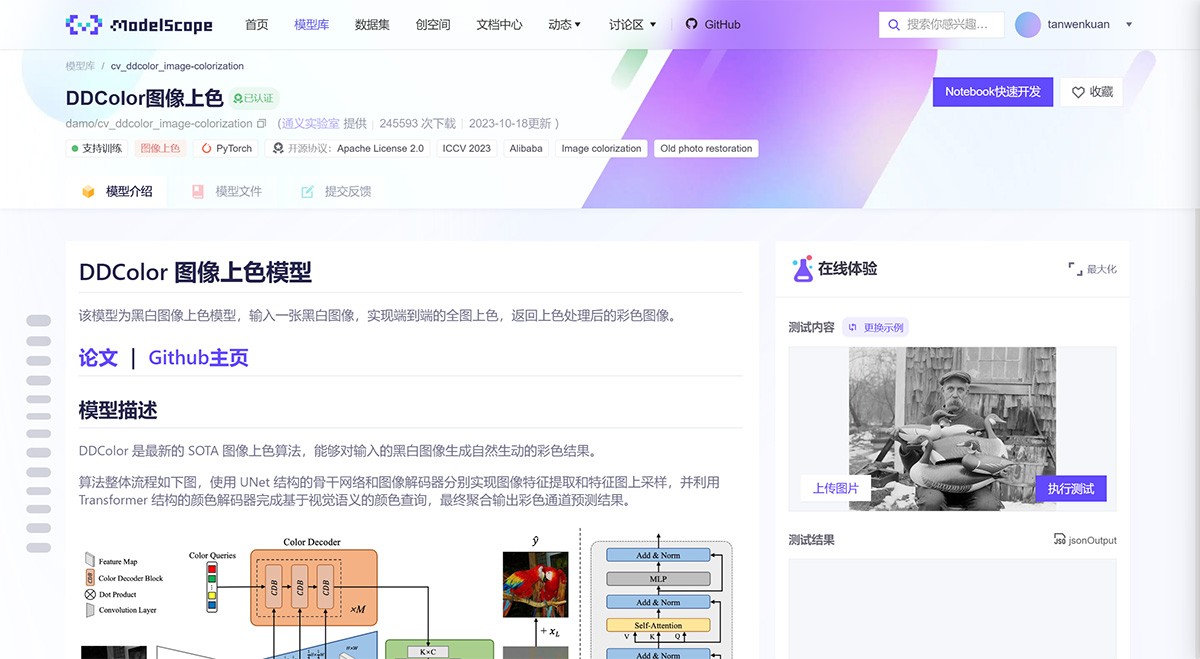
R



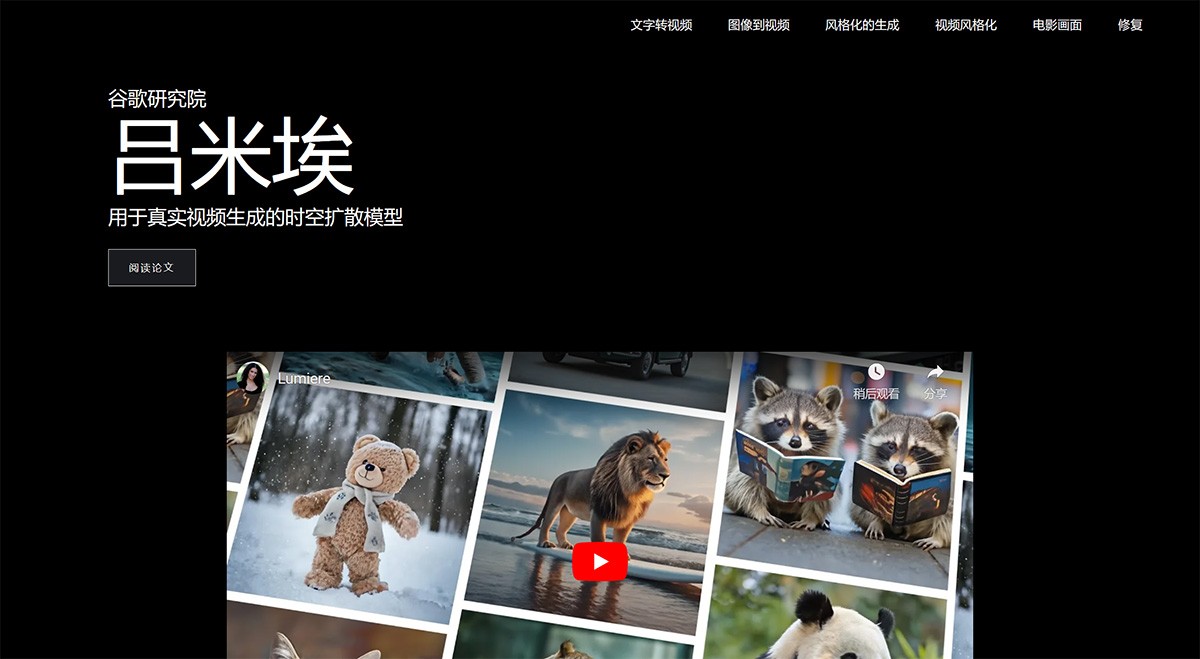
VideoDrafter
一个高质量视频生成的开放式扩散模型,相比之前的生成视频模型,VideoDrafter最大的特点是能在主体不变的基础上,一次性生成多个场景的视频。
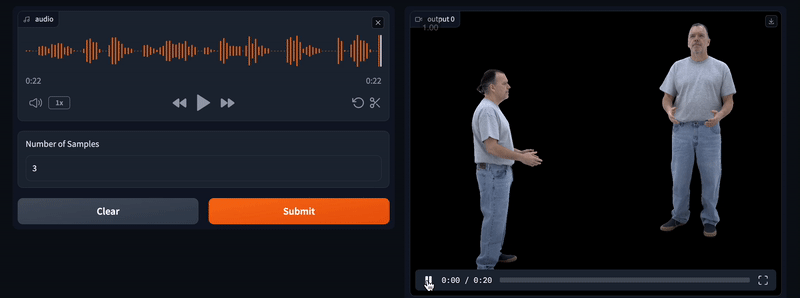

Chatbot UI
一个开源的聊天机器人Web UI框架,Chatbot UI提供 OpenAI 的 ChatGPT UI 的改进版本。提供了一个简单的用户界面,具有新对话、新聊天、导入数据、导出数据、设置和插件键等功能。