CopyCopter CopyCopter是一款基于AI技术的短视频生成工具,能够高效地将长篇文本转化为高质量的短视频内容。它具备自动脚本生成、多语言语音选择、图片生成、库存视频素材调用等功能,并支持视频编辑、社交媒体发布及品牌定制化服务,广泛应用于内容营销、社交媒体管理、教育及新闻媒体等领域,助力用户提升创作效率和作品吸引力。 AI项目与工具 2025年06月12日 29 点赞 0 评论 796 浏览
Podcastfy Podcastfy 是一款基于生成式人工智能技术开发的开源工具,可将网络文章、PDF 文件及纯文本转化为多语言对话式音频。它不仅支持多源文本合并,还具备强大的文本转语音功能,允许用户选择不同的语音模型来优化音频效果。此外,其开源特性便于开发者根据需求进行个性化定制,广泛适用于内容摘要、语言本地化、教育材料转化等多个领域。 AI项目与工具 2025年06月12日 18 点赞 0 评论 796 浏览
Blogcast™ BlogcastTM是一个文本转语音的工具,允许用户创建播客、视频、电子学习课程的音频和音频书籍,而无需录制。它由人工智能驱动的文本转语音技术提供支持,并提供多种声音和语言可供... Ai语音工具 2026年06月26日 0 点赞 0 评论 796 浏览
AVD2 AVD2是由多所高校联合开发的自动驾驶事故视频理解框架,通过生成高质量事故视频并结合自然语言描述与推理,提升对复杂事故场景的理解能力。其功能涵盖事故视频生成、原因分析、预防建议及数据集增强,支持自动驾驶系统的安全优化与研究。基于先进模型如Open-Sora 1.2和ADAPT,AVD2在多项评估中表现优异,为自动驾驶安全提供了重要技术支撑。 AI项目与工具 2025年06月12日 62 点赞 0 评论 796 浏览
