SPAR3D SPAR3D是一种基于两阶段设计的单图像3D重建工具,能从单张2D图像生成高质量的3D网格。它结合点扩散模型与三平面Transformer技术,实现快速、精确的几何与纹理重建,并支持用户交互式编辑。适用于增强现实、影视制作、工业设计等多个领域。 AI项目与工具 2025年06月12日 86 点赞 0 评论 801 浏览
淘宝星辰 淘宝星辰是阿里妈妈推出的电商视频生成大模型,支持图片或文本指令生成高质量视频。具备智能商品展示、多语种语义理解、物理动作逻辑遵循及元素稳定性保障等功能,适用于商品主图、卖点展示、种草内容及虚拟试穿等场景,有效提升商品吸引力和转化效率。 AI项目与工具 2025年06月12日 73 点赞 0 评论 802 浏览
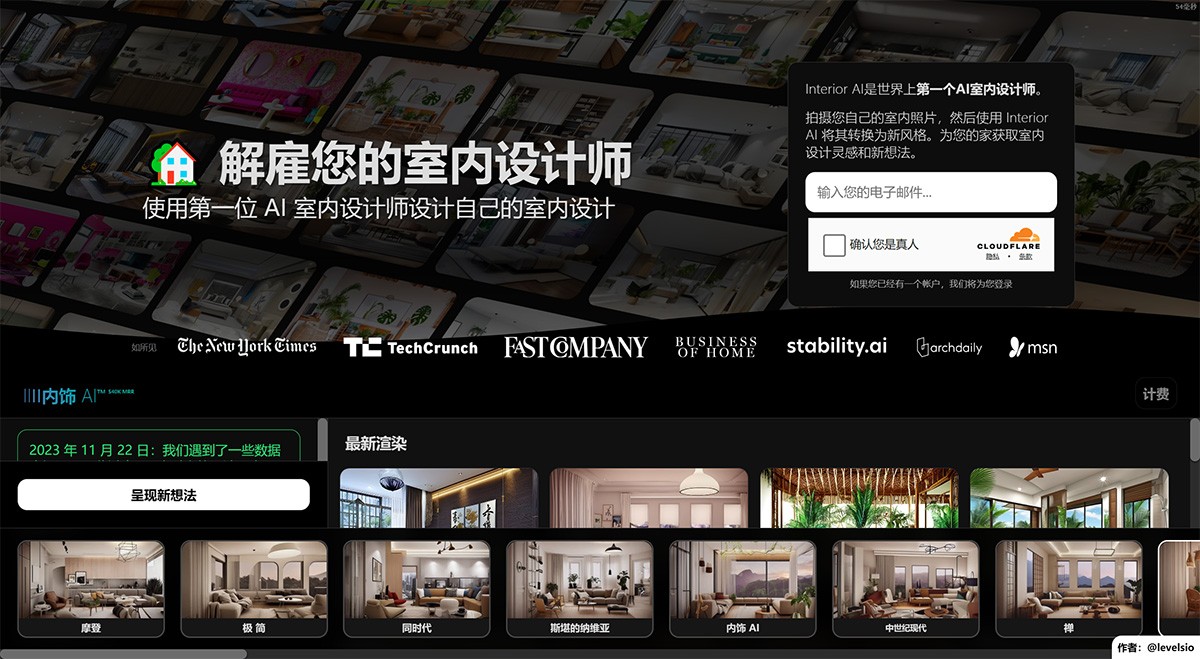
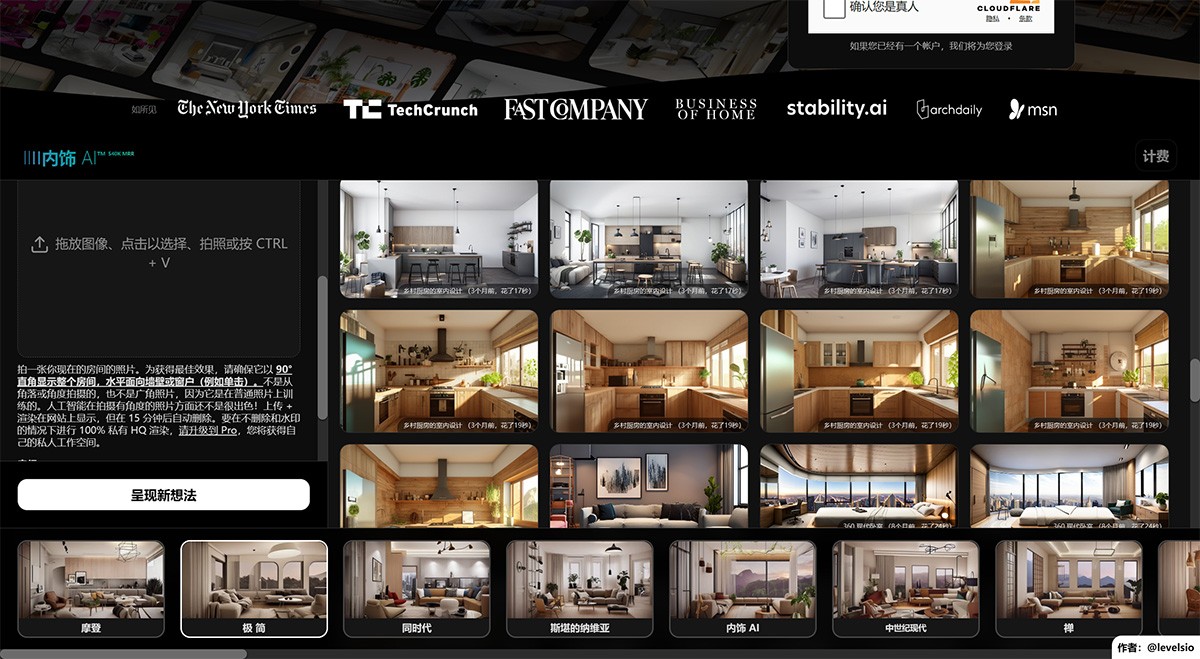
InteriorAI 世界上第一家人工智能室内设计师。它允许用户拍照并利用人工智能将其室内照片转换为新风格。它为家居装饰提供室内设计灵感和新创意。 图片处理 2025年06月05日 95 点赞 0 评论 805 浏览
Wonder Dynamics Wonder Dynamics的Wonder Studio是一个创新的AI工具,它通过自动化大部分VFX工作,极大地简化了视觉效果的创作过程。 Ai视频生成 2026年06月21日 0 点赞 0 评论 805 浏览
LBM LBM(Latent Bridge Matching)是一种基于潜在空间桥接匹配的图像到图像转换框架,支持目标移除、图像重光照、深度图生成等多种任务。通过布朗桥和随机微分方程实现高效且多样化的图像转换,具备良好的可控性和视觉一致性。适用于摄影、设计、3D建模等多个领域,具有广泛的应用前景。 AI项目与工具 2025年06月11日 40 点赞 0 评论 808 浏览
