音频









EmotiVoice
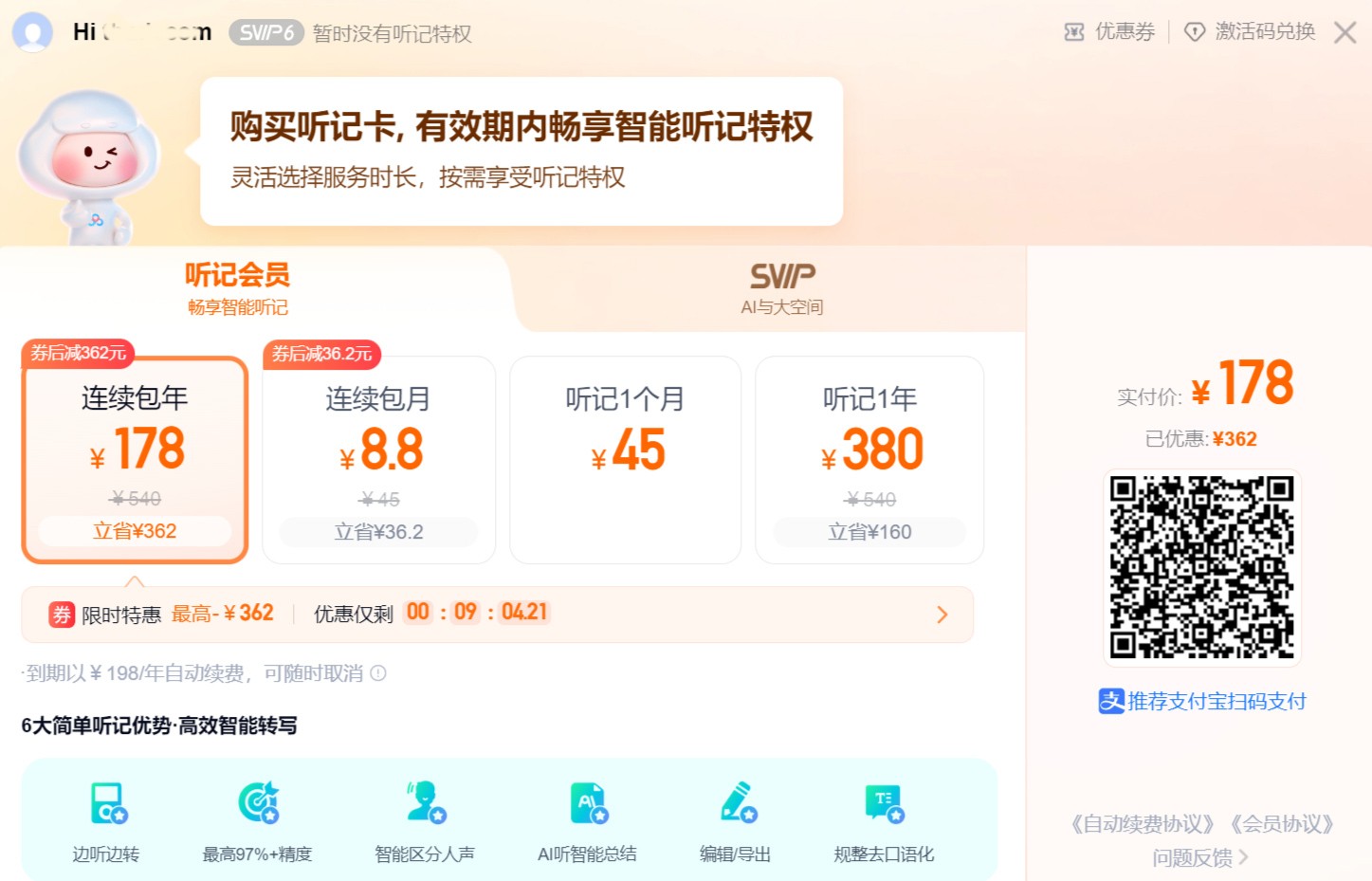
EmotiVoice是网易有道推出的开源文本到语音系统,支持中英文及2000+音色,能根据提示生成带情感的语音。具备情感合成、语音克隆、多语言支持等功能,提供Web界面和API接口,适用于有声读物、智能助手、教育、客服等场景,技术上支持高效部署与模型微调。