Speechify Speechify是一款文本转语音的应用程序,通过将文本转换成自然的声音,帮助你理解和记住更多你所阅读的内容。它可以在Chrome、iOS、Android和Mac上使用。 创作工具 2026年06月26日 0 点赞 0 评论 796 浏览
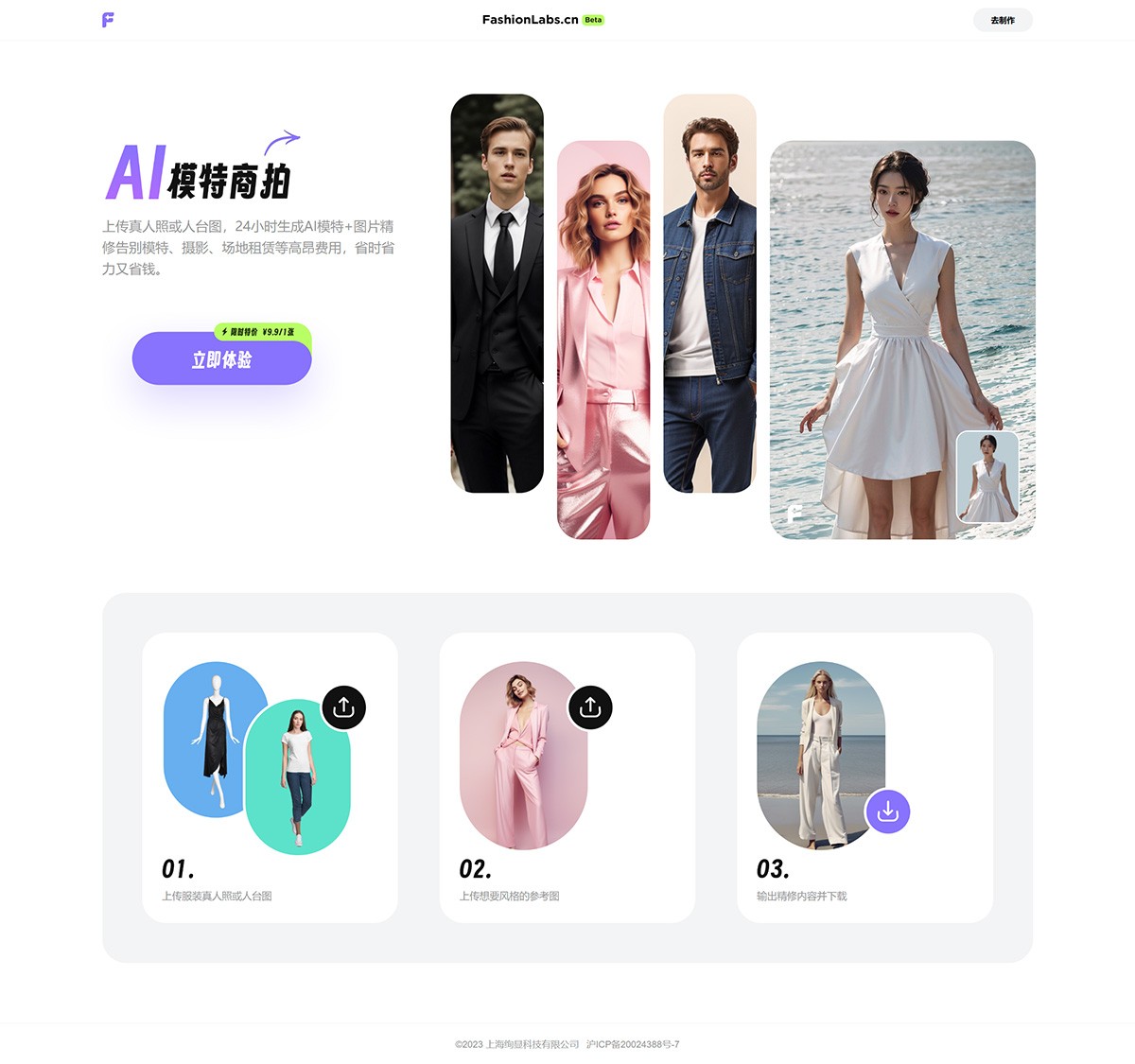
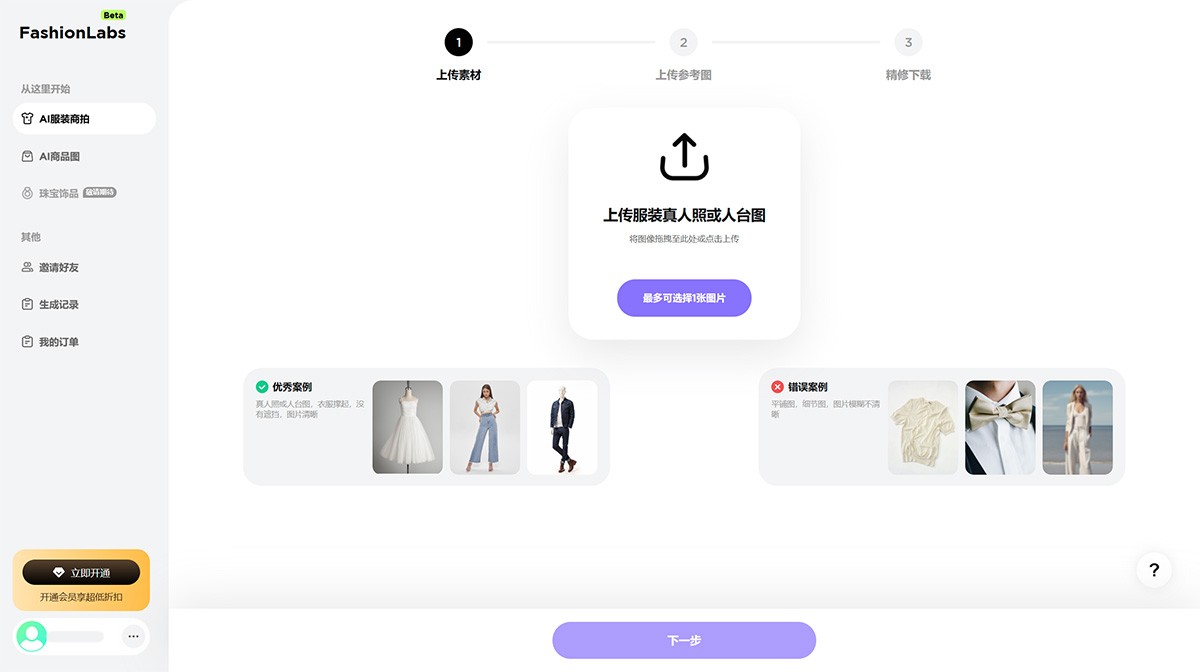
FashionLabs FashionLabs,AI服装模特商拍,为商家和品牌打造独特的AI商品图片,提供高品质的AI服装模特,为用户展现服装的魅力,提升品牌形象和销售。 Ai绘画生成 2025年06月05日 59 点赞 0 评论 796 浏览
Plazmapunk PlazmaPunk 是一个旨在帮助用户轻松创建定制化的音乐生成视频的ai工具。用户通过PlazmaPunk 上传自己的音乐文件,并根据用户选择的风格自动生成定制的视频内容。 Ai视频生成 2025年06月05日 16 点赞 0 评论 795 浏览
Claude 3.7 Sonnet Claude 3.7 Sonnet 是由 Anthropic 推出的混合推理模型,支持标准模式与扩展思考模式,适用于复杂任务处理和日常交互。其在数学、物理、编程等领域表现卓越,尤其在代码生成与理解方面领先。模型优化了安全性,减少误拒率,并支持多平台接入。适用于软件开发、前端设计、科学计算及企业自动化等多个场景。 AI项目与工具 2025年06月12日 37 点赞 0 评论 795 浏览