DynamicFace DynamicFace是由小红书团队开发的视频换脸技术,结合扩散模型与时间注意力机制,基于3D面部先验知识实现高质量、一致性的换脸效果。通过四种精细的面部条件分解和身份注入模块,确保换脸后的人脸在不同表情和姿态下保持一致性。该技术适用于视频与图像换脸,广泛应用于影视制作、虚拟现实、社交媒体等内容创作领域,具备高分辨率生成能力和良好的时间连贯性。 AI项目与工具 2025年06月12日 84 点赞 0 评论 533 浏览
FramePainter FramePainter 是一款基于AI的交互式图像编辑工具,结合视频扩散模型与草图控制技术,支持用户通过简单操作实现精准图像修改。其核心优势包括高效训练机制、强泛化能力及高质量输出。适用于概念艺术、产品展示、社交媒体内容创作等场景,具备低训练成本和自然的图像变换能力。 AI项目与工具 2025年06月12日 70 点赞 0 评论 533 浏览
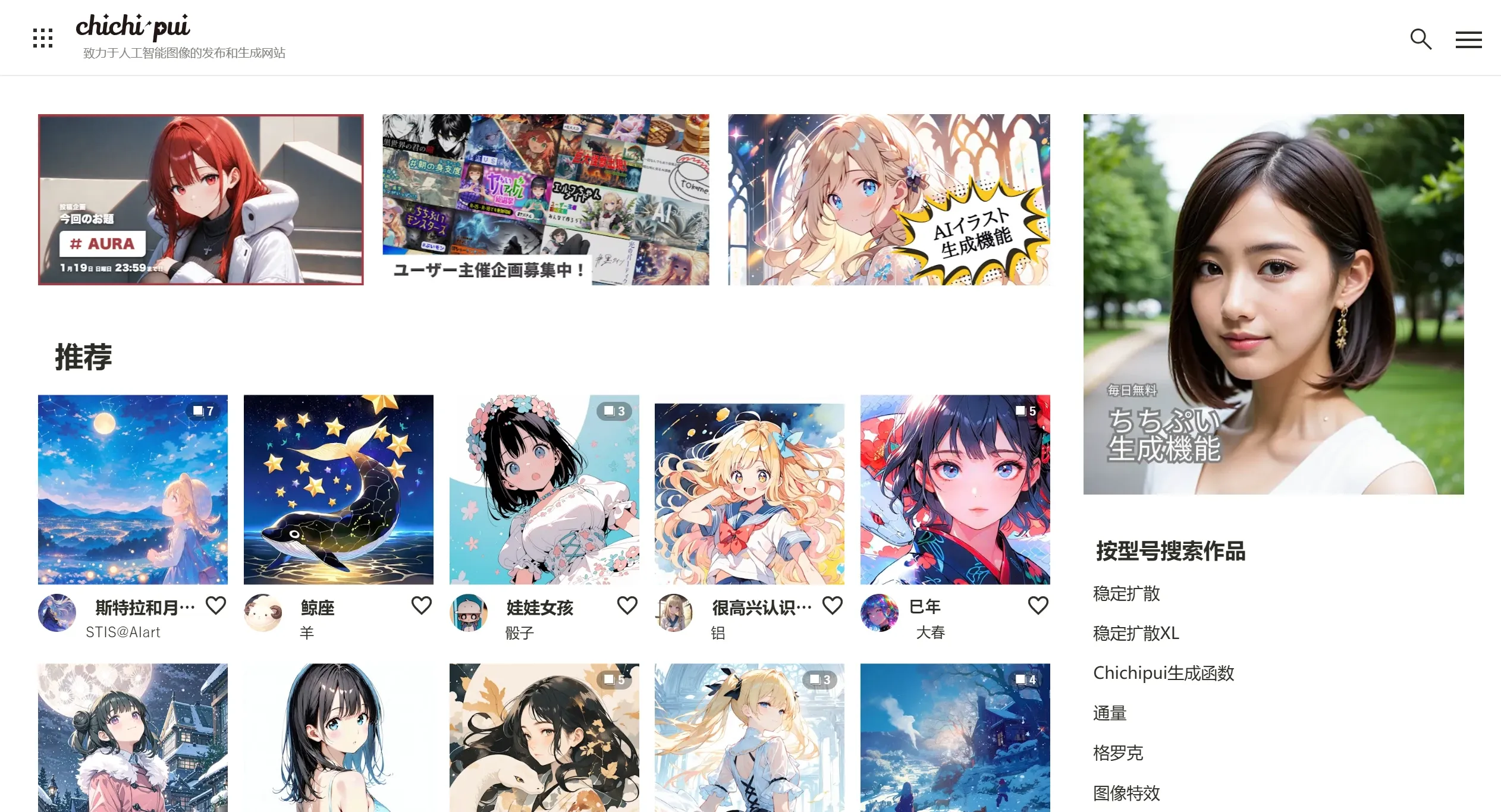
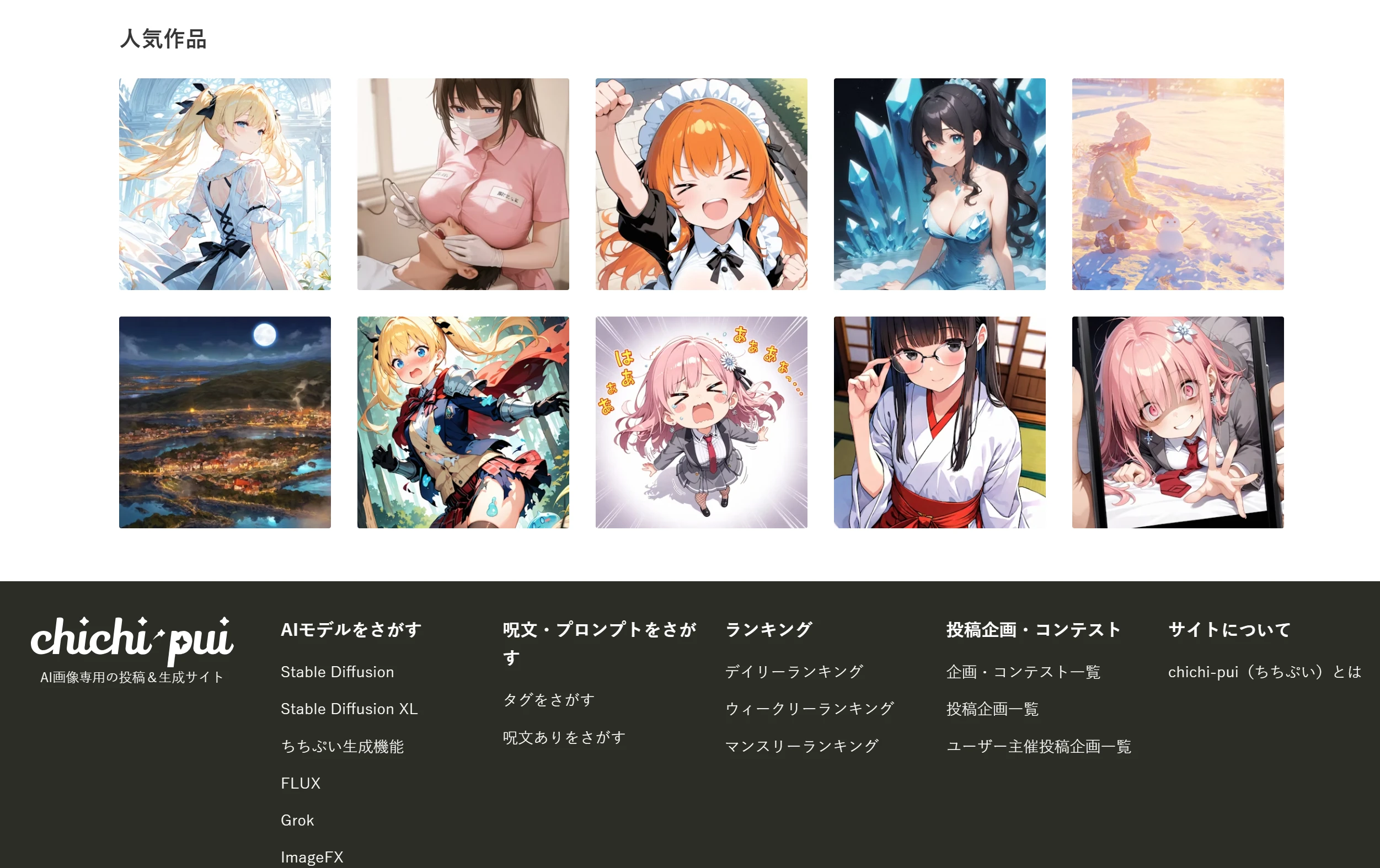
Chichi 一个专注于AI生成图像的日本网站,只要针对动漫爱好者、数字艺术家和影像设计师群体,生成动漫风格的插图、写实照片以及日本流行的写真风格。 Ai绘画生成 2025年06月05日 55 点赞 0 评论 534 浏览
