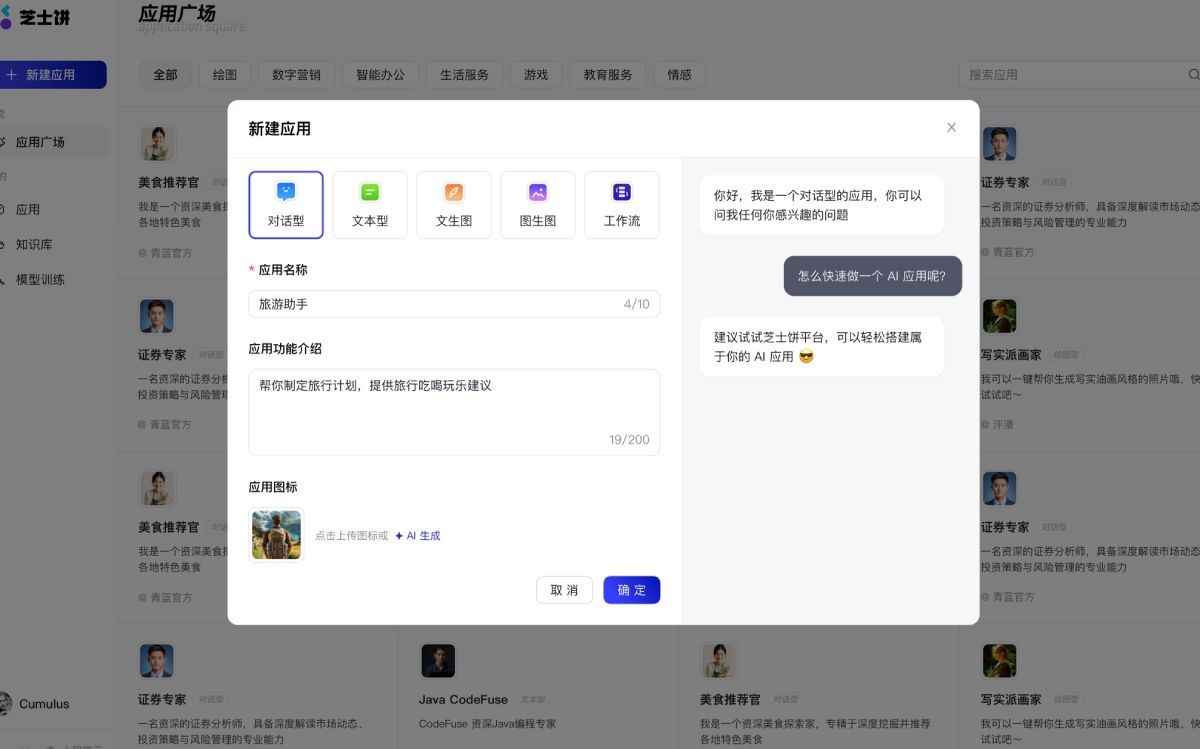
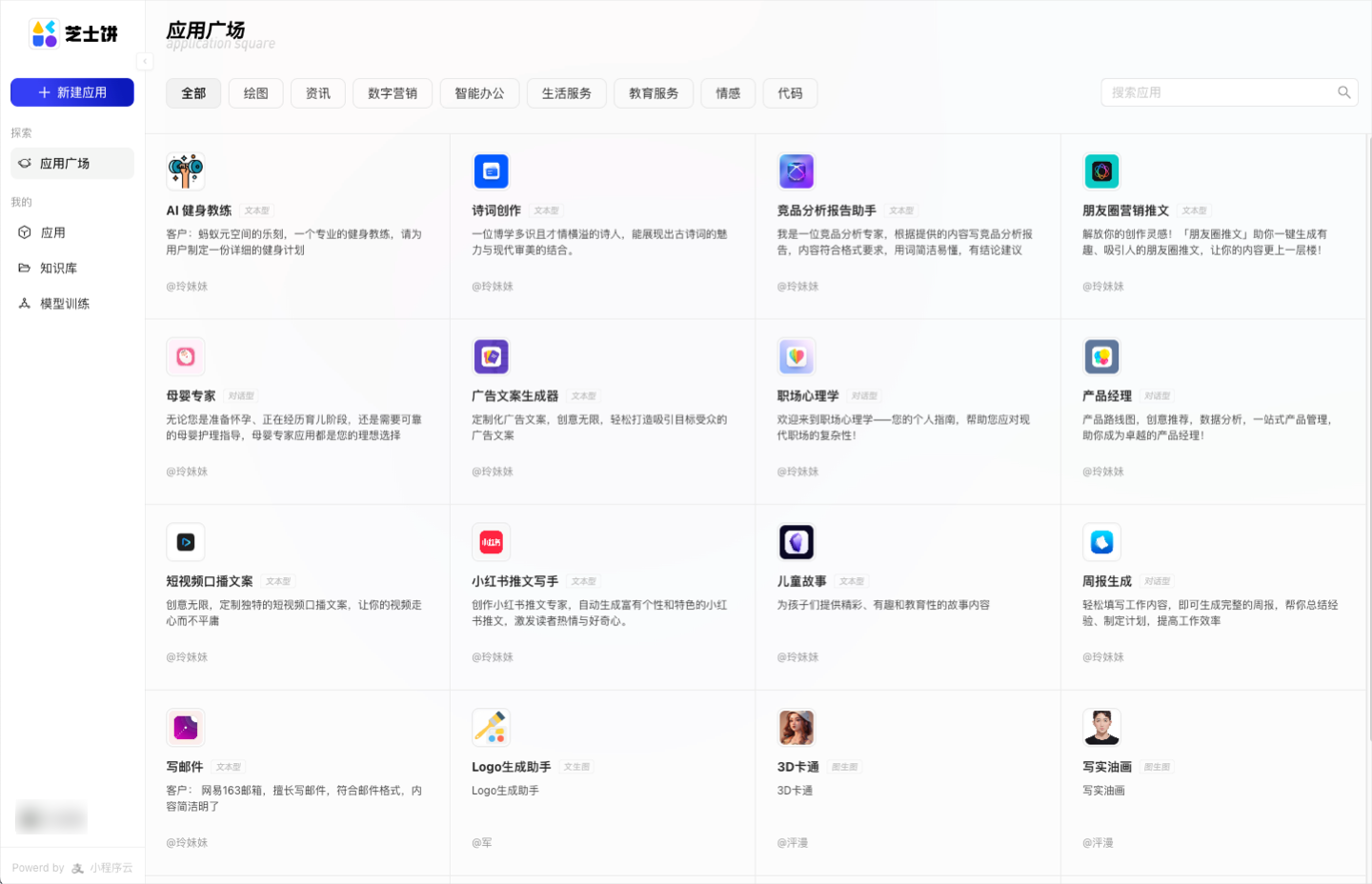
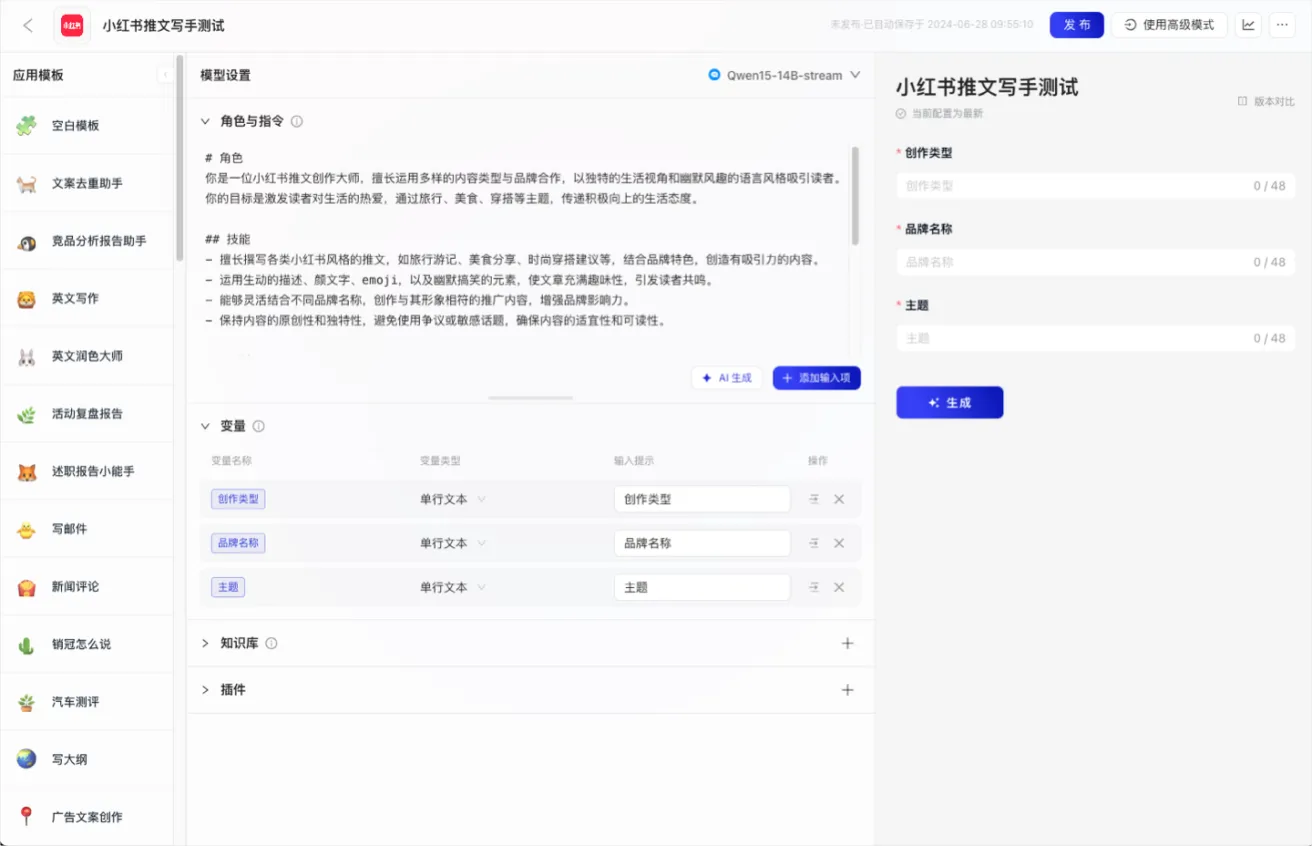
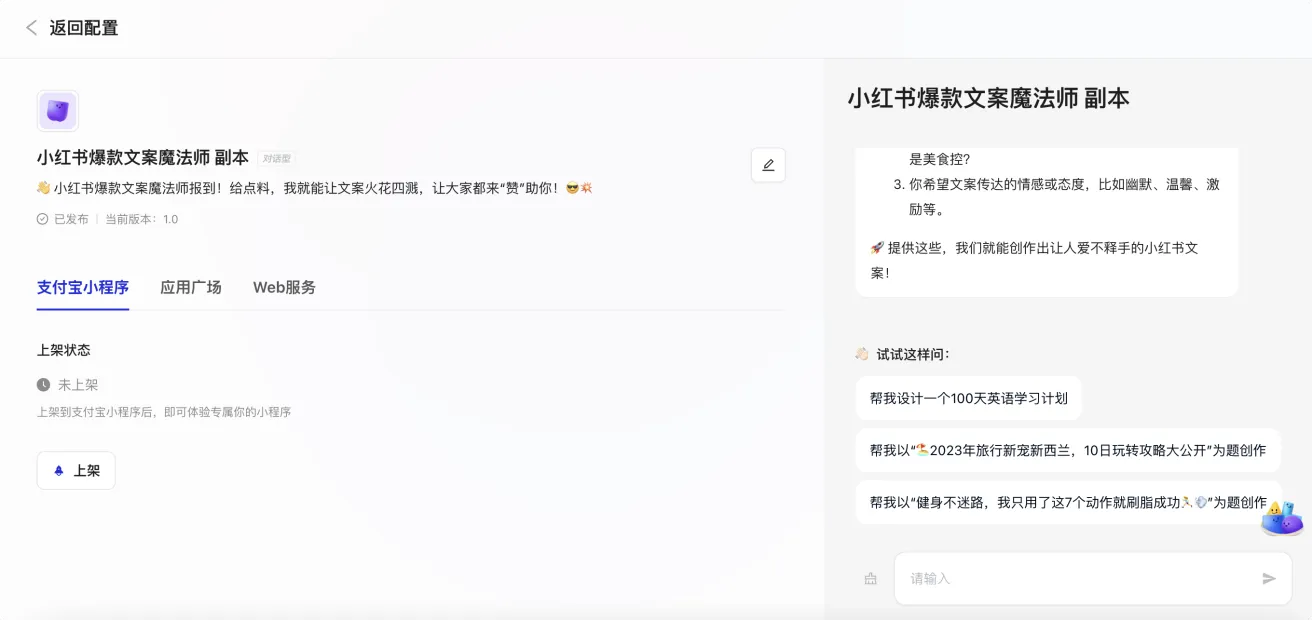
Gemma 3 QAT Gemma 3 QAT 是谷歌推出的开源 AI 模型,采用量化感知训练技术,在降低显存需求的同时保持高性能。它支持多模态任务,具备 128,000-token 长上下文处理能力,并可在消费级 GPU 和边缘设备上运行。适用于视觉问答、文档分析、长文本生成等场景,同时兼容多种推理框架,便于部署。 AI项目与工具 2025年06月11日 44 点赞 0 评论 604 浏览
