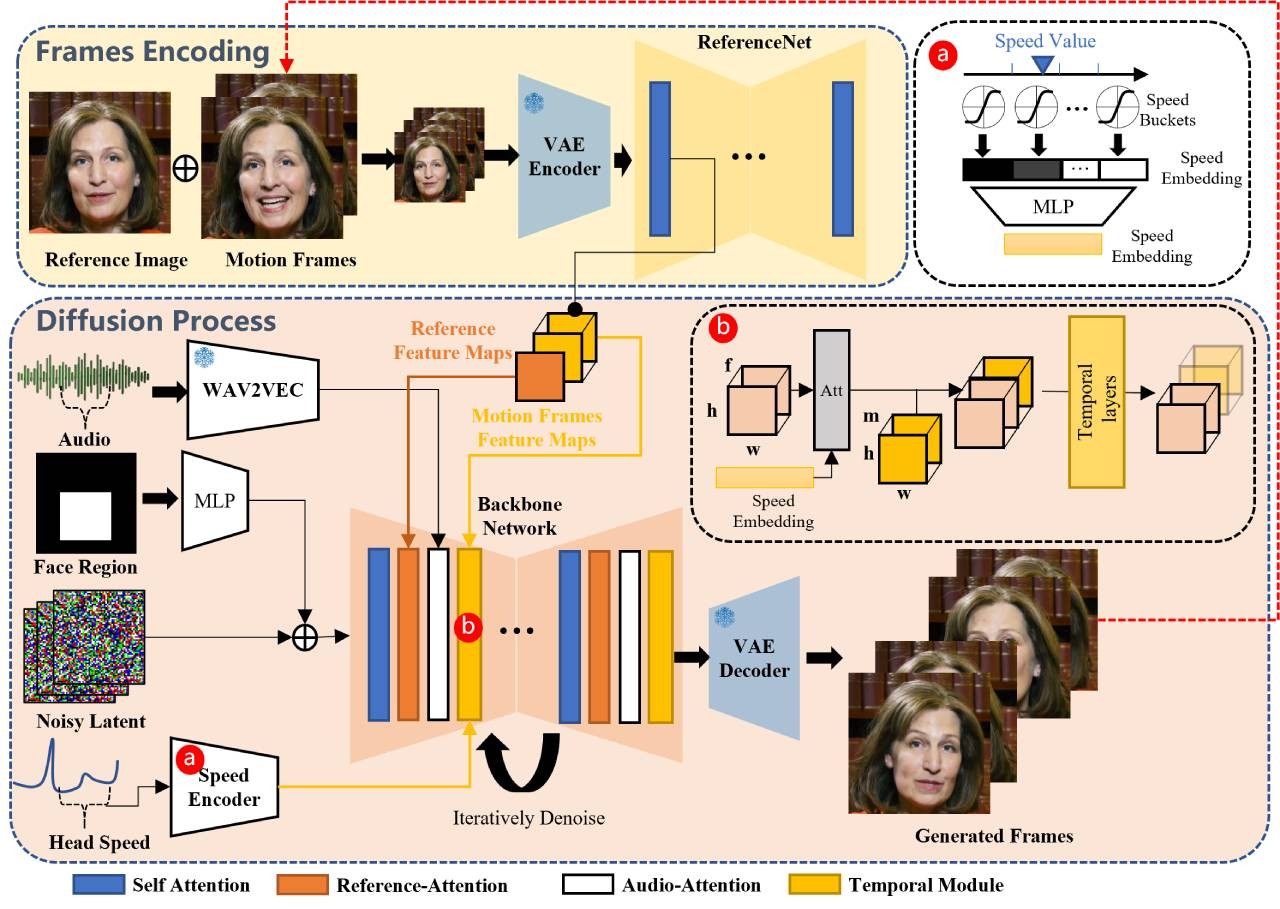
OmniHuman OmniHuman是字节跳动推出的多模态人类视频生成框架,基于单张图像和运动信号生成高逼真视频。支持音频、姿势及组合驱动,适用于多种图像比例和风格。采用混合训练策略和扩散变换器架构,提升生成效果与稳定性,广泛应用于影视、游戏、教育、广告等领域。 AI项目与工具 2025年06月12日 43 点赞 0 评论 635 浏览
MagicMic MagicMic是一个功能强大的声音变换工具,适用于游戏玩家、主播和内容创作者。它通过提供丰富的声音过滤器和音效,以及实时声音变换技术,使用户能够在游戏中或在线聊天中保护隐私... 创作工具 2026年06月21日 0 点赞 0 评论 636 浏览
Emote Portrait Alive 阿里巴巴发布的EMO,一种音频驱动的AI肖像视频生成框架。通过输入单一的参考图像和语音音频,Emote Portrait Alive可以生成动态的、表情丰富的肖像视频。 Ai开源项目 2025年06月05日 18 点赞 0 评论 637 浏览
Covers AI 一款功能强大的AI声音和歌曲生成器工具,允许用户使用来自著名主播、政治家、歌手、卡通人物等的数千种声音生成 AI 翻唱。 Ai语音工具 2025年06月05日 82 点赞 0 评论 638 浏览
MyEdit 一款在线图片编辑和音频剪辑工具,用户可以使用AI照片编辑器来增强照片、去除人物和文字,甚至生成图像和场景。还提供强大的音频编辑工具,包括文本转语音、语音转文本和背景噪音去除功能。 图片处理 2025年06月05日 54 点赞 0 评论 641 浏览
音虫 音虫SoundBug是一款由国内团队研发的数字音频工作站(DAW)软件,以其简洁直观的用户界面和易于上手的操作特点,为音乐爱好者和音乐学习者提供了一套完整的音乐制作工具。 创作工具 2026年06月21日 0 点赞 0 评论 641 浏览
TANGO TANGO是一个开源框架,利用分层音频运动嵌入和扩散插值网络,生成与目标语音同步的全身手势视频。其主要功能包括高保真视频制作、跨模态对齐、过渡帧生成及外观一致性保持,适用于新闻播报、虚拟YouTuber、在线教育等多个领域。该工具通过先进的技术解决了动作与语音匹配问题,并有效提升了视频内容制作效率。 AI项目与工具 2025年06月12日 78 点赞 0 评论 644 浏览
Seed Music 一个强大的音乐生成工具,它通过先进的技术手段,如自回归模型和扩散模型,为用户提供了从音乐创作到编辑再到声音转换的全方位服务。这套系统不仅能够生成高质量的音乐作品,还能... 创作工具 2026年06月21日 0 点赞 0 评论 646 浏览