Auto Think Auto Think是快手Kwaipilot团队开源的KwaiCoder-AutoThink-preview自动思考大模型,针对深度思考大模型的“过度思考”问题,提出了一种全新的训练范式。模型融合“思考”和“非思考”能力,能根据问题难度自动切换模式,提升复杂任务表现。在代码和数学类任务中,性能提升可达20分。其技术原理包括最小提示干预和多阶段强化学习,适用于视频生成、文案创作、智能客服等多个场景。 AI项目与工具 2025年06月11日 26 点赞 0 评论 534 浏览
原子回声AtomGPT大模型 原子回声AtomGPT大模型是一个不断学习和进步的中文大模型项目,它通过向用户展示模型的学习过程,提供了一个参与和观察模型成长的平台。 创作工具 2026年06月22日 0 点赞 0 评论 535 浏览
AI方程式 AI方程式,文本到图像生成AI模型提示语分享平台,无论您是寻找创意灵感、个性化设计还是艺术创作的工具,AI方程式将成为您的创意合伙人。 Ai提示指令 2025年06月05日 79 点赞 0 评论 535 浏览
PUMA PUMA是一款先进的多模态大型语言模型,专注于通过整合多粒度视觉特征提升视觉生成与理解能力。它支持文本到图像生成、图像编辑、条件图像生成及多粒度视觉解码等功能,适用于艺术创作、媒体娱乐、广告营销等多个领域,凭借其强大的多模态预训练和微调技术,成为多模态AI领域的前沿探索。 AI项目与工具 2025年06月12日 72 点赞 0 评论 535 浏览
