Podcastfy Podcastfy 是一款基于生成式人工智能技术开发的开源工具,可将网络文章、PDF 文件及纯文本转化为多语言对话式音频。它不仅支持多源文本合并,还具备强大的文本转语音功能,允许用户选择不同的语音模型来优化音频效果。此外,其开源特性便于开发者根据需求进行个性化定制,广泛适用于内容摘要、语言本地化、教育材料转化等多个领域。 AI项目与工具 2025年06月12日 18 点赞 0 评论 790 浏览
Duck.ai Duck.ai 是一款由 DuckDuckGo 提供的隐私保护型 AI 聊天工具,支持多模型切换并提供匿名访问。用户无需注册即可使用,聊天内容不被用于模型训练,同时支持本地存储对话历史,提升使用便捷性与数据安全性。 AI项目与工具 2025年06月12日 38 点赞 0 评论 790 浏览
OWL OWL是一款基于CAMEL-AI框架的多智能体协作系统,支持任务自动化、角色分配与动态交互。其核心功能包括任务分解、记忆模块、灵活部署及大模型驱动的智能体架构。适用于知识工作、智能交通、医疗健康、电商推荐和环境监测等多个场景,提升任务执行效率与智能化水平。 AI项目与工具 2025年06月12日 83 点赞 0 评论 790 浏览
Diffutoon Diffutoon是一款基于扩散模型的AI框架,旨在将现实风格的视频转换为动漫风格。该框架支持高分辨率视频处理,能够实现风格化、一致性增强、结构引导和自动着色等功能。此外,Diffutoon具备内容编辑功能,用户可通过文本提示调整视频细节,确保视觉效果和内容的一致性。 AI项目与工具 2025年06月12日 45 点赞 0 评论 790 浏览
AVD2 AVD2是由多所高校联合开发的自动驾驶事故视频理解框架,通过生成高质量事故视频并结合自然语言描述与推理,提升对复杂事故场景的理解能力。其功能涵盖事故视频生成、原因分析、预防建议及数据集增强,支持自动驾驶系统的安全优化与研究。基于先进模型如Open-Sora 1.2和ADAPT,AVD2在多项评估中表现优异,为自动驾驶安全提供了重要技术支撑。 AI项目与工具 2025年06月12日 62 点赞 0 评论 790 浏览
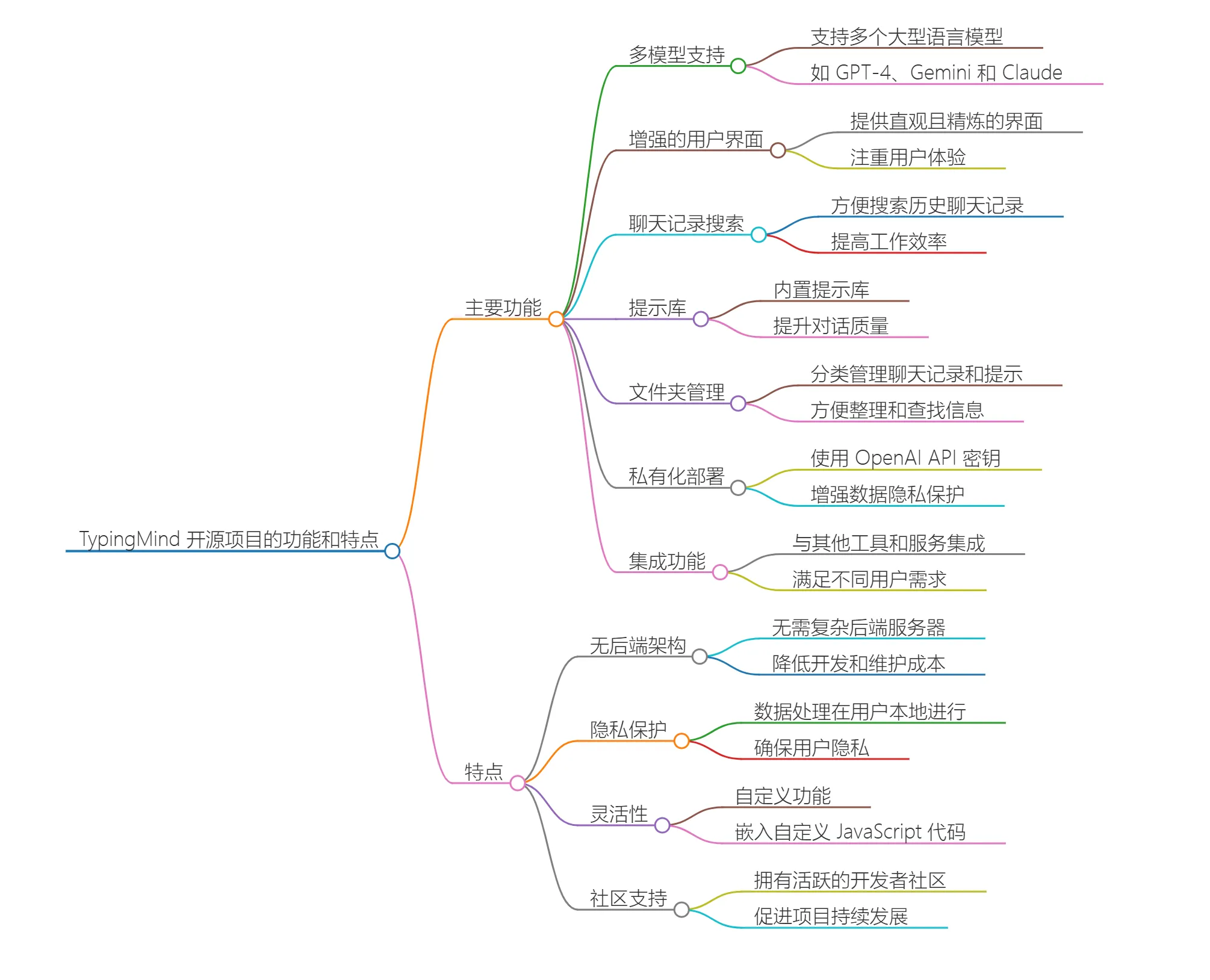
TypingMind 一款支持多种大型语言模型的聊天界面应用,用户可以通过API密钥与ChatGPT、Claude、Gemini等模型进行互动。 AI写作对话 2025年06月05日 28 点赞 0 评论 790 浏览