语音
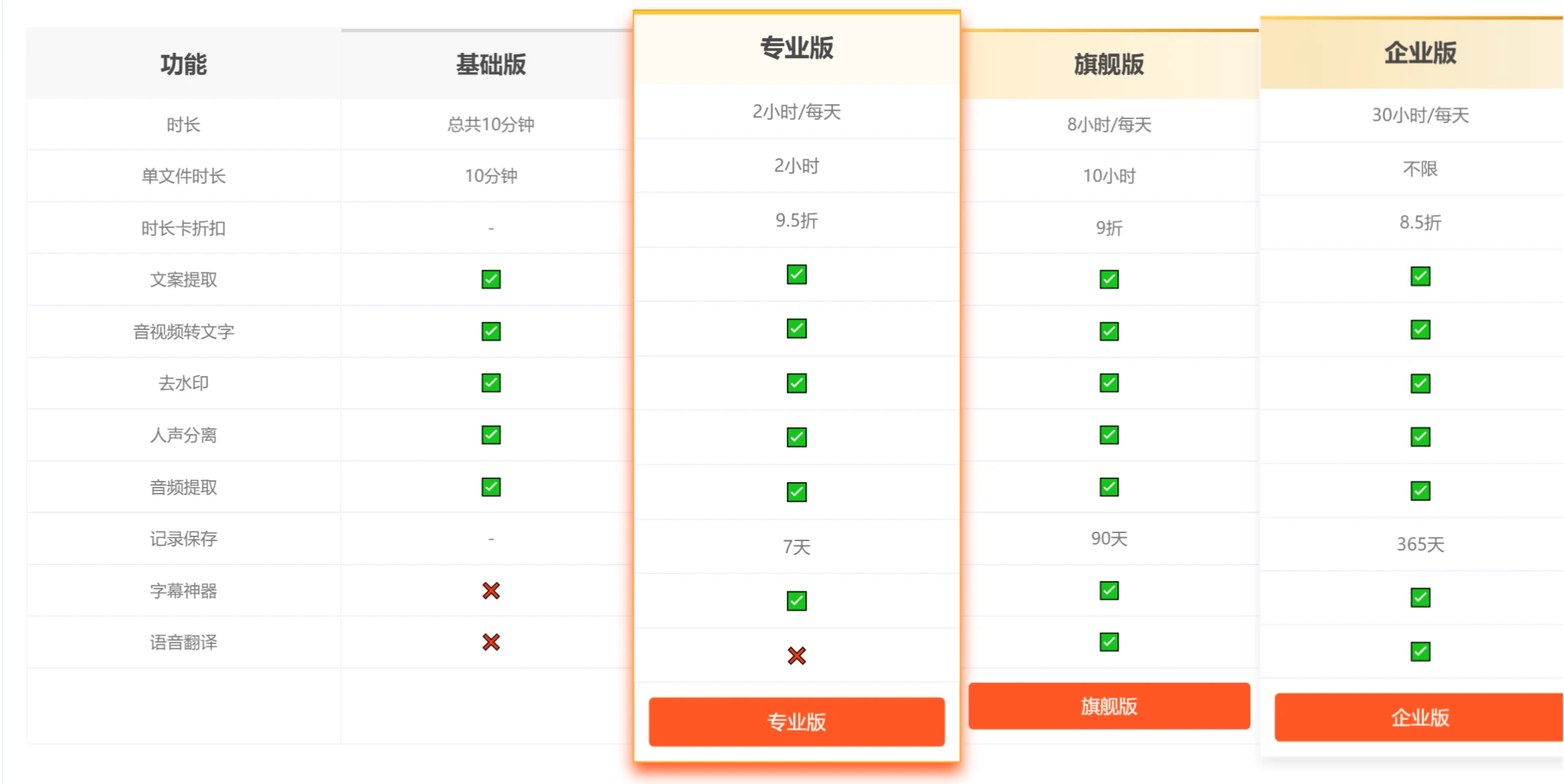







Soundverse AI
一个利用生成式人工智能的音乐创作平台,Soundverse AI提供免费的 AI 音乐生成器和语音助手,帮助音乐创作者轻松制作高质量的音乐。

Lemon Slice Live
Lemon Slice Live 是一款基于扩散变换器模型(DiT)的实时视频聊天工具,可将图片转化为可互动的动画角色,支持多语言和实时对话。通过优化模型提升流畅度与响应速度,适用于娱乐、教育、营销等多种场景,结合语音识别、文本生成等技术,提供完整的交互体验。

SpeechEasy
SpeechEasy是一种合成语音解决方案,可以让用户从文本生成高质量、易于理解的音频。它适用于各种设备和平台,支持桌面和移动设备,有近12种高质量的合成声音可供选择。它使用简单...