Skywork o1 Skywork o1是一款具备中文逻辑推理能力的大规模预训练模型,其核心优势在于内嵌思考、规划和反思能力,显著提升了复杂任务的推理性能。该模型基于开源Llama架构,同时提供增强版以满足更高要求的应用场景。它适用于技术开发者、企业决策者、教育工作者、内容创作者及客户服务等多个领域,助力创新应用开发和高效决策支持。 --- AI项目与工具 2025年06月12日 73 点赞 0 评论 535 浏览
CoA CoA是由谷歌开发的多智能体协作框架,用于解决大语言模型在处理长文本任务时的上下文限制问题。它将长文本分割成多个片段,由多个智能体依次处理并通过链式通信传递关键信息,最终由管理智能体整合生成结果。该框架无需额外训练,支持多种任务类型,如问答、摘要和代码补全,且具有高效性和可扩展性。其时间复杂度优化显著提升了处理长文本的效率。 AI项目与工具 2025年06月12日 57 点赞 0 评论 535 浏览
VideoCrafter2 VideoCrafter2 是一款由腾讯AI实验室开发的视频生成模型,通过将视频生成过程分解为运动和外观两个部分,能够在缺乏高质量视频数据的情况下,利用低质量视频保持运动的一致性,同时使用高质量图像提升视觉质量。该工具支持文本到视频的转换,生成高质量、具有美学效果的视频,能够理解和组合复杂的概念,并模拟不同的艺术风格。 AI项目与工具 2024年01月01日 49 点赞 0 评论 535 浏览