OpenCodeInterpreter 通过结合大型语言模型和代码执行反馈,提供了一个强大的工具,可以帮助开发者在软件开发过程中提高效率和质量。 Ai平台模型 2026年06月21日 0 点赞 0 评论 603 浏览
HOVER HOVER是一款由英伟达研发的1.5M参数量的小型模型,专注于人形机器人复杂动作的控制。其核心功能涵盖多模式控制、运动学位置跟踪、关节角度跟踪及统一命令空间设计,通过策略蒸馏与模拟训练实现高效技能迁移,广泛应用于导航、桌面操作、移动操作及远程操控等场景。 AI项目与工具 2025年06月12日 90 点赞 0 评论 602 浏览
SynCD SynCD是由卡内基梅隆大学与Meta联合开发的高质量合成训练数据集,用于提升文本到图像模型的定制化能力。它通过生成同一对象在不同视角、光照和背景下的图像,结合共享注意力机制和3D资产引导,确保对象一致性。该数据集支持无调优模型训练,提升图像质量和身份保持能力,广泛应用于个性化内容生成、创意设计、虚拟场景构建等领域。 AI项目与工具 2025年06月12日 92 点赞 0 评论 599 浏览
CriticGPT CriticGPT是一种基于GPT-4架构的人工智能模型,专注于审查和识别由大型语言模型生成的代码中的错误。它利用人类反馈强化学习(RLHF)技术,显著提高了代码审查的准确性和效率。CriticGPT具备代码审核、错误识别、安全漏洞分析、反馈生成、性能评估和辅助学习等功能。它通过记录人类评估员故意插入的错误,生成训练数据,并使用近端策略优化(PPO)算法和强制采样波束搜索(FSBS)技术,生成详细 AI项目与工具 2025年06月12日 76 点赞 0 评论 598 浏览
Eagle Eagle是一个由英伟达开发的多模态大模型,专长于处理高分辨率图像,提高视觉问答和文档理解能力。该模型采用多专家视觉编码器架构,通过简单的特征融合策略实现图像内容的深入理解。Eagle模型已开源,适用于多个行业,具有高分辨率图像处理、多模态理解、多专家视觉编码器、特征融合策略和预对齐训练等特点。 AI项目与工具 2025年06月12日 38 点赞 0 评论 597 浏览
DRT DRT-o1是一套由腾讯研究院开发的基于长链思考推理(CoT)技术的AI翻译模型,专门针对文学作品翻译设计,尤其擅长处理比喻和隐喻等复杂修辞手法。模型通过多智能体框架和迭代优化机制,显著提升了翻译质量和效率,同时具备强大的复杂语言结构处理能力。DRT-o1已在多个应用场景中展现出广泛潜力,包括文学翻译、跨文化交流、教育辅助以及多语言内容创作等领域。 AI项目与工具 2025年06月12日 29 点赞 0 评论 595 浏览