RealtimeSTT RealtimeSTT是一款开源的实时语音转文本库,具备高精度语音活动检测、GPU加速的实时转录能力以及语音唤醒功能。支持多语言识别,适用于语音助手、会议记录、实时字幕等场景,提供灵活的音频输入与预处理机制,便于开发者快速集成和扩展。 AI项目与工具 2025年06月12日 97 点赞 0 评论 853 浏览
Podcastle Podcastle是一款以AI为核心的播客制作平台,集成了录音室、音频与视频编辑器及AI生成的声音工具,支持本地多人协作录音、降噪处理、品牌定制化功能及声音克隆技术。该平台覆盖从创意到发布的全链条服务,并支持内容托管与多平台分发,适用于个人播客、远程采访、教育培训、企业沟通及有声读物制作等多种场景。 AI项目与工具 2025年06月12日 31 点赞 0 评论 849 浏览
Fineshare VoiceTrans Fineshare VoiceTrans 是一款支持实时变声的 AI 工具,可将声音转换为多种角色或性别,保留原有情感与语调。提供丰富的音效库、声音实验室和预设声音包,适用于游戏、直播、配音等场景。用户可通过不同订阅计划获得无限使用权限和定制服务,提升创作与互动体验。 AI项目与工具 2025年06月12日 24 点赞 0 评论 848 浏览
音控 音控是一款基于AI技术的音乐创作平台,提供AI作词、作曲、伴奏生成、AI歌手模拟等多功能支持,适用于个人创作、专业制作、音乐教育及治疗等领域。其智能化工具能够显著降低音乐创作门槛,同时满足多样化的音乐风格需求,使创作过程更高效且趣味盎然。 --- AI项目与工具 2025年06月12日 44 点赞 0 评论 846 浏览