新壹视频大模型 新壹视频大模型是一款AI驱动的视频创作平台,具备自动生成剧本、情感化语音合成、3D元素生成和高清视频输出等功能。该平台通过集成自主研发的AI算法和深度学习技术,简化了视频创作流程,提高了制作效率,降低了成本,同时提升了视频的整体质量和用户体验。其应用场景广泛,涵盖教育、医疗、文化旅游、金融管理和广电传媒等多个领域。 AI项目与工具 2025年06月12日 69 点赞 0 评论 812 浏览
MotionFix MotionFix是一个开源的3D人体动作编辑工具,采用自然语言描述与条件扩散模型TMED相结合的方式,支持通过文本指令精准编辑3D人体动作。其主要功能包括文本驱动的动作编辑、半自动数据集构建、多模态输入处理及基于检索的评估指标。MotionFix适用于动画制作、游戏开发、虚拟现实等多个领域,为动作编辑提供了灵活性与精确性。 AI项目与工具 2025年06月12日 13 点赞 0 评论 812 浏览
Signs Signs是由英伟达推出的AI手语学习平台,通过实时手势识别与3D虚拟教学,帮助用户精准掌握美式手语。平台支持用户上传视频,丰富学习资源,具备互动性与个性化反馈,适用于初学者及进阶学习者,同时为无障碍技术开发提供数据支持。 AI项目与工具 2025年06月12日 69 点赞 0 评论 812 浏览
Genmo Genmo是一个创造和分享交互式、沉浸式生成艺术的平台。通过创建视频、3D场景、动画、矢量设计资产等,超越Genmo上的2D图像。 Ai视频生成 2026年06月21日 0 点赞 0 评论 812 浏览