Realtime API Realtime API是一款由OpenAI研发的低延迟、多模态对话式API,支持文本与音频输入输出,具备实时语音处理、自然语音合成及多模态交互等功能。通过WebSocket协议实现持久连接,支持事件驱动的交互模式,适用于客户服务、语言学习、游戏娱乐等多种应用场景。 AI项目与工具 2025年06月12日 41 点赞 0 评论 756 浏览
MoneyPrinterPlus MoneyPrinterPlus是一款基于AI技术的短视频生成工具,能够实现一键批量生成并自动混剪短视频。该工具支持将视频自动发布至多个社交平台,简化了视频内容创作流程。MoneyPrinterPlus的核心功能包括AI一键批量生成短视频、自动批量混剪、自动发布到社交平台、支持本地和云语音服务以及AI生图功能。 AI项目与工具 2025年06月12日 61 点赞 0 评论 755 浏览
Orpheus TTS Orpheus TTS 是一款基于 Llama-3b 架构的开源文本到语音系统,支持自然、富有情感的语音生成。具备零样本语音克隆能力,无需预训练即可模仿特定语音,延迟低至 200 毫秒,适合实时应用。支持多种语音风格和情感控制,适用于有声读物、虚拟助手、游戏、教育等多个领域。 AI项目与工具 2025年06月12日 26 点赞 0 评论 752 浏览
EmotiVoice EmotiVoice是网易有道推出的开源文本到语音系统,支持中英文及2000+音色,能根据提示生成带情感的语音。具备情感合成、语音克隆、多语言支持等功能,提供Web界面和API接口,适用于有声读物、智能助手、教育、客服等场景,技术上支持高效部署与模型微调。 AI项目与工具 2025年06月12日 30 点赞 0 评论 745 浏览
ViiTor AI ViiTor AI是一款基于人工智能技术的创新平台,集成了视频翻译、语音克隆、动态语音合成等功能,支持多语言处理。它能够将静态内容转化为动态形式,同时实现跨语言交流,适用于个人创作者、教育机构、跨国企业和翻译行业,帮助企业提升全球化竞争力。 AI项目与工具 2025年06月12日 86 点赞 0 评论 739 浏览
EasyVideoTrans EasyVideoTrans是一款开源的AI视频翻译工具,支持从视频中提取音频并翻译字幕,同时提供多样化的声音风格以实现自然的配音效果。它适用于视频创作者、教育机构、企业培训及品牌宣传等领域,能够快速生成高质量的中文版本视频,满足跨语言沟通的需求。 AI项目与工具 2025年06月12日 39 点赞 0 评论 739 浏览
Vidnoz Vidnoz是一款基于AI的在线视频生成工具,拥有超过1200个逼真的虚拟形象、470多种语言支持及900多个视频模板,支持从文本到视频的全流程制作。其主要功能包括AI虚拟形象生成、文字转语音、视频模板应用、智能编辑、语音克隆以及静态图片动态化处理,广泛应用于社交媒体营销、在线教育、企业培训、产品宣传等领域。 AI项目与工具 2025年06月12日 57 点赞 0 评论 739 浏览
绘声美音 绘声美音是一款集声音克隆、AI变声、文字转语音及多种音频处理功能于一体的在线工具,用户可通过微信公众号便捷使用。支持上传语音训练专属声纹模型,进行歌曲翻唱并生成MV,同时提供变声、音频提取、听歌识曲等功能,适用于娱乐、配音、创作等多种场景。 AI项目与工具 2025年06月12日 39 点赞 0 评论 721 浏览
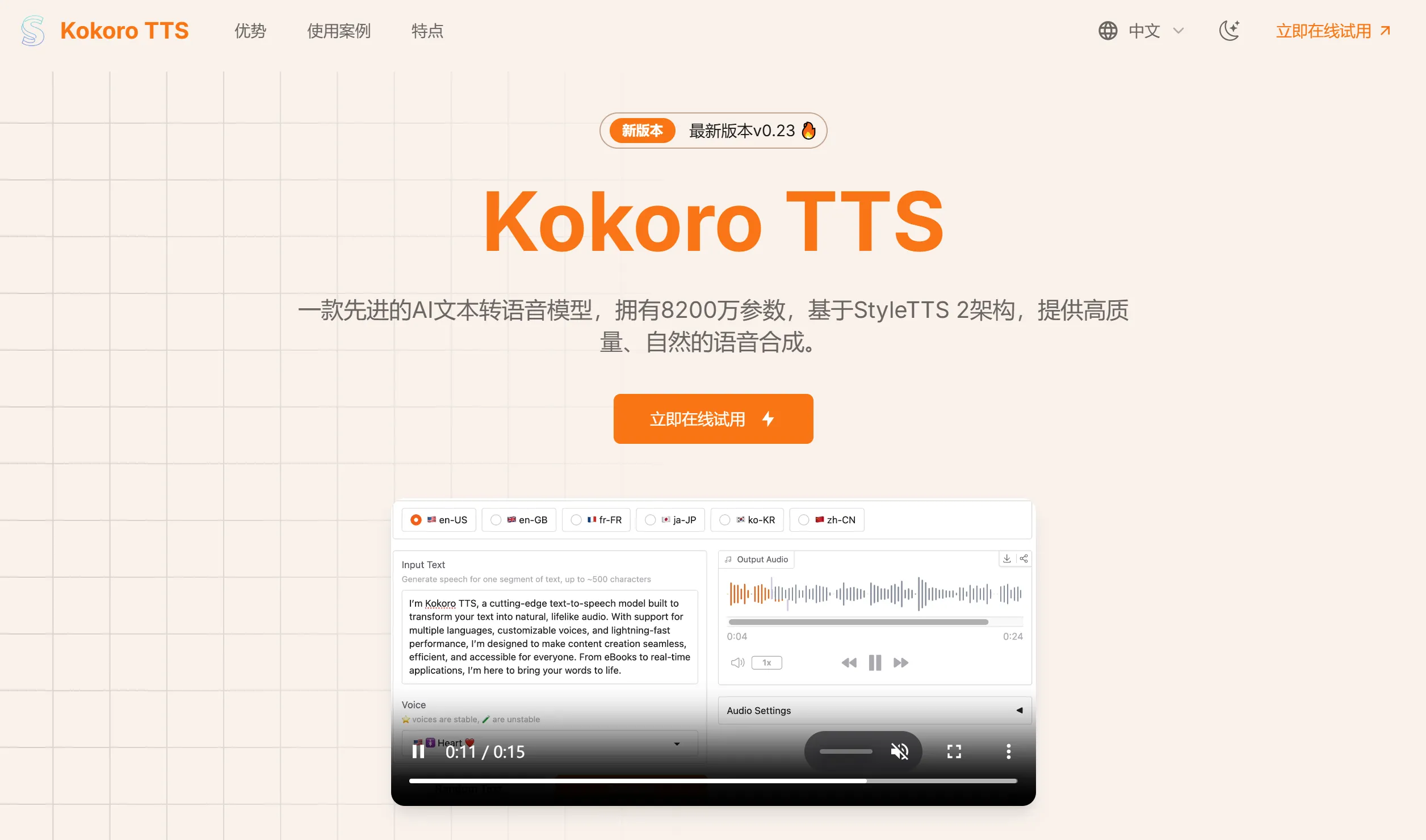
kokoroTTS 一款开源、高性能的文本转语音(TTS)模型,Kokoro TTS拥有8200万参数,基于StyleTTS 2架构,提供高质量、自然的语音合成,适用于有声书、播客等。 Ai语音工具 2025年06月05日 80 点赞 0 评论 718 浏览