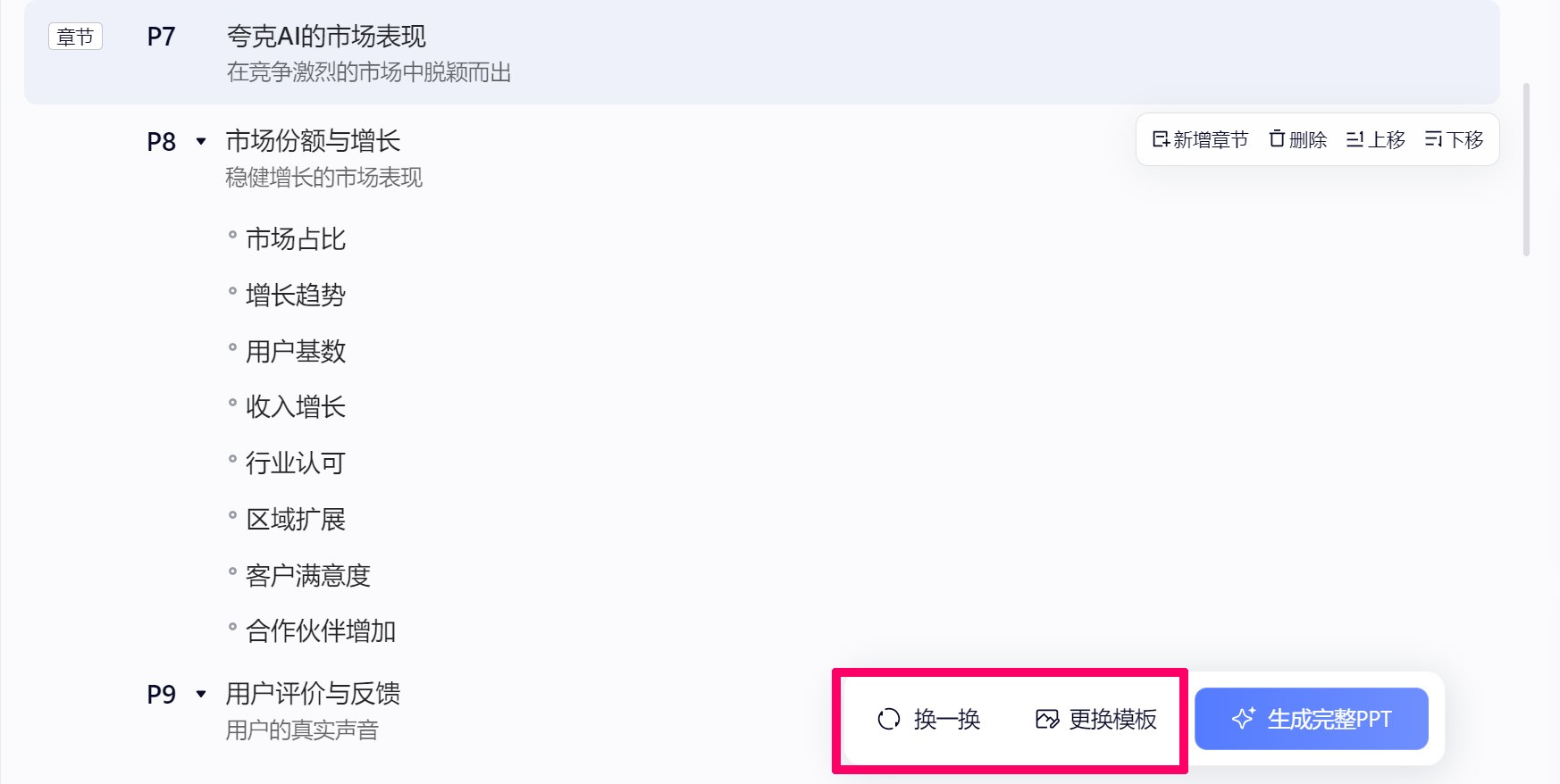
夸克AI PPT 夸克浏览器上的一款PPT生成工具,只需输入主题,夸克PPT即可以一键生成包含大纲、专业模板和精美排版的完整PPT。 PPT资源 2025年06月05日 82 点赞 0 评论 975 浏览
Kodezi Kodezi 是一款面向开发者的 AI 工具平台,基于命令行界面(CLI)提供代码自动调试、优化、语言转换、文档生成及自然语言驱动的代码生成等功能。它支持 30 种编程语言,可生成 OpenAPI 规范并托管 Swagger UI 站点,旨在提升代码质量和开发效率,同时优化团队协作与 API 开发体验。 AI项目与工具 2025年06月12日 17 点赞 0 评论 971 浏览
小半WordPress Ai助手 一个全免费开源WordPress插件,支持AI对话聊天、文章生成、文章总结、文章翻译、生成PPT等功能,此外它还能对接DeepSeek、豆包和通义千问等模型。 Ai编程建站 2025年06月05日 19 点赞 0 评论 969 浏览