Jaaz Jaaz是一款开源的AI设计Agent,提供本地免费的AI设计服务。它能智能生成设计提示,批量生成图像、海报和故事板,并支持Ollama、Stable Diffusion等本地图像和语言模型。用户可通过GPT-4o、Flux Kontext等技术在对话中编辑图像,进行对象移除和风格转换。Jaaz提供无限创意画布,适用于创意设计、快速原型、教育及个人创作等多种场景。 AI项目与工具 2025年06月11日 79 点赞 0 评论 755 浏览
ZenCtrl ZenCtrl 是一款基于 AI 技术的图像生成工具,可从单张图像生成多视角、多样化场景,支持实时元素再生。具备高精度控制功能,适用于产品摄影、虚拟试穿、人物肖像控制、插画等场景。提供预处理与后处理能力,提升图像质量,架构模块化,适应多种创意需求。 AI项目与工具 2025年06月11日 43 点赞 0 评论 701 浏览
Uthana Uthana是一款基于AI的3D角色动画生成平台,支持通过文字描述、参考视频或动作库快速生成逼真动画。其核心功能包括动作搜索、骨骼适配、风格迁移、API集成等,适用于游戏开发、影视制作、虚拟角色设计等多个领域。平台提供灵活的输出格式和编辑工具,帮助用户高效完成动画创作。 AI项目与工具 2025年06月12日 62 点赞 0 评论 512 浏览
