Pantheon AI Pantheon AI是一款基于AI技术的建筑设计平台,专注于简化建筑设计流程,从初步设计到施工文档生成均实现智能化操作。平台的核心功能包括快速生成可编辑的3D模型、自动化处理重复性任务、确保设计合规性、支持快速迭代以及提供实时成本估算。适用于办公楼、多户型住宅、酒店建设及建筑翻新等多个场景,助力用户高效完成建筑项目。 AI项目与工具 2025年06月12日 94 点赞 0 评论 618 浏览
AnyPaint AnyPaint是一款集成了文本到图像、图像编辑及3D模型生成等功能的AI图像生成工具,支持多种创作需求。其主要功能包括绘画生成、一键AI操作、模型库管理、IP-Adapter插件应用等,能够满足不同用户的创作需求,同时提供本地化工具提升创作效率。 AI项目与工具 2025年06月12日 81 点赞 0 评论 616 浏览
Explorer Explorer是一款由Odyssey公司研发的生成性世界模型,主要功能包括将图像转换为高质量的3D场景,并支持动态效果生成。它利用高斯溅射技术和先进的图像识别算法,实现逼真的视觉效果。Explorer生成的场景可无缝集成到主流创作软件中,广泛应用于电影、游戏开发、虚拟现实等领域,显著提升内容创作效率。 AI项目与工具 2025年06月12日 39 点赞 0 评论 614 浏览
photosonic AI Photosonic 智能AI绘画生成器,只需要短短几秒钟就可以根据用户文字描述生成一副艺术画,完全不需要画画基础,只凭借你的脑海里面的想象用文字描述出来,通过 Photosonic 智能 AI 技术就可以创作出来, Ai绘画生成 2025年06月05日 25 点赞 0 评论 614 浏览
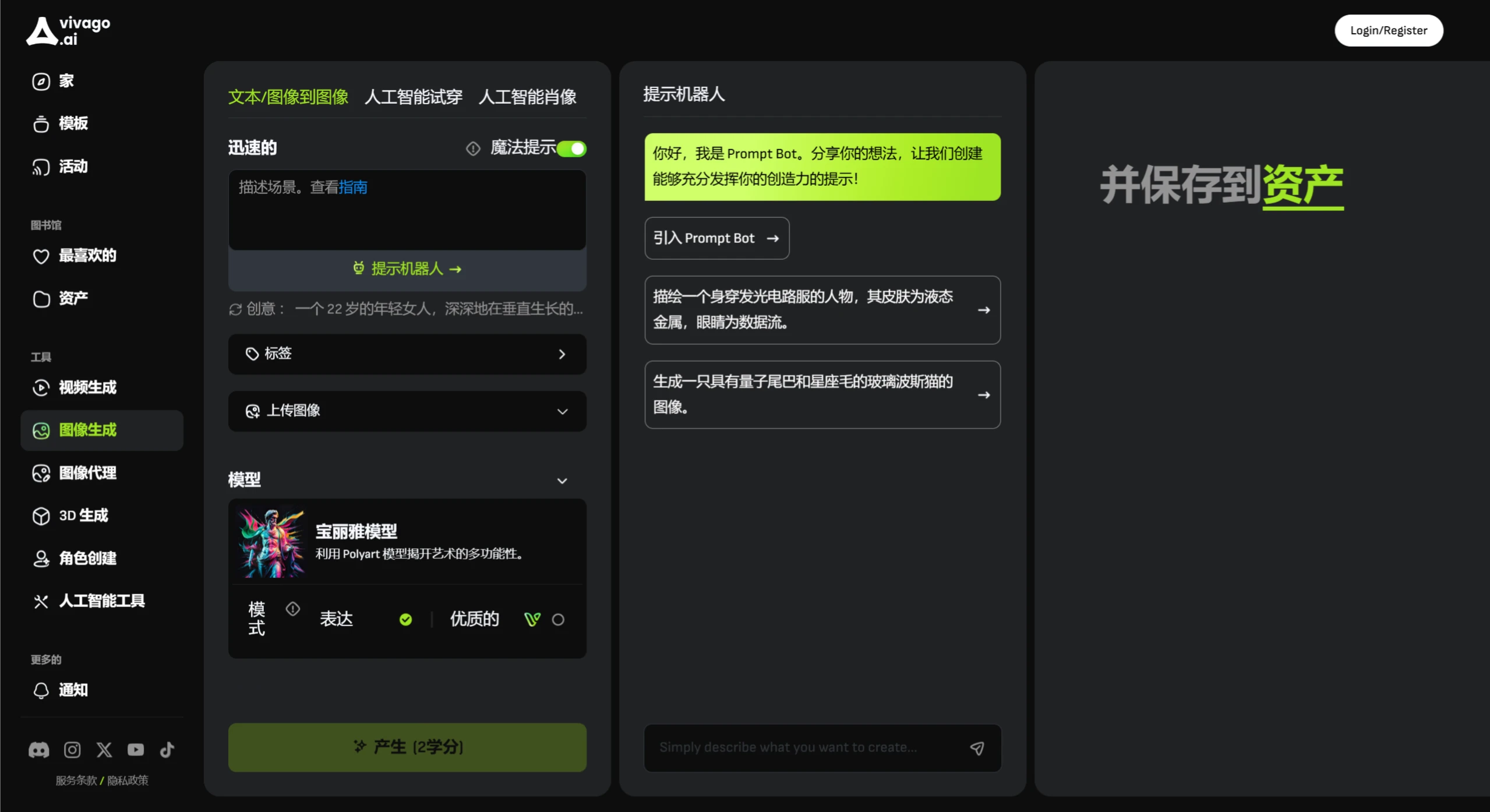
Vivago AI 北京智象未来科技有限公司面向全球市场推出的一款综合性在线 AI 创作平台,提供视频生成、图片生成、图片agent编辑,数字人生成,3D模型等功能。 Ai绘画生成 2025年06月05日 12 点赞 0 评论 614 浏览
PersonaCraft PersonaCraft是一种结合扩散模型和3D人体建模的全身图像合成技术,能够从单一参考图像生成多个逼真的个性化全身图像。它支持遮挡处理、用户自定义身体形状,并通过3D感知姿态条件控制提高生成图像的质量。该工具广泛应用于社交媒体、广告、时尚、游戏及电影等领域,为个性化定制提供了强大的技术支持。 AI项目与工具 2025年06月12日 23 点赞 0 评论 610 浏览
Live3D Live3D是一款面向虚拟主播(VTuber)的综合工具套件,提供面部追踪、3D形象定制、动画制作及直播互动等功能。其包含VTuber Maker、Editor、Gallery等组件,支持手部追踪、VRM模型编辑及AI动作捕捉,适用于虚拟直播、内容创作、在线教育等多种场景。该工具具备丰富的资源库和持续更新机制,适合个人与专业创作者使用。 AI项目与工具 2025年06月12日 13 点赞 0 评论 608 浏览
DUSt3R DUSt3R是一个由芬兰阿尔托大学和Naver欧洲实验室联合研发的3D重建框架。该框架能够快速地从任意图像集合中重建出三维场景,无需事先了解相机校准或视点位置信息。DUSt3R主要功能包括快速3D重建、无需相机校准、多视图立体重建、单目和双目重建以及生成深度图、置信度图和点云图。它采用了点图表示法、Transformer网络架构和端到端训练方式,并提出了全局对齐策略来处理多视图重建任务。 AI项目与工具 2024年01月01日 53 点赞 0 评论 608 浏览