Aconvert 一款免费的在线格式转换工具,支持多达 110 多种文件格式转换,包括 PDF、文档、电子书、图片、音频、视频和压缩文件等。 格式转换 2025年06月05日 28 点赞 0 评论 844 浏览
妙刷 妙刷是一款由美团推出的AI创作工具,支持修图、文本生图、音频生图及视频生成等功能,可将日常素材转化为艺术作品,如拟人化宠物、魔幻风景等,同时定期更新玩法和特效以保持新鲜感。 AI项目与工具 2025年06月12日 99 点赞 0 评论 844 浏览
Whisper Input Whisper Input 是一款开源语音输入工具,基于 Python 和 OpenAI Whisper 模型开发,支持多语言语音识别与实时转录。用户可通过快捷键操作录音并生成文本,具备翻译、自动标点、高效处理及本地运行等功能。适用于会议记录、教育、智能交互及媒体制作等多种场景。 AI项目与工具 2025年06月12日 29 点赞 0 评论 843 浏览
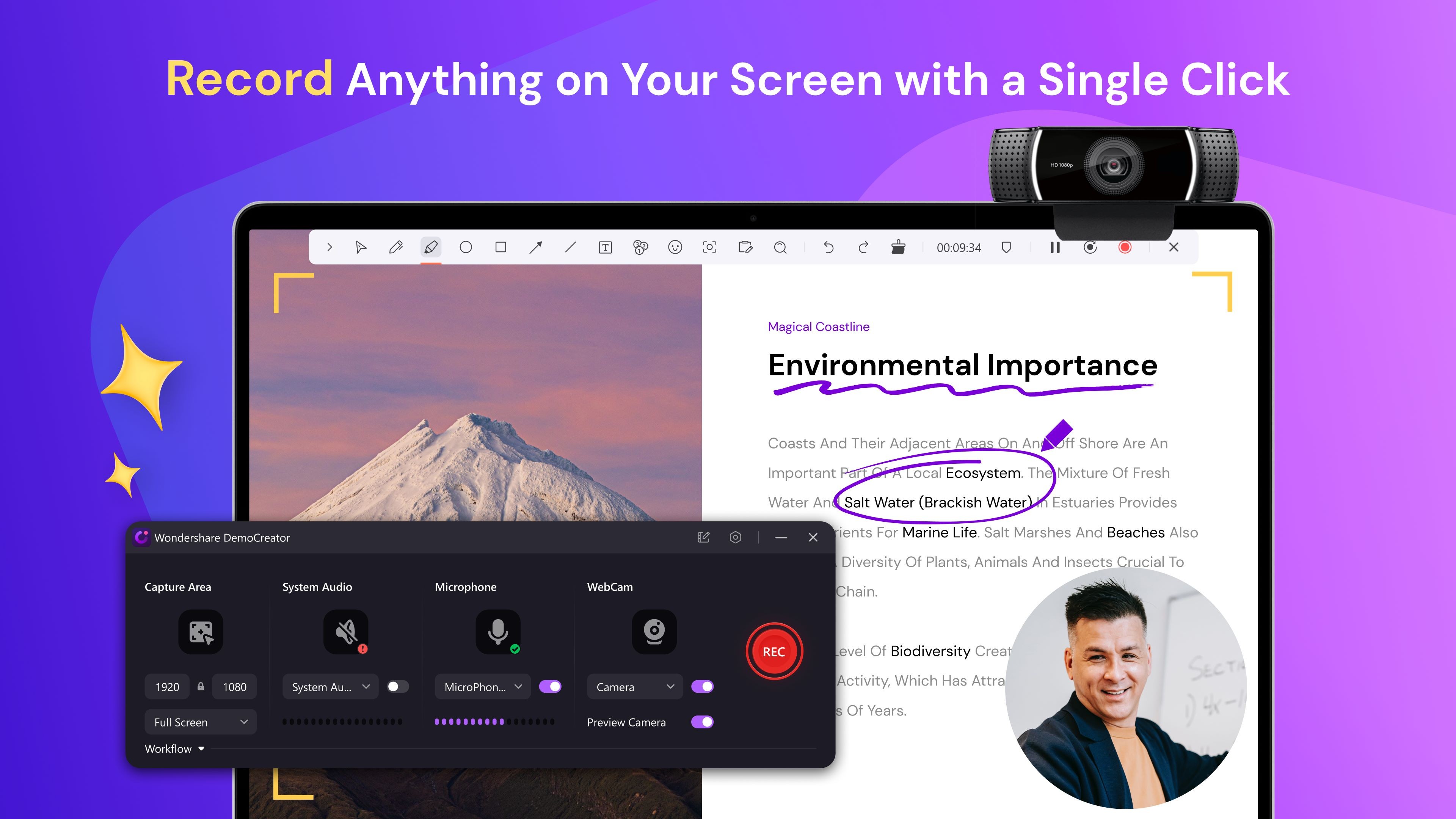
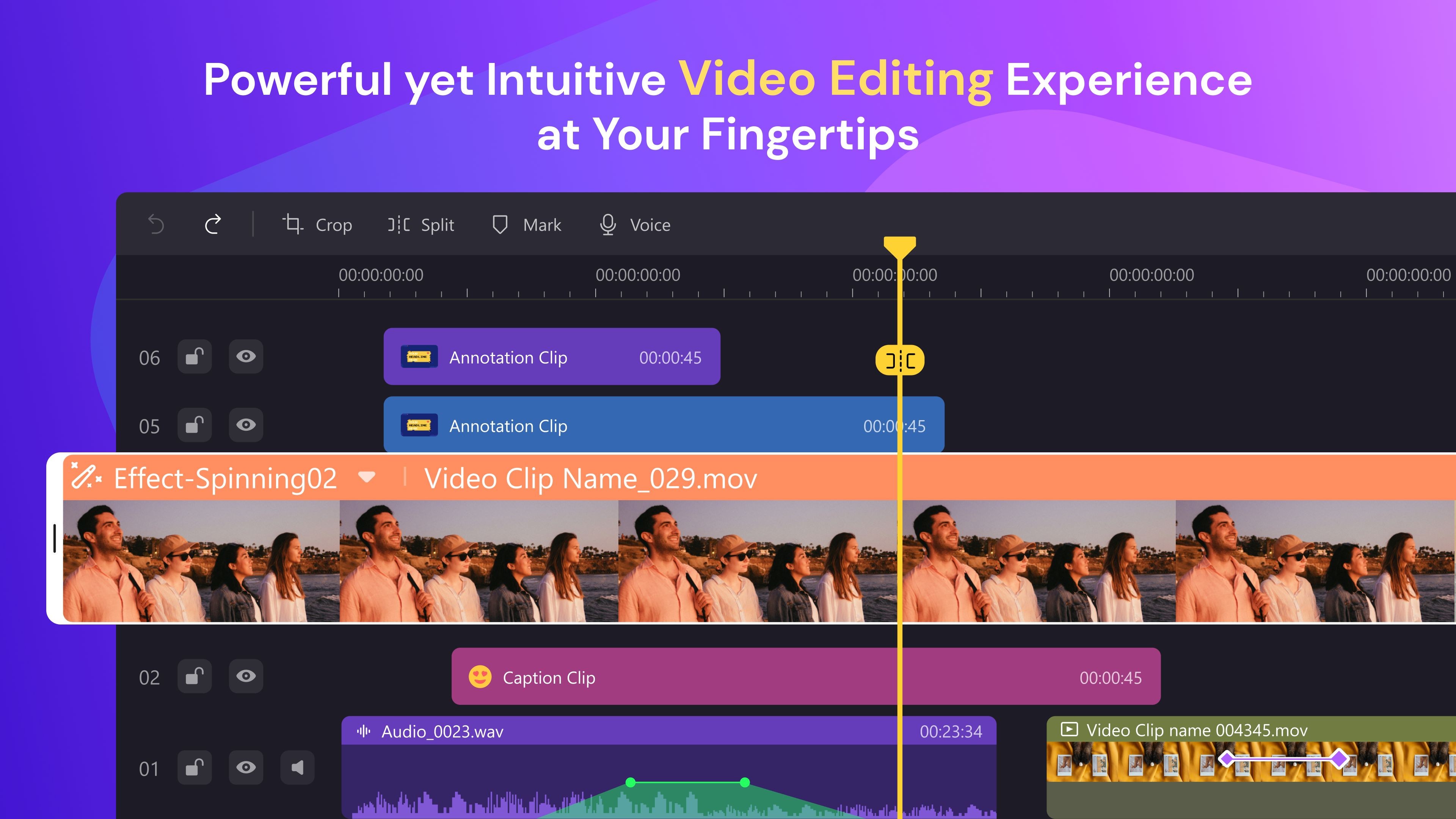
DemoCreator 一款适用于教育工作者、视频会议演示者、企业主和游戏玩家的屏幕录像机和视频编辑器,DemoCreator是制作演示视频和解说视频的一站式解决方案。 视频剪辑 2025年06月05日 60 点赞 0 评论 843 浏览