天谱乐 天谱乐是一款由趣丸科技推出的支持多模态输入的音乐生成工具,涵盖文本、图片及视频生成音乐功能。它能够准确理解音乐复杂特性并生成高契合度配乐,同时提供专家模式和音乐编辑功能,适用于音乐创作、短视频配乐、影视配乐及个人娱乐等多个领域。 AI项目与工具 2025年06月12日 95 点赞 0 评论 864 浏览
塔猫AI对话PPT 塔猫AI对话PPT是一款利用深度学习与自然语言处理技术的智能PPT分析工具,可解析文本、图表等内容,支持智能问答、摘要生成及逻辑优化建议等功能。它适用于信息检索、演讲准备、教育培训等多个场景,助力用户高效获取所需信息。 AI项目与工具 2025年06月12日 98 点赞 0 评论 539 浏览
Aiswers 一个一站式AI问答平台,汇聚了ChatGPT, Claude, Gemini等几十款全球顶尖的AI,为用户提供各种问题的解答。涵盖了各种主题,包括学习、技术、文化、生活等,用户不但可以得到文字回答,还能生成各种图片。 AI写作对话 2025年06月05日 32 点赞 0 评论 719 浏览
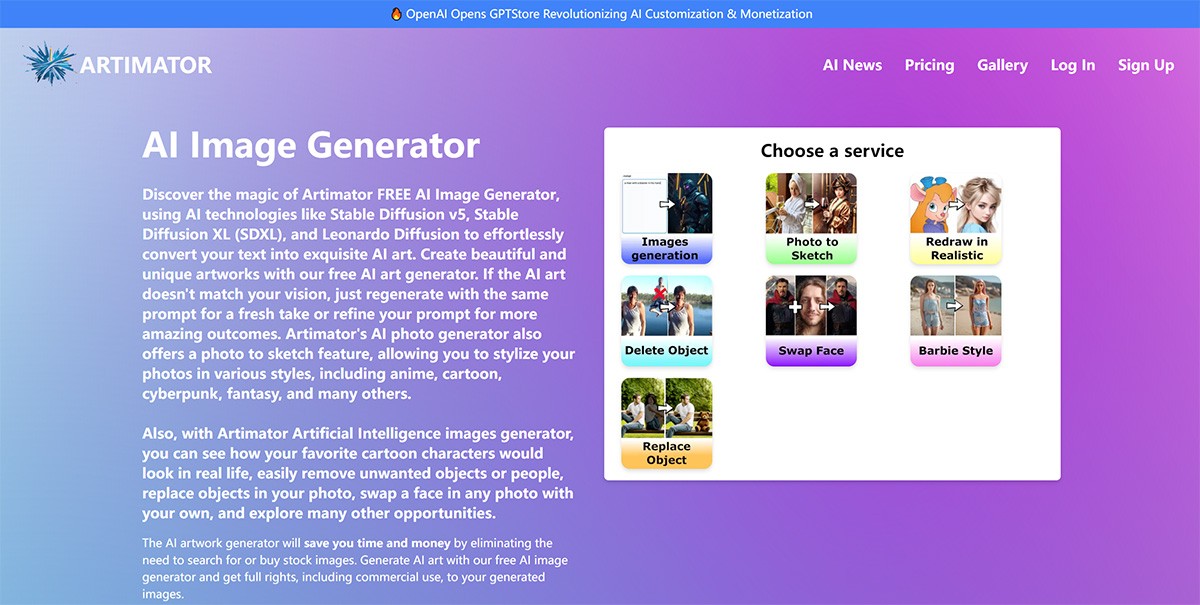
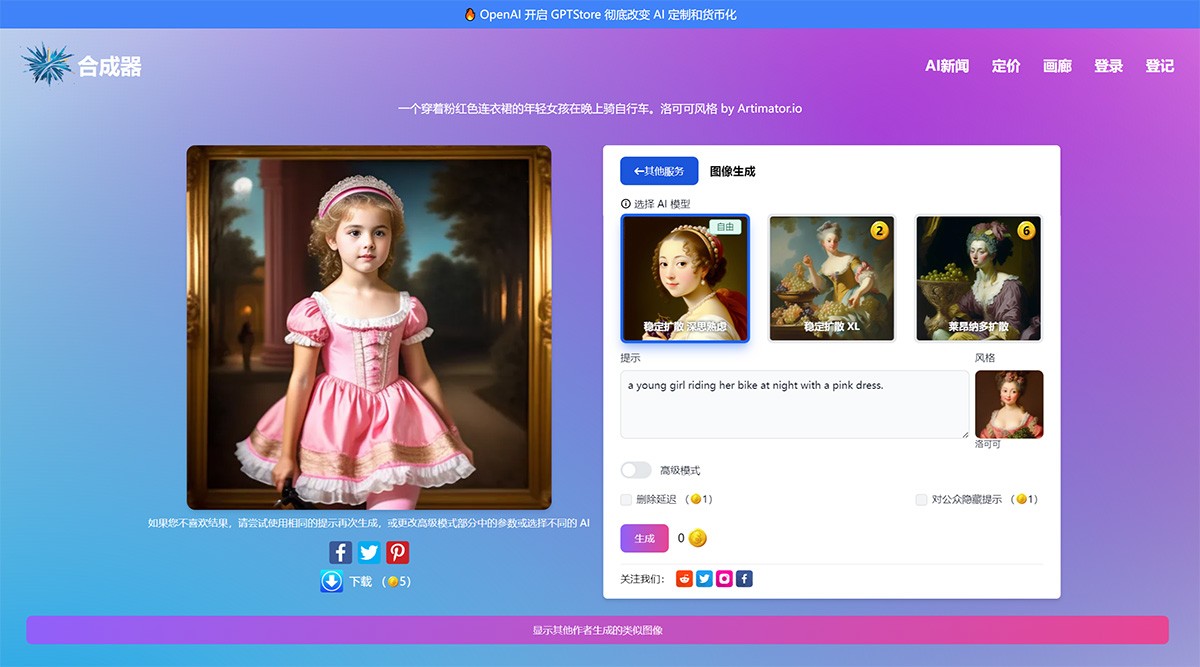
Artimator.Io 一个免费的 AI 驱动的艺术生成器,可让您从文本描述或照片中创建独特的艺术品。它利用 Stable Diffusion 和 SDXL 人工智能,提供了一个多功能平台,用于生成各种风格的艺术作品。 Ai绘画生成 2025年06月05日 61 点赞 0 评论 739 浏览